Cyber Threat Intelligence - OpenCTI

@_euzebius |Nummmber One Mentor !| |- |Jean-Pierre LESUEUR
@darkcodersc |-| |Samedi 18 Juin 2022 |Mudsor MASOOD
mudpak |Mise à jour vers blog (v1.0.1)| |Samedi 19 Février 2022 |Julien RICHARD
@richardjulien |Co-fondateur de OpenCTI et Relecture (v0.0.6)| |Mercredi 16 Février 2022 |Philippe SEGRET
Pich |Finalisation du document (v0.0.5)| |Lundi 14 Février 2022 |mudpak |Ajout de la partie OpenCTI (v0.0.4)| |Samedi 15 Janvier 2022 |mudpak |Ajout de la partie OpenCTI (v0.0.4)| |Mercredi 5 Janvier 2022 |mudpak |Ajout de la partie docker (v0.0.3)| |Mardi 23 Novembre 2021 |Hamza KONDAH
@kondah_ha |Aide Technique et Webinaire (v0.0.2)| |Dimanche 31 Octobre 2021 |mudpak |Création du document (v0.0.1)|



0. Avant-propos
Ce document a pour but de guider l’utilisateur dans la présentation, mise en place et personnalisation de la plateforme OpenCTI.
Nous allons voir en détails comment alimenter la plateforme en données CTI via les différents connecteurs.
Le monde de la CTI étant une de mes passions, j’ai eu l’occasion de tester différentes plateformes, mais je dois admettre que depuis que j’ai découvert OpenCTI je suis totalement conquis !
C’est pourquoi je ne vais pas non seulement parler de la solution mais également de tout l’environnement qui la concerne (fondateurs, site web, communauté …).
Bien que ce document soit assez complet, il est important de noter qu’il n’a pas vocation à remplacer à la documentation officielle de l’outil, qui est tenue à jour très régulièrement !
Tout au long document je vais évoquer l’utilisation de connecteurs externes pour enrichir la plateforme, mais il faut garder en tête que c’est votre plateforme, et que les informations qui l’enrichissent peut très bien provenir de vos services ainsi il vous est tout à fait possible d’ajouter des éléments propres à votre contexte pour venir enrichir la plateforme en plus des données récoltées par les sources externes (prestataires, communautés CTI …).
1. Prérequis
Il faut
-
Avoir accès à internet : pour télécharger, installer les mises à jour, les paquets nécessaires pour la solution
-
Avoir une machine avec les droits root ou suffisants pour installer des programmes : dans la suite un serveur Ubuntu 20.04 LTS est utilisé
-
Se conformer à la configuration requise pour la solution OpenCTI : les prérequis sont détaillés par la suite
-
Avoir une adresse email valide pour créer les comptes sur les plateformes
- Vous devez avoir accès à cette messagerie pour confirmer votre compte
- Ici il est question de validation de votre compte sur les plateformes où vous allez vous inscrire pour récupérer la clé API pour alimenter OpenCTI en données et non de la création du compte sur votre instance locale
-
Avoir suffisamment d’espace disque pour les données qui seront stockées à travers le temps
Remarques :
La mise en place de certains prérequis est détaillée par la suite pour avoir un résultat le plus proche à celui du document.
Le but est d’obtenir une CTI fonctionnelle, de nombreuses « mauvaises pratiques » sont appliquées lors de la mise en place et elles sont précisées.
Les « bonnes pratiques » sont indiquées pour ne pas faire les mêmes erreurs.
2. OpenCTI – Présentation de la plateforme
OpenCTI permet la gestion et partage de connaissances et est Open-Source.
Pour avoir une présentation plus complète je vous invite à consulter les ressources suivantes :
- https://www.opencti.io/fr/
- https://www.ssi.gouv.fr/actualite/opencti-la-solution-libre-pour-traiter-et-partager-laconnaissance-de-la-cybermenace/
- https://github.com/OpenCTI-Platform/opencti
2.1 Fondateurs
OpenCTI a été fondé par les entités suivantes
- ANSSI : Agence Nationale de la Sécurité des Système d’Information
- CERT-EU : Computer Emergency Response Team
Et principalement par les personnes suivantes qui sont co-fondateurs de l’initiative Luatix.
- Samuel HASSINE
- Julien RICHARD
OpenCTI est membre de l’initiative Luatix, à cet instant voici les produits crées par cette initiative :

2.2 Site Officiel
Nous allons voir le site de OpenCTI rapidement, les ressources présentes dessus vont nous être utiles par la suite.
Le site officiel se trouve à l’adresse suivante :
2.2.1 Télécharger
En cliquant sur « TELECHARGER » vous êtes redirigés vers la page GitHub :
2.2.2 Démonstration
En cliquant sur « DEMONSTRATION » vous pouvez visualiser une démonstration live de la solution avant sa mise en place.

Pour visualiser la démo vous pouvez utiliser un compte existant
- GitHub
Ou créer un compte via une adresse email :
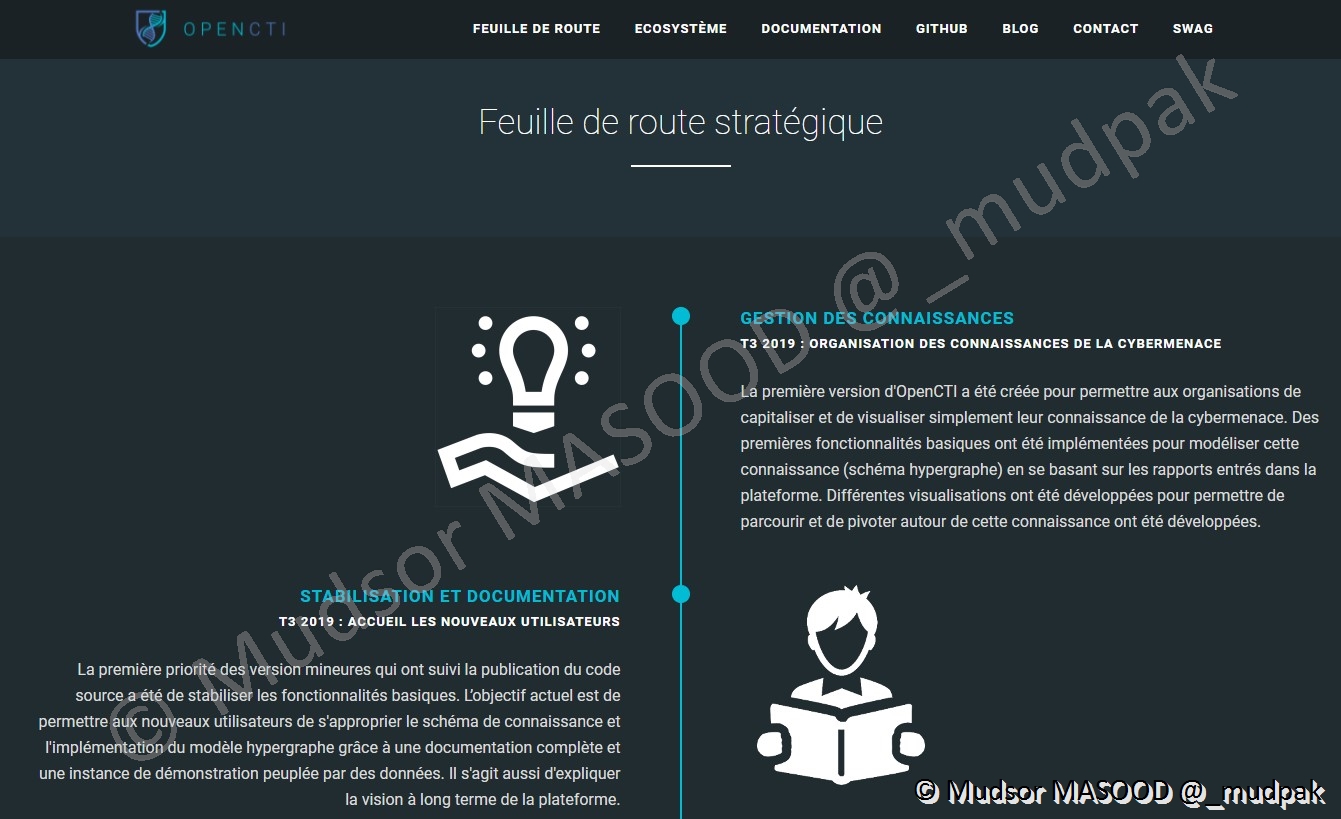
2.2.3 Feuille de route / Roadmap
Cette page permet de consulter les évolutions à venir sur la plateforme :
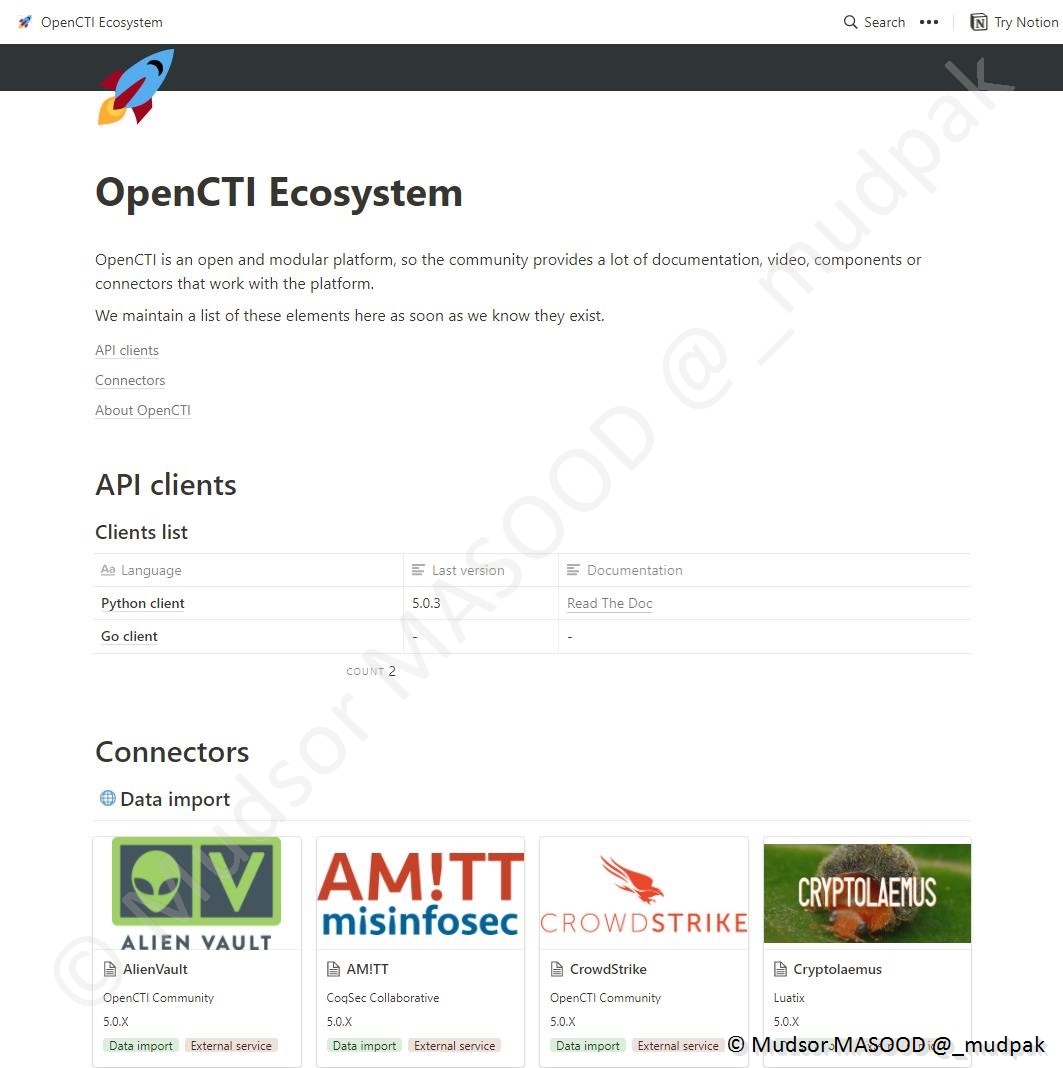
2.2.4 Ecosystème
Cette page recense les informations sur l’API, les connecteurs, les méthodes d’enrichissement de la plateforme, les modules d’importations et les modules tiers.
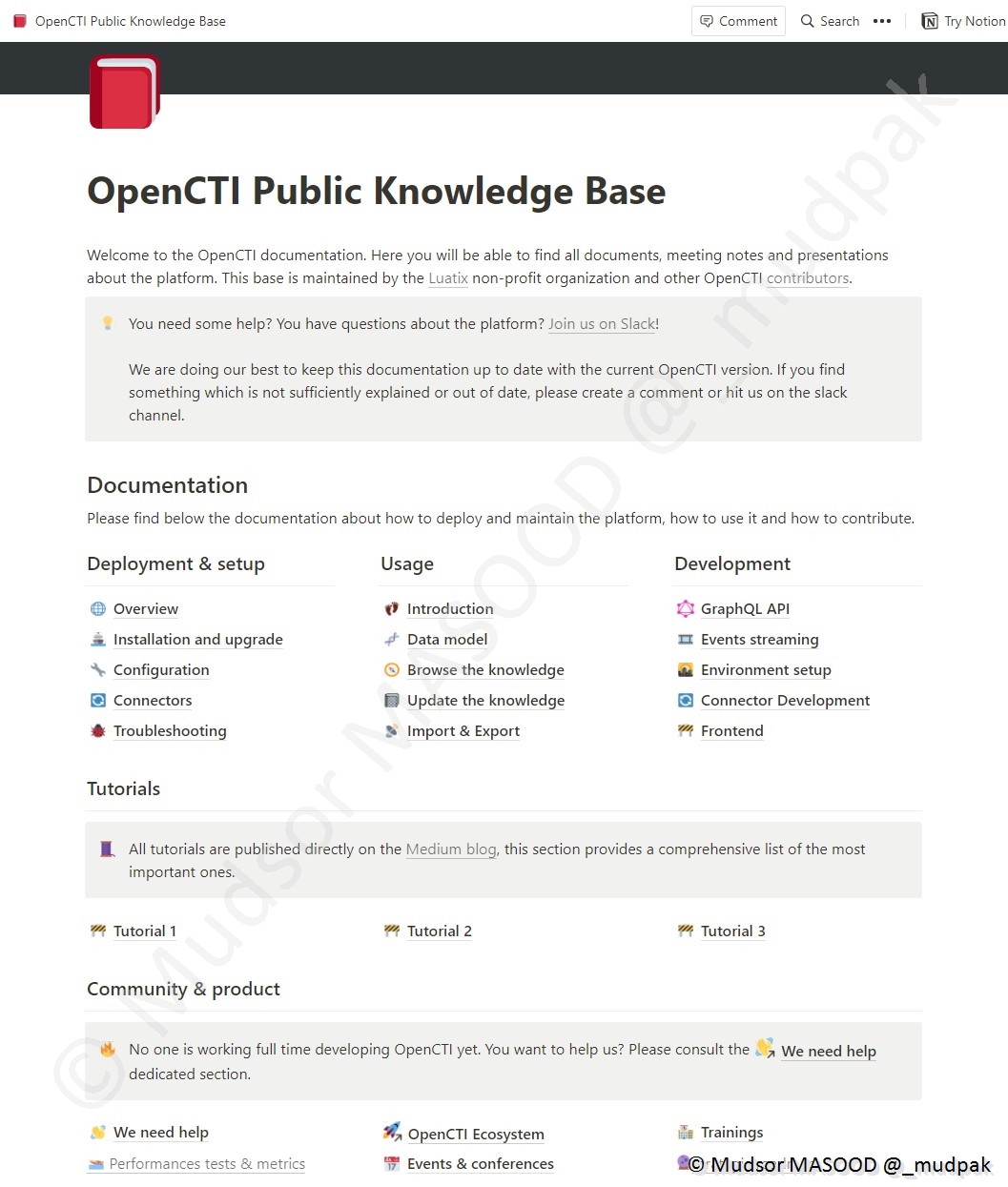
2.2.5 Documentation
Cette page recense la documentation et informations nécessaires sur la plateforme :
2.2.6 GitHub
La page GitHub du projet est la suivante :
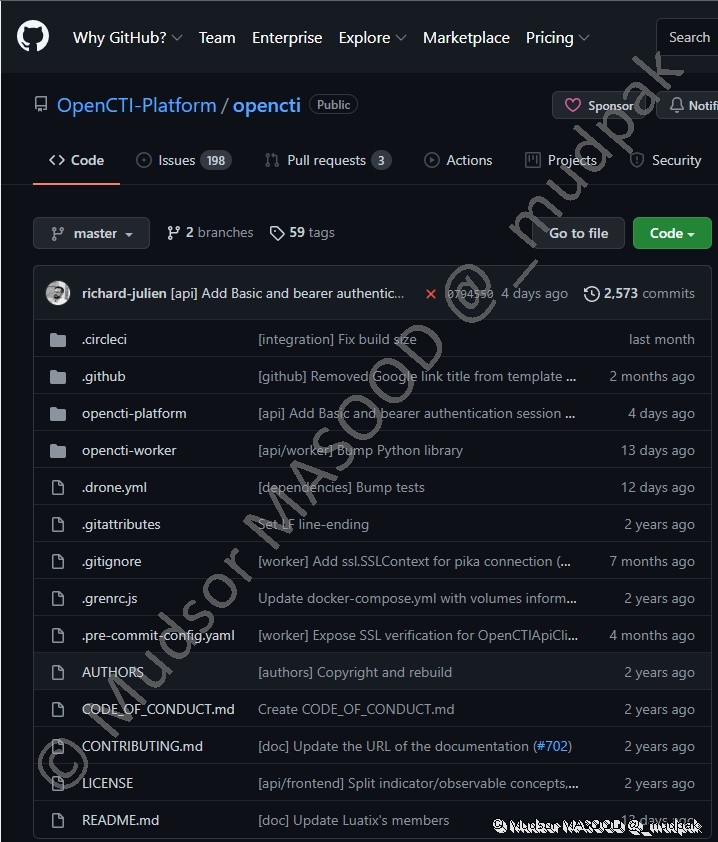
D’autres répertoires du même projet nous serons utiles par la suite :
2.2.7 Blog
Des articles intéressants sont disponibles sur le blog :
2.2.8 Contact
Si vous souhaitez contacter les membres du site vous pouvez soit les contacter via Slack ou soit remplir le formulaire :
2.2.9 Swag
Si vous souhaitez acheter des goodies OpenCTI, vous pouvez les commander à cet endroit :
3. Ubuntu Server
3.1 Installation
Nous allons détailler le processus d’installation du système d’exploitation.
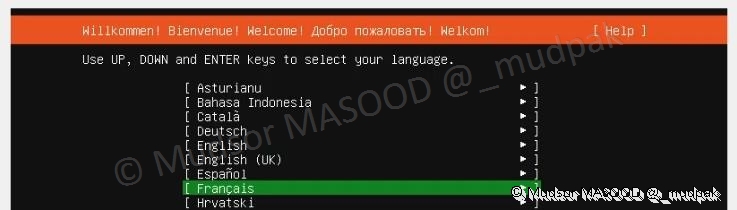
3.1.1 Willkomen ! Bienvenue ! Welcome !
Sélectionner la langue d’installation désirée et appuyer sur la touche « Entrée », dans le cas présent nous avons choisi la langue Française :
- Français
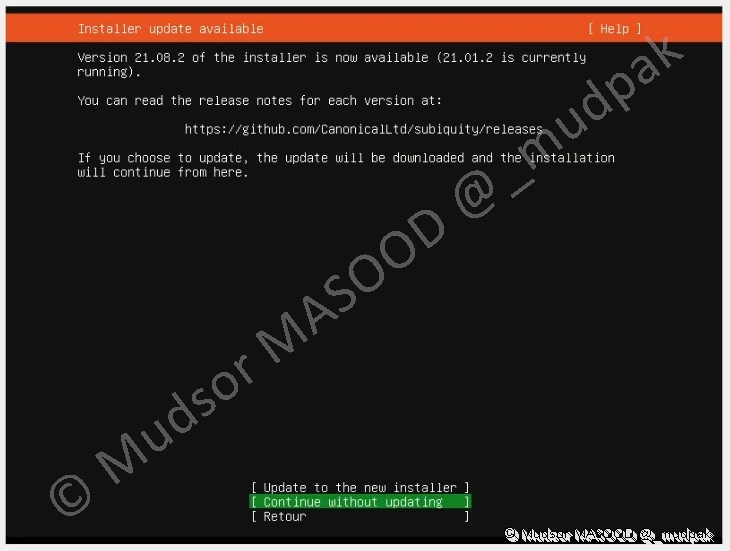
3.1.2 Mise à jour de l’installateur
Selon la version de votre ISO il se peut que l’installateur ne soit pas le plus récent, il vous est possible de choisir un plus récent ou l’ignorer, dans notre cas nous allons ignorer, sélectionner :
- Continue without updating
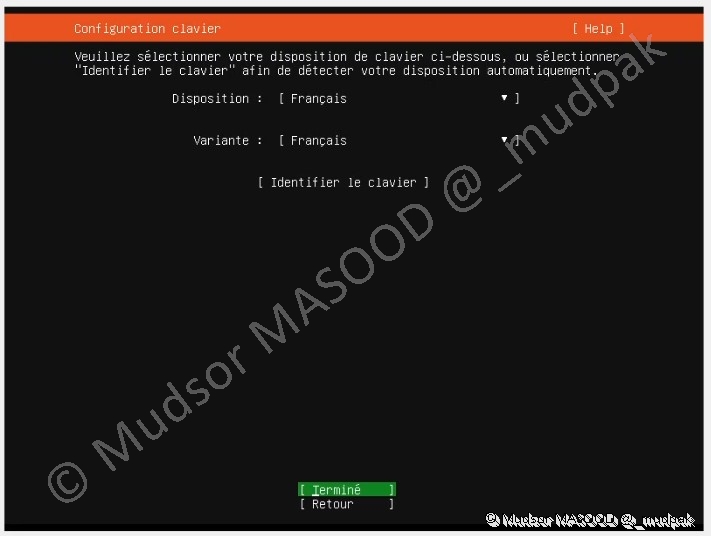
3.1.3 Configuration clavier
Normalement selon la langue choisie votre clavier devrait être sélectionner, sinon vous pouvez choisir le clavier souhaité en sélectionnant et parcourant les paramètres :
- Dispositon
- Variante
Lorsque vous avez terminé sélectionner :
- Terminé
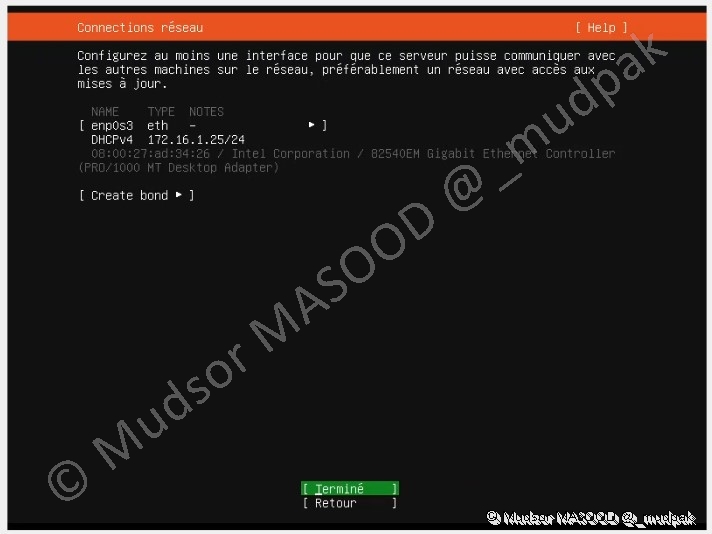
3.1.4 Connexions réseau
Par défaut la carte réseau est détectée et une configuration réseau est distribuée par votre serveur DHCP, si vous souhaitez avoir une configuration statique c’est à ce niveau-là que vous pouvez modifier ce paramètre.
Lorsque la configuration vous convient, sélectionner :
- Terminé
3.1.5 Configurer le proxy
Si vous utilisez un proxy pour vous connecter à internet vous pouvez le spécifier à cet endroit et sélectionner :
- Terminé
3.1.6 Configuration du serveur miroir
Pour ce qui va être des mises à jours et installation des paquets si vous souhaitez les récupérer depuis des serveurs spécifiques vous pouvez indiquer à cette étape le serveur de récupération ou laisser le paramètre par défaut et sélectionner :
- Terminé
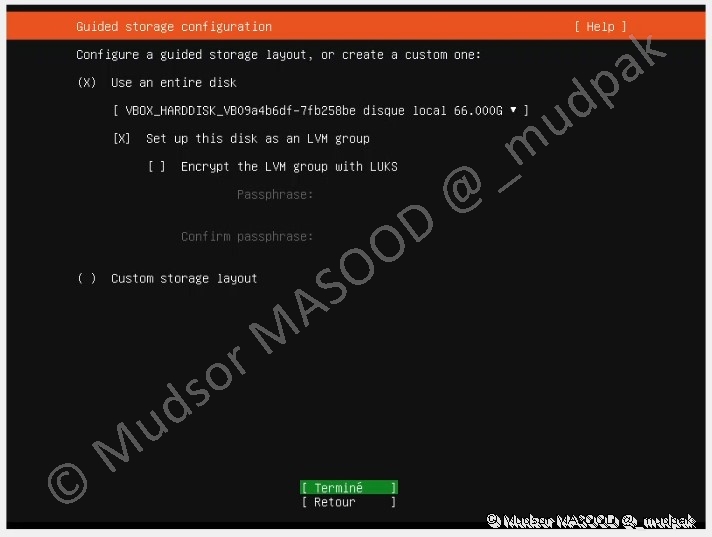
3.1.7 Configuration guidée du stockage
Vous pouvez configurer le partitionnement selon vos préférences, dans notre cas pour des besoins de démonstrations nous n’avons pas chiffrer le disque mais puisque les données contenues peuvent être de nature confidentielle je vous recommande de le chiffrer.
Vous pouvez également partitionner plus finement le disque pour par exemple séparer les partitions qui contiennent des données utilisateurs et d’autres qui contiennent que les données des différents services.
Quel que soit votre choix il faut veiller à ce qu’il y ait suffisamment d’espace disque pour stocker les données.
Dans notre cas nous allons utiliser l’option par défaut et sélectionner :
- Terminé
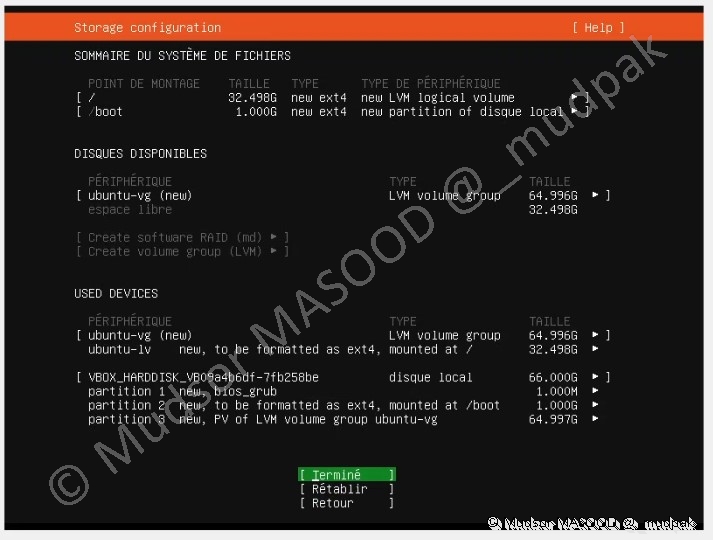
3.1.8 Configuration du stockage
Le système se charge de créer les différentes partitions pour confirmer sélectionner :
- Terminé
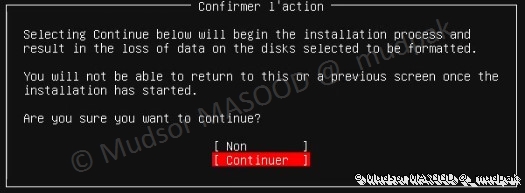
3.1.9 Confirmer l’action
Puisque le partitionnement va formater le disque, pour des raisons de sécurité une confirmation nous ait demandée, sélectionner :
- Continuer
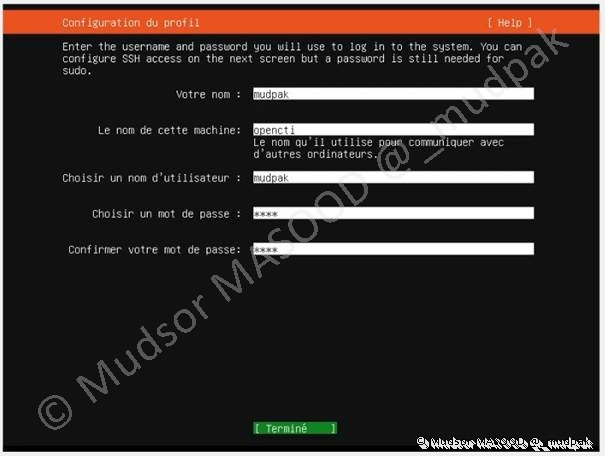
3.1.10 Configuration du profil
Vous êtes invités à créer un compte utilisateur, il faut spécifier les champs suivants
- Votre nom : le nom complet de l’utilisateur
- Le nom de cette machine : par le nom qui sera affiché sur le poste et par lequel il sera identifié sur le réseau
- Choisir un nom d’utilisateur : un nom ou un pseudonyme que l’utilisateur va utiliser pour se connecter sur le poste
- Choisir un mot de passe :
- Un mot de passe d’au moins 16 caractères composé de chiffres, lettres et symboles
- Il est recommandé d’utiliser un mot de passe complexe, et non comme c’est le cas cidessous où il n’est composé que de 4 caractères
- Confirmer votre mot de passe : saisir à nouveau le mot de passe pour s’assurer que vous ne vous êtes pas trompé
Lorsque les champs sont renseignés, sélectionner :
- Terminé
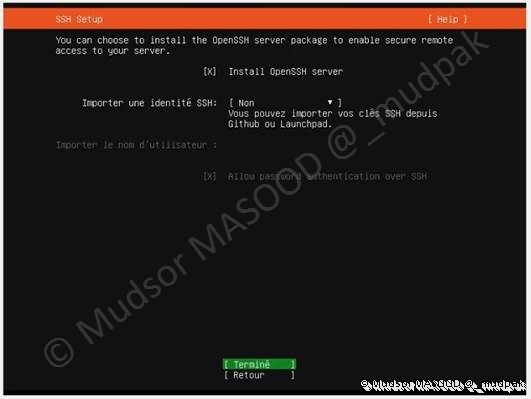
3.1.11 SSH Setup
Pour des raisons de simplicité et d’administration je vous recommande fortement l’installation du serveur SSH qui vous permettra par la suite d’administrer le serveur à distance.
Sélectionner :
- Install OpenSSH server
Sélectionner :
- Terminé
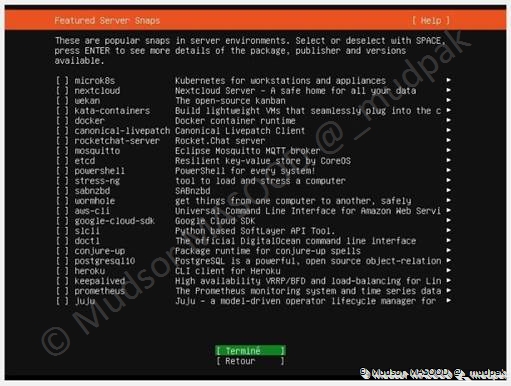
3.1.12 Featured Server Snaps
Vous pouvez installer d’autres packages si vous le souhaitez, pour l’instant je vous recommande de ne rien sélectionner d’autres et sélectionner :
- Terminé
3.1.13 Installation du système
L’installation du système d’exploitation commence, elle va prendre un certain temps.
Vous pouvez suivre l’installation en détails en sélectionnant :
- View full log
3.1.14 Installation terminée !
Lorsque l’installation est terminée vous en êtes informé, il faut redémarrer le système pour cela sélectionner :
- Redémarrer maintenant
Remarque :
Il vous sera demandé de retirer le média d’installation pour que le redémarrage puisse s’effectuer.
3.1.15 Première connexion
Lorsque le redémarrage est terminé, vous pouvez vous connecter sur le poste avec le compte précédemment crée :
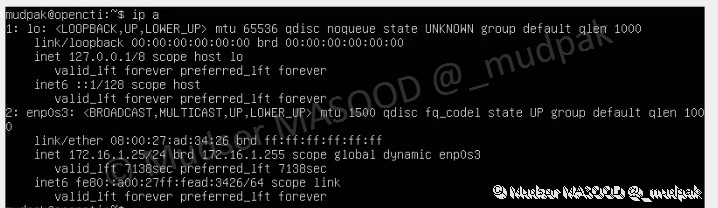
3.1.16 Configuration IP
Puisque nous avons choisi l’installation du serveur SSH pour administrer la machine à distance, il nous faut son adresse IP, pour l’obtenir saisir la commande :
1 | |
Détails de la commande :
1 2 3 4 | |
Dans le cas présent notre machine à l’adresse IP « 172.16.1.25 », ainsi pour la suite je peux me connecter en utilisant mon compte et administrer la machine.
3.2 Connexion SSH
Pour les opérations d’administration du serveur le protocole SSH (Secure SHell) sera utilisé, nous allons utiliser la commande suivante pour nous connecter :
1 | |
Détails de la commande :
1 2 3 4 5 6 | |

Puisque c’est la première fois que nous nous connectons au poste distant, pour des raisons de sécurité nous devons confirmer que c’est un l’hôte souhaité en vérifiant son identité (= que l’empreinte numérique est bien celle de la machine). Saisir
- « Yes »
Et appuyer sur la touche
- « Entrée »

Vous êtes invité à saisir le mot de passe du compte utilisateur, saisir le mot de passe et appuyer sur la touche
- « Entrée »
Remarque :
Si vous ne voyez pas le mot de passe que vous avez saisi c’est tout à fait normal, il s’agit d’une mesure de sécurité sous Linux.

Lorsque l’authentification s’effectue avec succès vous devez obtenir un résultat similaire à ci-dessous :
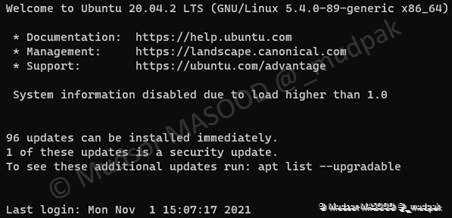
Le système nous informe que 96 mises à jour peuvent être installées dont 1 concernant la sécurité de celui-ci.

3.3 Mise à jour de la liste des paquets
Maintenant que le système d’exploitation est installé et que nous sommes connectés à la machine, il faut en premier lieu procéder à la mise à jour.
Saisir la commande suivante :
1 | |
Détails de la commande :
1 2 3 4 5 6 7 8 9 | |

Selon la vitesse de votre connexion internet ce processus peut prendre un certain temps.
Dans le cas présent il n’a pas duré longtemps et nous sommes invités à utiliser la commande
1 | |
Pour afficher la liste des paquets qui peuvent être mis à jour.
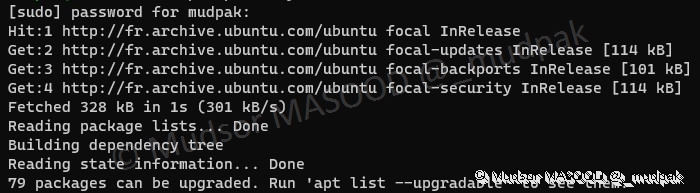
3.4 Installation des nouveaux paquets
Pour mettre à jour les paquets saisir la commande suivante :
1 | |

La liste des paquets qui sera mise à jour et en quelle version s’affiche et la mise à jour commence sans nous demander la confirmation puisque nous avons spécifié le paramètre « -y » :

Selon votre connexion internet et le nombre de paquets à mettre à jour ce processus peut prendre un certain temps :
Ci-dessous nous pouvons voir un exemple de ce qui est fait lors de cette phase tel que :
- Installation de la nouvelle version des paquets
- Mise à jour des fichiers de configuration
- . . .
Les changements de versions de certains paquets requièrent un redémarrage du système, pour faire cela saisir la commande suivante :
1 | |
4. Docker
Maintenant que notre système est à jour nous allons pouvoir commencer l’installation de docker.
4.1 Passage en mode « root »
L’installation de docker doit s’effectuer en mode « root », saisir la commande suivante :
1 | |
Détails de la commande :
1 2 3 4 5 | |
Remarque :
Vous ne pourrez exécuter cette commande que si vous êtes membre du groupe « sudo ».

Nous devons saisir le mot de passe du compte utilisateur :
4.2 Récupération du script
Pour installer docker, il existe différentes méthodes.
Dans le cas présent nous allons utiliser le script présent sur leur site, l’avantage est qu’avec cette méthode la version la plus récente et la plus adaptée à notre architecture sera fait automatiquement !
Saisir la commande suivante :
1 | |
Détails de la commande :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Pour vérifier que nous avons bien récupéré le script, saisir la commande suivante :
1 | |
Détails de la commande :
1 2 3 4 5 6 7 8 | |
Nous pouvons voir ci-dessous que le script à bien été récupéré le 1er Novembre :

4.3 Exécution du script
Pour exécuter le script d’installation, saisir la commande suivante :
1 | |
Détails de la commande :
1 2 3 4 | |

4.4 Installation
L’installation commence et elle peut prendre un certain temps :

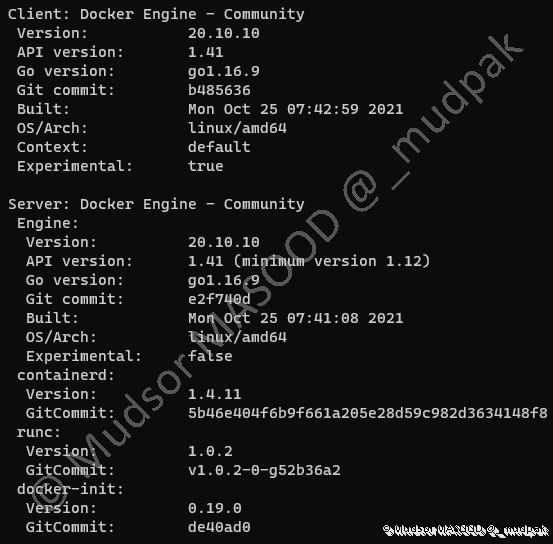
Lorsque l’installation est terminée, voici un exemple de résultat qui s’affiche avec les informations suivantes :
- Client : Docker Engine – Community
- Server : Docker Engine – Community
En effet le script installe à la fois « docker server » et « docker client » en plus de cela c’est la version « Community » qui est installée car autrement il faut disposer de licences d’entreprise pour avoir d’autres fonctionnalités.
Pour nos besoins de démonstrations la version Community sera largement suffisante.
Il est important de noter que l’installation de docker s’est effectuée via des droits « root » et pour des raisons de sécurité il est désormais possible d’exécuter docker en mode « rootless » :
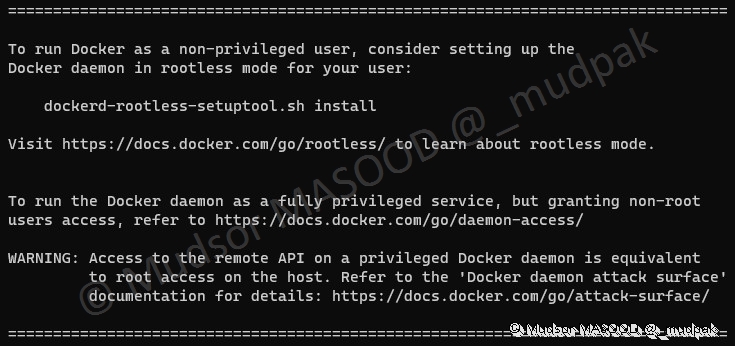
4.5 Ajout au groupe « docker »
Il est recommandé d’utiliser la méthode ci-dessus, mais pour des raisons de simplicité je préfère utiliser une méthode alternative.
Dans le cas présent je vais ajouter mon compte utilisateur « mudpak » au groupe « docker » afin que je puisse utiliser docker via mon « simple compte utilisateur ».
Saisir la commande suivante :
1 | |
Détails de la commande :
1 2 3 4 5 6 7 8 9 10 11 12 | |

4.6 Vérification des changements
Nous pouvons exécuter la commande ci-dessous avec le compte « normal » pour être certain que les droits ont bien été attribués :
1 | |
Détails de la commande :
1 2 3 4 | |

5. Docker-Compose – Part 1
Docker est installé, maintenant nous allons procéder à l’installation de docker-compose afin qu’il soit possible de faire de l’orchestration des containers de manière plus aisée.
5.1 Installation de docker-compose
Saisir la commande suivante pour commencer l’installation de docker-compose :
1 | |

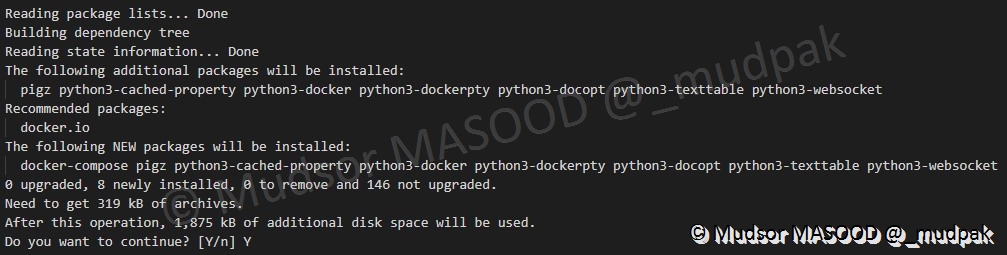
La liste des paquets qui seront installés est affichée et une confirmation est demandée avant de procéder à leur installation.
Saisir « Y » pour confirmer et appuyer sur la touche « Entrée » :
Le téléchargement et installation des paquets peut prendre un certain temps :
5.2 Vérification de la version
Lorsque l’installation est terminée, nous pouvons le vérifier par exemple en affichant la version installée en saisissant la commande suivante :
1 | |

6. OpenCTI – Installation
Maintenant que le système est installé et mis à jour, docker et docker-compose sont installés nous avons différentes options pour la suite des opérations.
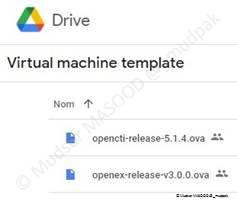
6.1 Via l’image virtuelle
OpenCTI fourni une image virtuelle toute prête à l’usage, il suffit de la télécharger depuis l’adresse suivante et l’utiliser avec VirtualBox :
1 | |
Remarque :
Il faudra penser à configurer certains éléments, mais c’est la solution la plus rapide pour avoir une plateforme OpenCTI fonctionnelle.
6.2 Via Terraform
Vous pouvez installer la solution via Terraform, pour cela je vous invite à vous référrer à la documentation à la page suivante :
1 | |
6.3 Manuelle
Si vous souhaitez installer tous les composants de la plateforme manuellement et tout configurer il est tout à fait possible !
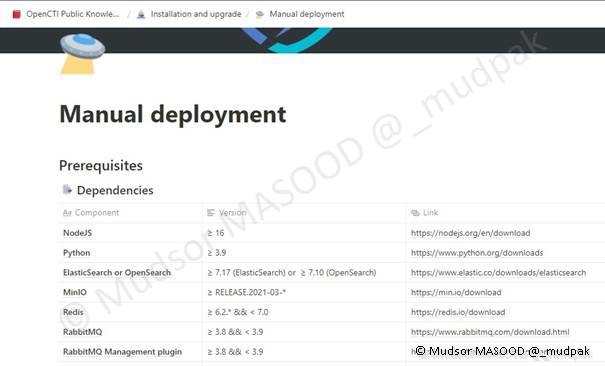
Pour faire cela je vous invite à consulter la documentation officielle :
1 | |
6.4 Via Docker
Et enfin la méthode que nous allons utiliser pour l’installation de la plateforme se fera via Docker.
6.4.1 Création du répertoire
Il est recommandé de créer un répertoire dédié à OpenCTI, en effet dans les prochaines étapes nous allons le peupler avec des fichiers et dossiers ainsi il sera plus simple de s’y retrouver.
Saisir la commande suivante pour créer un dossier :
1 | |
Détails de la commande :
1 2 3 4 5 6 | |

Pour nous déplacer dans le répertoire crée à l’étape précédente, nous allons utiliser la commande suivante :
1 | |
Détails de la commande :
1 2 3 4 | |
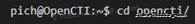
6.4.2 Récupération du répertoire
Nous allons récupérer un répertoire depuis le GitHub officiel de la solution via la commande suivante :
1 | |
Détails de la commande :
1 2 3 4 5 6 | |

Ce qui aura pour conséquence la copie du répertoire distant dans un répertoire local nommé « docker » :
Puisque les documents copiés se trouvent dans un répertoire nommé « docker », il ne faut pas oublier de se déplacer dans le répertoire pour la suite des opérations :

6.4.3 Contenu du répertoire
Avant d’aller plus loin nous allons prendre le temps de regarder les éléments présents dans le répertoire et voir les fichiers qui seront essentiels pour la suite des évènements.
Saisir la commande suivante pour afficher tous les éléments présents dans le dossier :
1 | |

Nous pouvons voir qu’il y a au total 52 éléments dans le dossier et sous-dossiers mais les éléments qui nous intéressent sont présents ici :
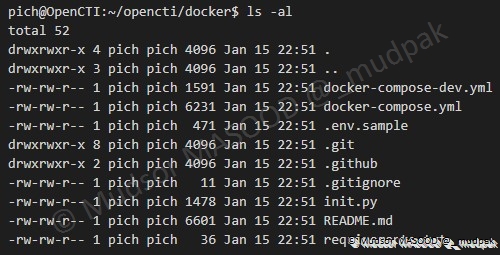
Voici les deux fichiers essentiels pour la suite :
1 2 3 4 5 | |
Remarque :
Pour des raisons de sécurité il est fortement déconseillé de mettre des éléments sensibles dans le fichier « docker-compose.yml ».
A la place utiliser des variables dont la valeur sera stockée dans le fichier « .env ».
6.4.4 .env
Nous allons copier le fichier « .env.sample » pour le personnaliser avec notre configuration souhaitée, pour cela saisir la commande suivante :
1 | |
Détails de la commande :
1 2 3 4 5 6 | |
Remarque :
La présence du symbole point « . » devant un fichier sous Linux signifie que ce fichier est par défaut caché.

Nous pouvons désormais utiliser un éditeur de texte pour modifier le fichier et insérer le contenu qu’on souhaite, saisir la commande suivante :
1 | |
Détails de la commande :
1 2 3 4 | |

Voici les champs qui doivent au minimum être complétés pour passer à l’étape suivante :
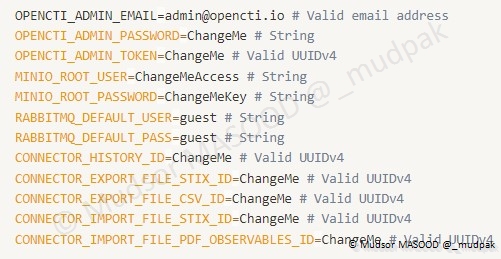
Important :
Dans les bonnes pratiques OpenCTI, il est recommandé que chaque connecteur ait un identifiant UUID v4.
Il ne faut en aucun cas qu’un connecteur ait l’ID du compte administrateur ou tout autre compte qu’un compte de type « connecteur », en effet en cas de compromission cela pourrait causer des dégâts plus élevés.
Si vous souhaitez obtenir des UUID v4 conformes je vous invite à en générer sur le site suivant par exemple :
Saisir la commande suivante pour activer le service docker au démarrage, ainsi à chaque redémarrage du poste docker sera automatiquement démarré :
1 | |
Détails de la commande :
1 2 3 4 5 6 7 8 | |

6.4.5 ElasticSearch
Il faut insérer un paramètre à la fin de fichier « /etc/sysctl.conf », pour faire cela saisir la commande suivante :
1 | |

A la fin du fichier ajouter le paramètre suivant :
1 | |
6.4.6 docker-compose.yml
Ce fichier étant relativement long, nous allons le découper en plusieurs parties pour voir les éléments présents avant de déployer la stack.
Pour afficher le contenu du fichier saisir la commande suivante :
1 | |

Important :
Selon la version et la date de consultation du contenu de ce fichier, les éléments peuvent changer, ici je montre le fichier de configuration pour montrer un exemple de contenu attendu.
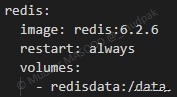
6.4.6.1 Redis
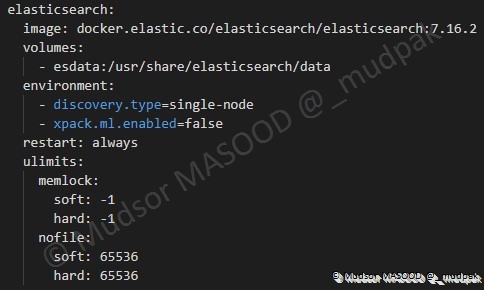
6.4.6.2 ElasticSearch
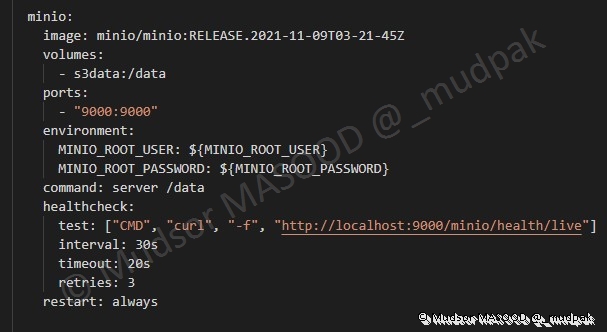
6.4.6.3 Minio
6.4.6.4 RabbitMQ
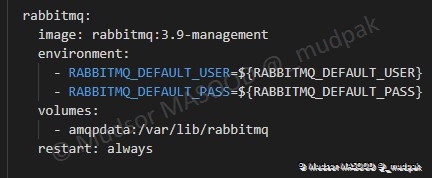
6.4.6.5 OpenCTI
Voici sans doute le container le plus important, puisque le but après tout c’est d’avoir du OpenCTI fonctionnel !
Nous pouvons noter dès à présent le port par défaut pour accéder à l’interface web de la plateforme depuis le port « 8080 ».
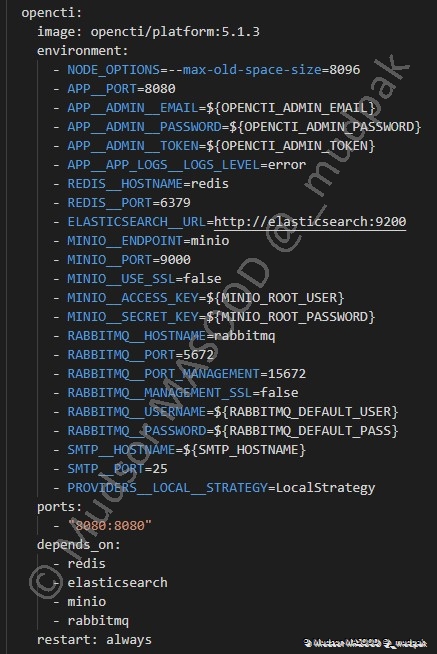
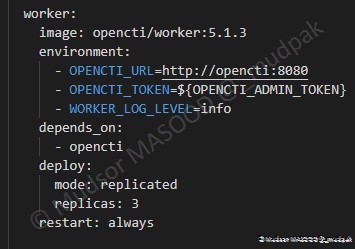
6.4.6.6 Worker
Par défaut « 3 » workers sont créés, vous pouvez ajuster ce paramètre :
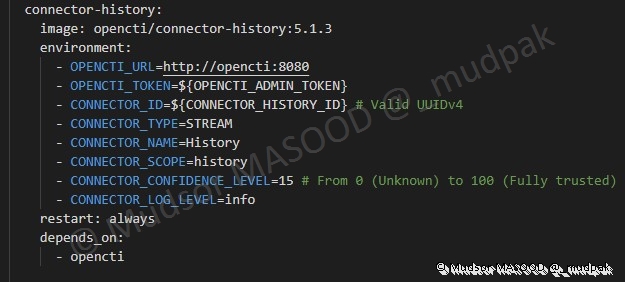
6.4.6.7 Connector-History
Ce connecteur va permettre d’ajouter l’historique des éléments par exemple date de création, modification, auteur …
6.4.6.8 Connector Export File STIX
Ce connecteur va permettre d’exporter les éléments au format STIX
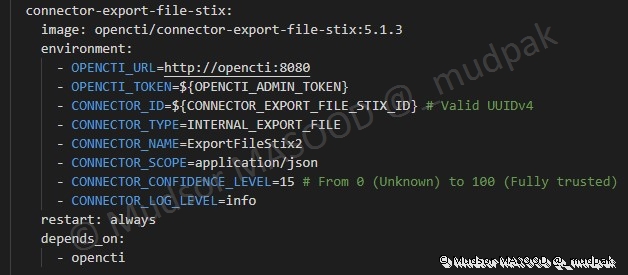
6.4.6.9 Connector Export File CSV
Ce connecteur va permettre d’exporter les éléments au format CSV
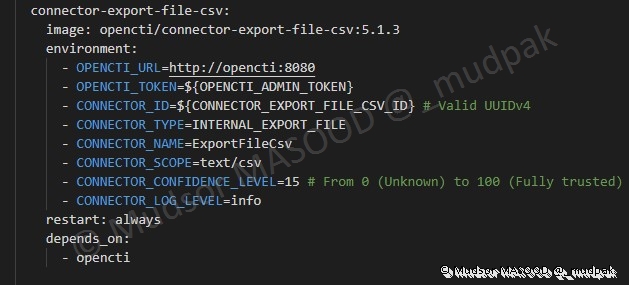
6.4.6.10 Connector Export File TXT
Ce connecteur va permettre d’exporter les éléments au format TXT
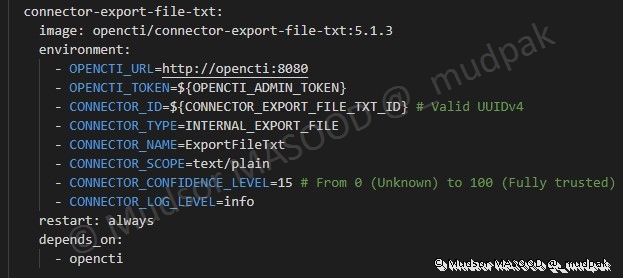
6.4.6.11 Connector Import File STIX
Ce connecteur va permettre d’importer des éléments depuis un format STIX
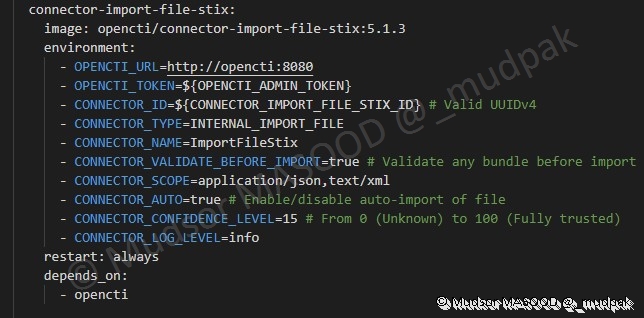
6.4.6.12 Connector Import Document
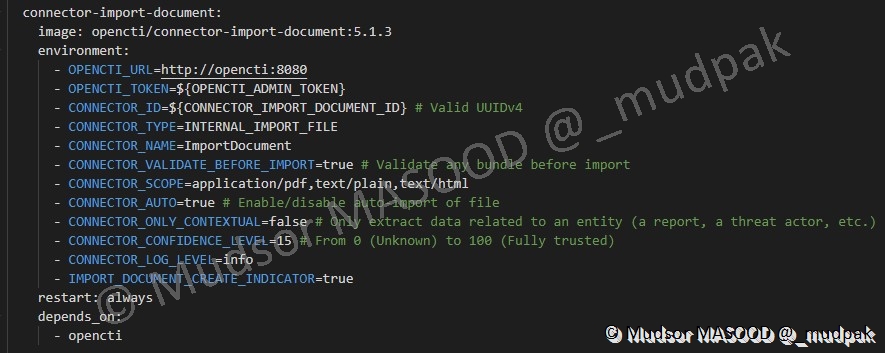
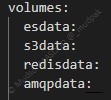
6.4.6.13 Volumes
Les données sont enregistrées sur des volumes :
6.4.6.14 Cas général
Tout au long du fichier de configuration nous avons pu constater les éléments suivants:
- Les containers sont les uns et les autres dépendants du container « OpenCTI », ce qui signifie que tant que ce container n’est pas démarré, les autres dépendant de lui pour le bon fonctionnement
- OpenCTI va attendre ses dépendances (elastic, redis, minio, rabbit) et les connecteurs vont attendre OpenCTI
- Les containers ont le paramètre « restart : always » ainsi même en cas de redémarrage de la machine, les services redémarrent automatiquement
- La persistance des données est assurée dans des volumes.
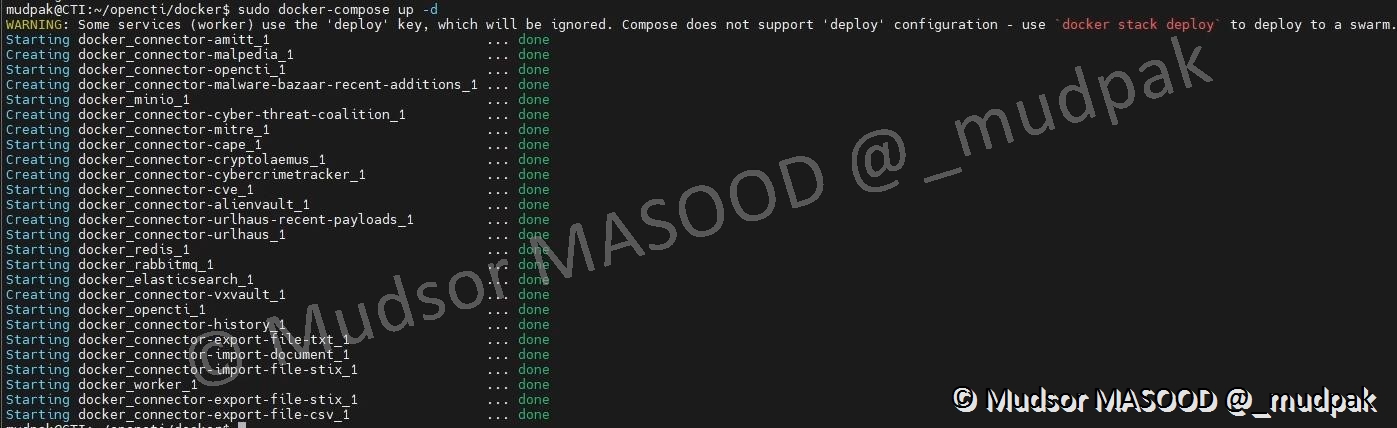
6.4.6.15 Déploiement de la stack
Nous pouvons à ce stade déployer la stack et avoir une CTI fonctionnelle, cependant il manquera un élément essentiel, les données !
En effet la plateforme sera fonctionnelle mais puisqu’aucune source de données n’aura été renseignée nous n’aurons pas d’éléments.
Cependant pour des raisons de simplicité nous allons quand même déployer la stack maintenant et la mettre à jour par la suite pour prendre en compte les changements.
Saisir la commande suivante :
1 | |
Détails de la commande :
1 2 3 4 5 6 | |
Remarque :
Il est essentiel d’être dans le répertoire qui contient le fichier « docker-compose.yml ».

Docker applique la configuration du fichier « docker-compose.yml », dans le cas présent la création d’un réseau, des volumes, téléchargement des containers sont réalisées.
Cette étape peut prendre un certain temps lorsqu’elle est exécutée pour la première fois.
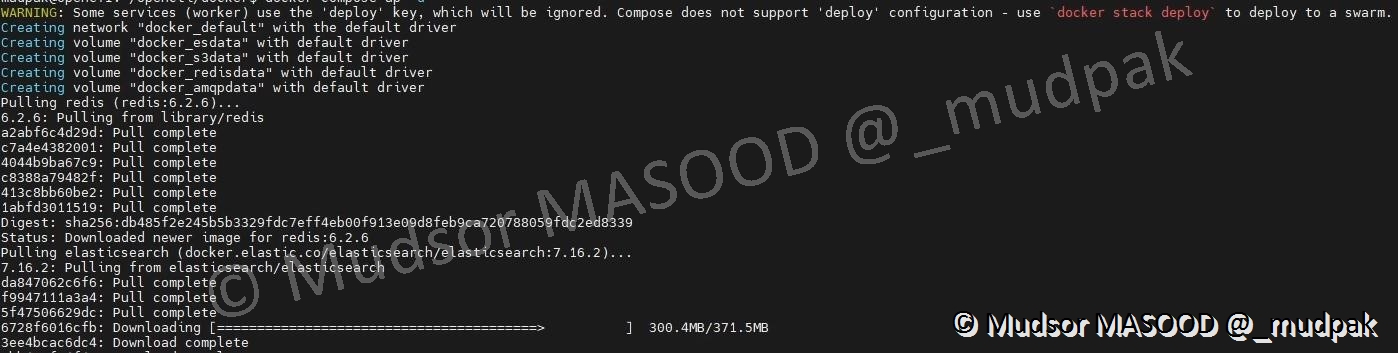
Lorsque le processus est terminé, vous devez obtenir un résultat similaire à ci-dessous.
Tous les connecteurs démarrent mais cela ne veut pas dire que la plateforme est up en effet il faut attendre un certain temps (15 à 20 minutes dans mon cas) le temps que la plateforme se mette en place et devienne accessible !
Le meilleur moyen et de regarder si elle est up, c’est de regarder les logs docker pour voir les traces de start de la plateforme.
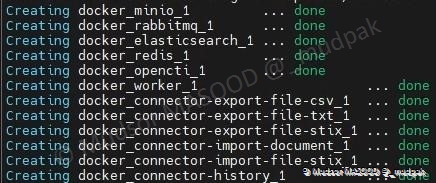
Pour enrichir notre plateforme nous allons ajouter des connecteurs externes et par la suite nous partirons sur l’exploration de la plateforme.
7. Sources de données gratuites
Pour « enrichir » la plateforme de données, vous pouvez importer des données via différentes méthodes, dans le cas présent nous allons parler des « connecteurs d’imports externes ».
Voici un tableau de liste de sources de données « gratuites » et publiques, par là j’entends
- Option 1 : Il n’y a pas besoin de se créer un compte sur la plateforme pour pouvoir accéder aux données
- Option 2 : Il y a besoin de créer un compte sur la plateforme mais l’accès aux données ne requiert aucun paiement en contrepartie
Remarque :
Bien évidemment si vous êtes dans un cercle de personnes qui partagent des données CTI via des instances privées MISP, YETI, OpenCTI ou autre il est tout à fait possible d’accéder aux données si les accès ont été accordés par le gestionnaire.
7.1 AlienVault OTX
Nous allons voir en détails comment créer un compte sur la plateforme AlivenVault OTX afin d’obtenir une clé API dans le but d’alimenter notre plateforme OpenCTI.
7.1.1 SIGN UP
Se rendre à l’adresse suivante :
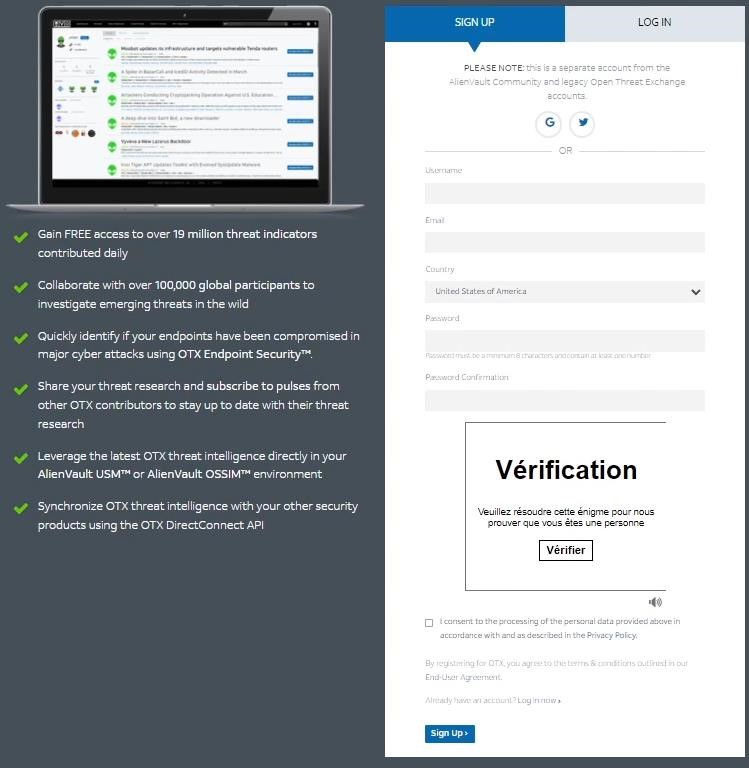
Cliquer sur « Sign Up » et remplir les champs :
- Username : par un pseudonyme contenant entre 8 à 30 caractères
- Email : une adresse email valide pour confirmer la création de votre compte
- Country : par votre pays
- Password : un mot de passe robuste
- Password Confirmation : saisir à nouveau le mot de passe pour être certain
- Vérifier : cliquer sur le captcha à résoudre
Cocher la case
- « I consent to the processing of the personal data provided above in accordance with and as described in the Privacy Policy. »
Cliquer sur
- Sign Up
7.1.2 Welcome to AlientVault OTX
Un message s’affiche vous informant qu’un email de vérification a été envoyé et qu’il faut suivre le lien pour confirmer votre compte :

Voici un exemple de mail que vous recevez et il faut cliquer sur le lien fourni pour procéder à la vérification du compte :
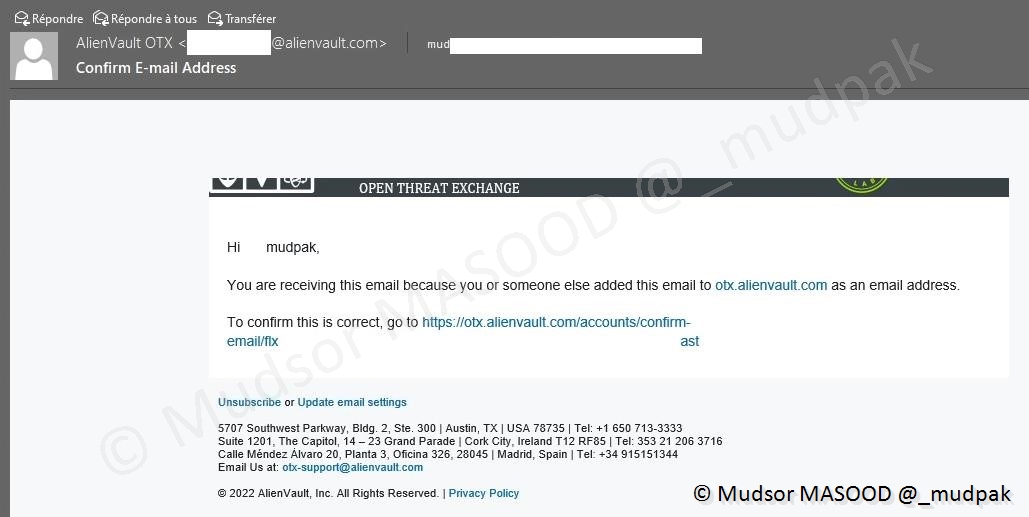
Cliquer sur
- Confirm Email

Le compte est désormais confirmé et nous pouvons nous connecter :

7.1.3 LOG IN
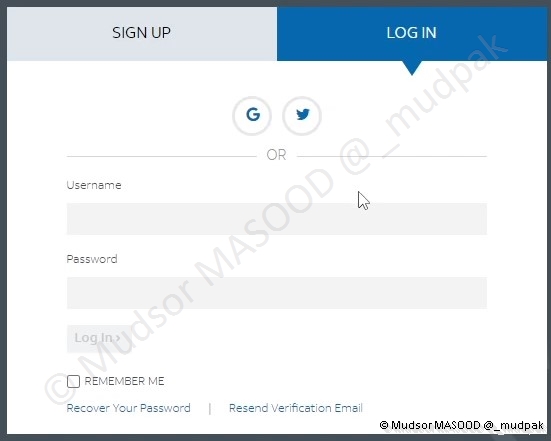
Cliquer sur
- Log In
Remplir les champs
- Username
- Password
Cliquer sur
- Log In
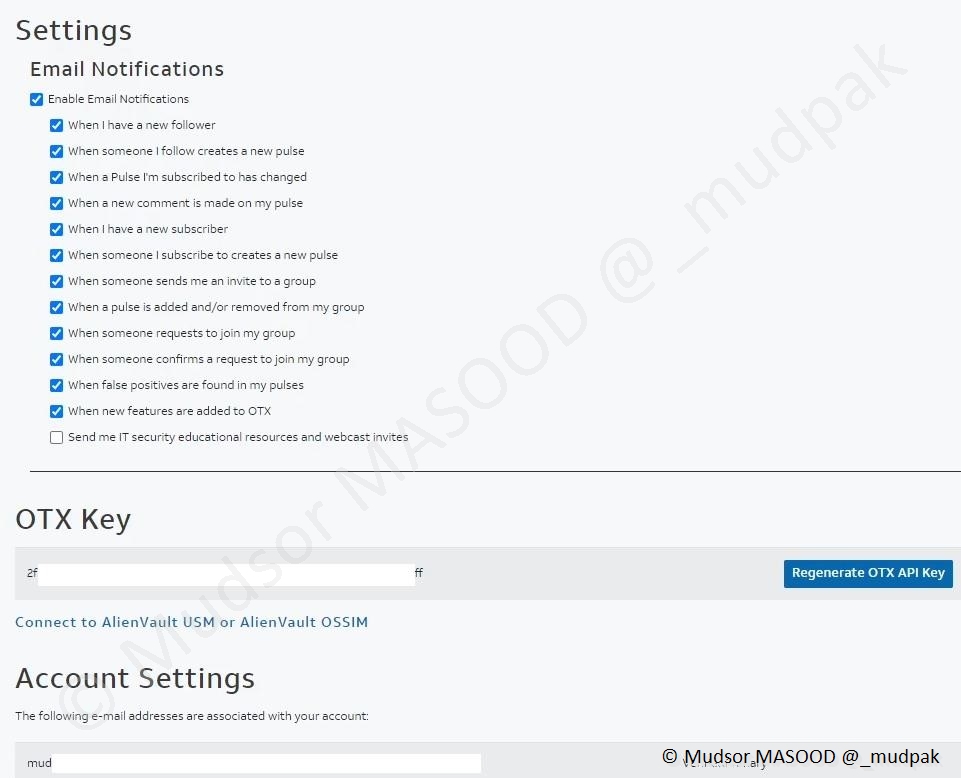
La page d’accueil nous affiche les paramètres du compte :
- Email Notifications : choisir quand être notifié par email
- OTX Key :
- Le champ qui nous intéresse !
- Vous pouvez voir la clé API liée à votre compte et à ne surtout pas partager
- Il est possible de générer une autre clé API en cliquant sur « Regenerate OTX API Key », ce qui aura pour effet de révoquer la clé précédente et vous en délivrer une nouvelle
- Account Settings : paramètres notamment d’adresse email principale, secondaire
A ce stade je vous invite à copier la clé API dans un endroit sur car par la suite nous allons en avoir besoin.
7.1.4 Ajout du connecteur
Voici la configuration par défaut du connecteur AlienVault OTX :
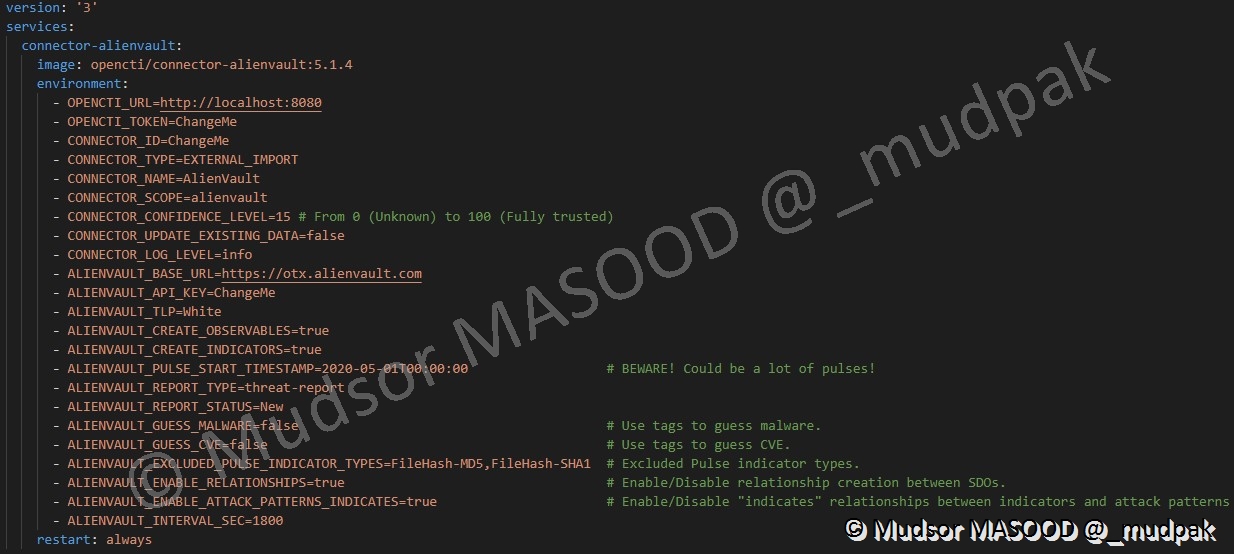
A ce stade si vous ajoutons cette configuration dans le fichier « docker-compose.yml », le connecteur ne fonctionnera pas en effet comme nous pouvons l’observer à certaines lignes il faut modifier la configuration pour ajouter nos paramètres personnalisés.
Pour que les nouveaux éléments soient pris en compte il faudra arrêter la stack en cours d’utilisation, appliquer les changements et relancer la stack pour que la prise en compte des changements soit effective, si ces étapes ne sont pas réalisées alors les changements ne seront pas appliqués notamment dans la partie « docker network ».
Dans le cas présent nous devons modifier trois champs :
- OPENCTI_TOKEN=ChangeMe : créer une variable et saisir sa valeur UUID v4 dans le fichier « .env »
- CONNECTOR_ID=ChangeMe : créer une variable et saisir sa valeur UUID v4 dans le fichier « .env »
- ALIENVAULT_API_KEY=ChangeMe : créer une variable et saisir sa valeur dans le fichier « .env »
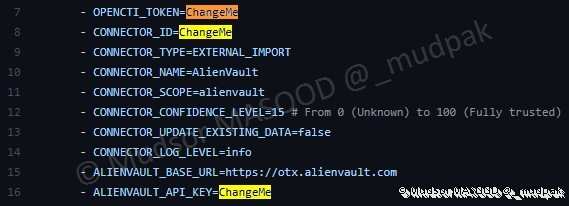
Voici un exemple de résultat qu’on peut obtenir dans le fichier « .env » :

Voici un exemple de résultat qu’on peut obtenir dans le fichier « docker-compose.yml » :
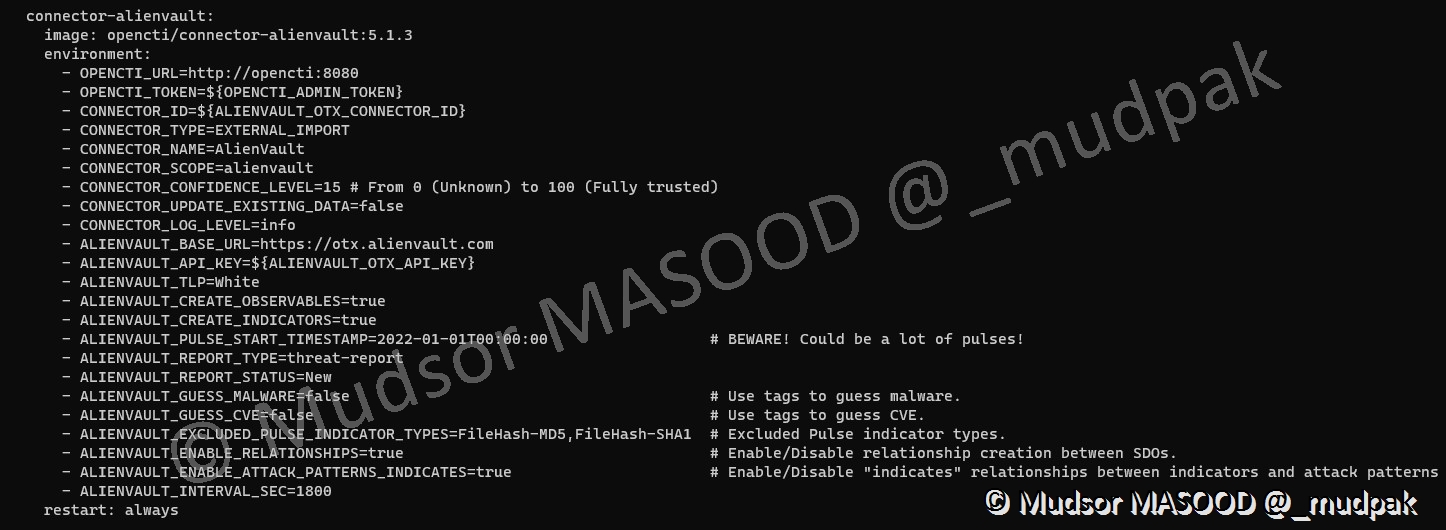
7.2 CVE
Contrairement au connecteur précédent, la configuration du connecteur CVE est beaucoup plus courte et simple !
En effet il ne requiert aucun compte, les seuls éléments dont nous aurons besoins seront :
- Un token OpenCTI
- Un ID (UUID v4) pour le connecteur
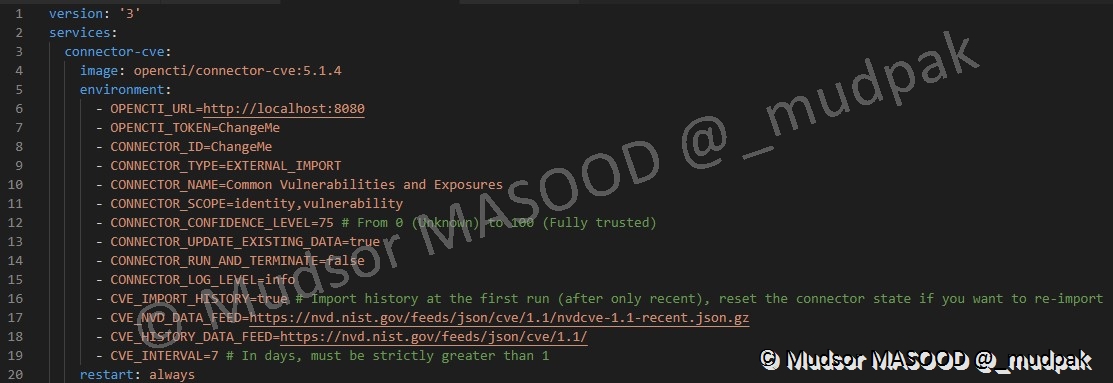
Il faut procéder de la même façon qu’avec le connecteur AlienVault, c’est-à-dire
- Modifier les valeurs « ChangeMe » par des variables
- Ajouter les variables dans le fichier « .env » et insérer leur valeur
Voici un exemple de résultat obtenu dans le fichier « .env » pour le connecteur CVE :

Voici un exemple de résultat obtenu dans le fichier « docker-compose » pour le connecteur CVE :
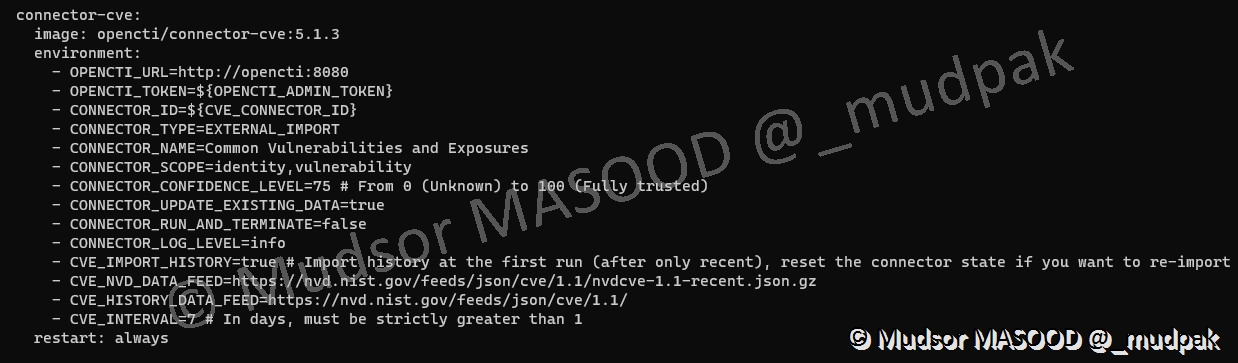
8. Sources de données payantes
Il faut considérer les autres plateformes que listées dans le chapitre précédent comme étant « payantes ».
Remarque :
Je ne rentre pas dans la subtilité de savoir si l’accès à une instance distante par exemple MISP est gratuit ou payant, car la solution a beau être open-source, le détenteur peut selon les personnes accorder ou refuser l’accès ou faire payer l’accès.
9. Docker Compose – Part 2
Maintenant que nous avons vu comment ajouter des connecteurs et effectué la configuration dans les fichiers « .env » et « docker-compose.yml » il faut faire appliquer ces changements !
En effet la stack étant en cours d’exécution nous devons la stopper, lui dire de recharger le fichier de configuration et relancer la stack.
Remarque :
Vous pouvez également exécuter la commande suivante pour aller plus rapidement « sudo docker-compose up -d » ce qui aura pour effet de relancer la stack avec la prise en compte des changements.
Cependant cela peut engendrer des erreurs auquel cas je vous conseille d’utiliser la méthode ci-dessous.
Si vous souhaitez procéder par différentes étapes vous pouvez suivre les étapes suivantes :
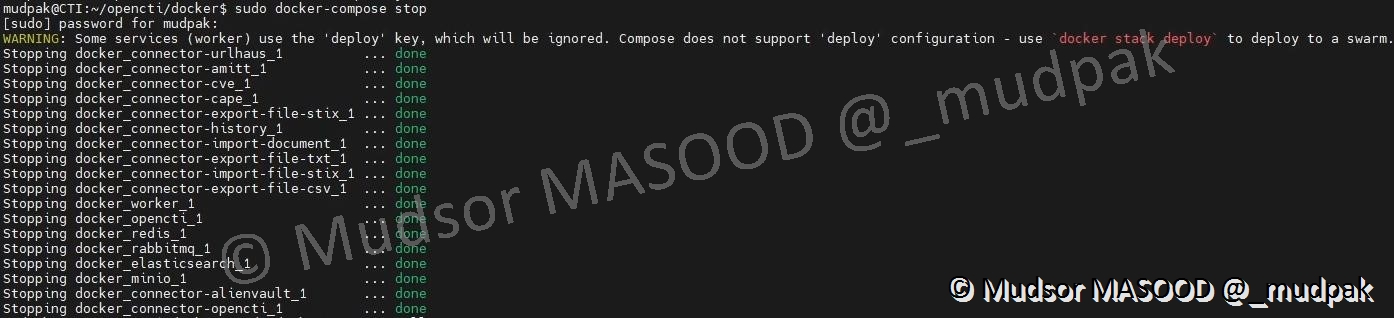
Pour faire cela saisir la commande suivante :
1 | |
L’arrêt des containers peut prendre un peu de temps :
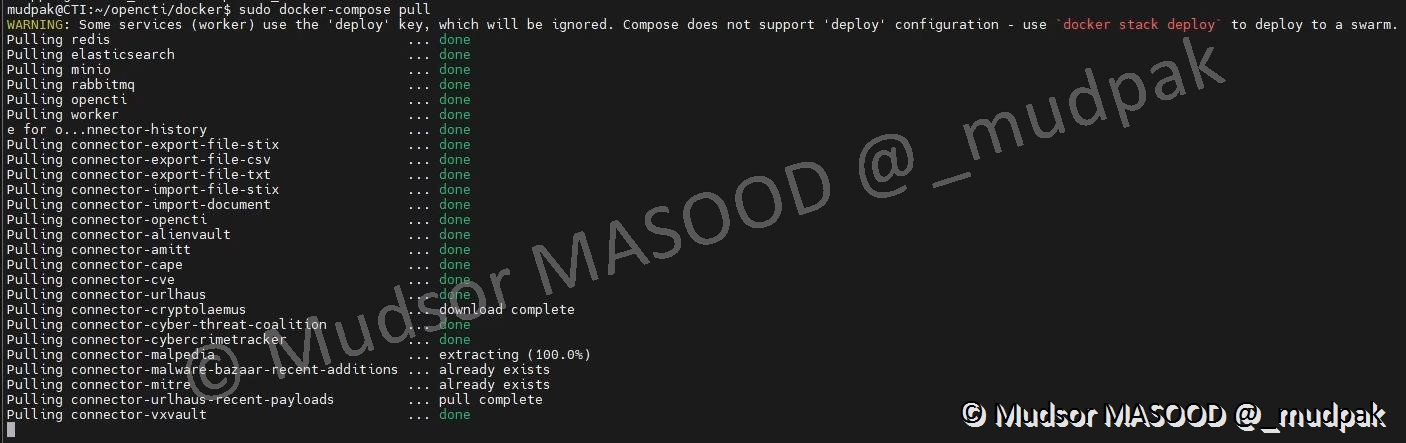
Pour recharger la configuration et obtenir les nouveaux containers, saisir la commande suivante :
1 | |
Comme nous pouvons le constater docker-compose télécharge et extrait les containers qui n’étaient jusqu’ici pas présents :
Pour démarrer la stack saisir la commande suivante :
1 | |
10. OpenCTI – Découverte de l’interface web
Après avoir réalisé toutes les étapes précédentes votre plateforme OpenCTI devrait être fonctionnelle et les données devraient commencer à s’ajouter.
Nous pouvons enfin partir à la découverte de la plateforme !
10.1 Connexion à l’’interface web
Se rendre à l’adresse suivante :
1 | |
Une page similaire à ci-dessous s’affiche, remplir les champs :
- Nom d’utilisateur : par l’adresse email renseignée dans le fichier « .env »
- Mot de passe : par le mot de passe renseigné dans le fichier « .env »
Cliquer sur
- S’IDENTIFIER

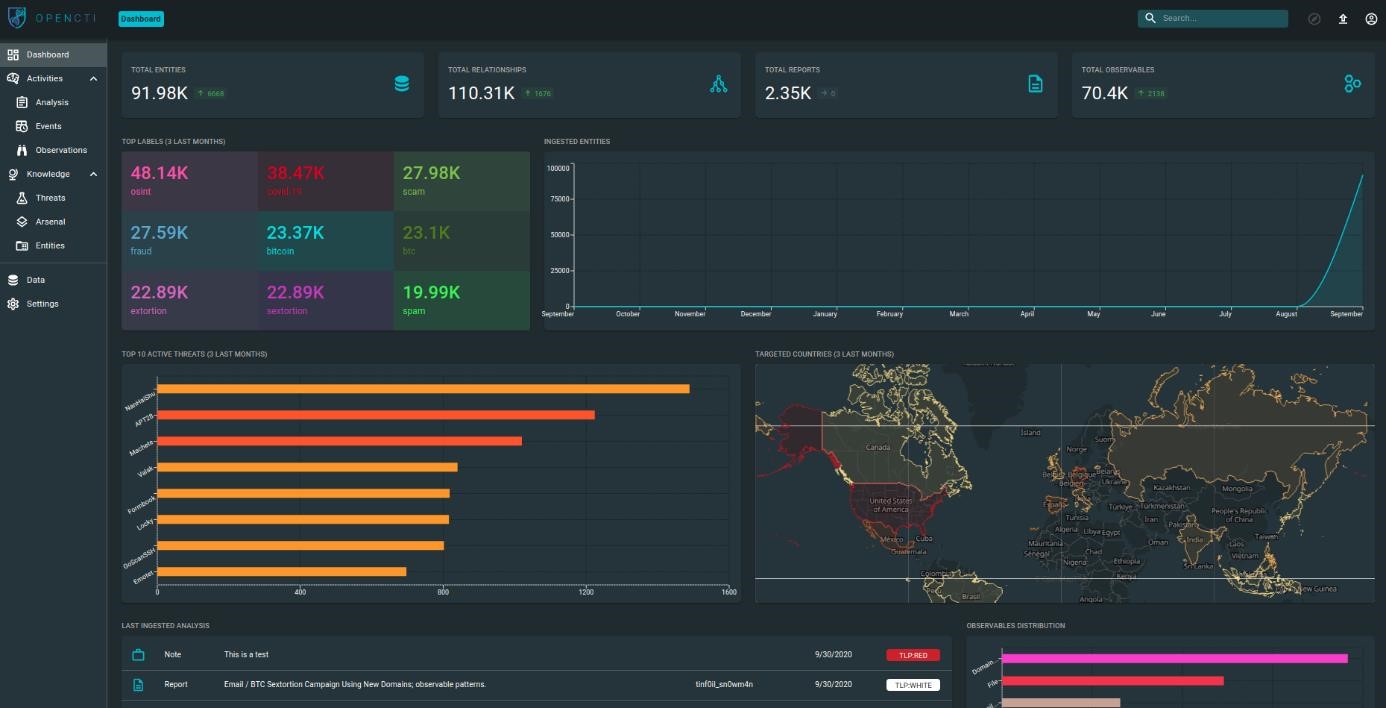
10.2 Tableau de bord
Commençons par le tableau de bord :

10.2.1 Recherche
Comme son nom l’indique, ce champ permet de faire des recherches :

L’avantage de ce menu c’est qu’on peut chercher tous types d’éléments sans avoir à préciser de paramètres spécifiques :
10.2.2 Recherche avancée
La recherche avancée située à droite de la recherche « simple » :
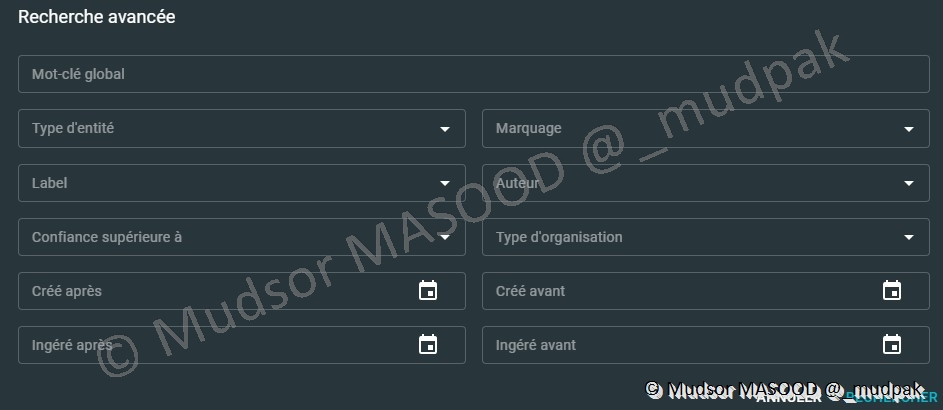
Nous pouvons chercher les éléments via les critères suivants :
- Mot-clé global : n’importe quel élément à chercher
- Type d’entité
- Label : on peut comparer ce système à un tag
- Confiance supérieure à : le niveau de confiance qu’on a en la source qui nous fournit l’information
- Crée après : élément après une certaine date
- Ingéré après : ingestion par la plateforme après une certaine date
- Marquage : le niveau de rapport au format « TLP »
- Auteur : auteur du rapport
- Type d’organisation
- Crée avant : rapport crée avant une certaine date
- Ingéré avant : ingestion dans la plateforme avant une certaine date
10.2.3 Tableaux de bords personnalisés
Par défaut il n’y a pas de tableaux de bords personnalisés, nous pouvons en créer en accédant dans ce menu :
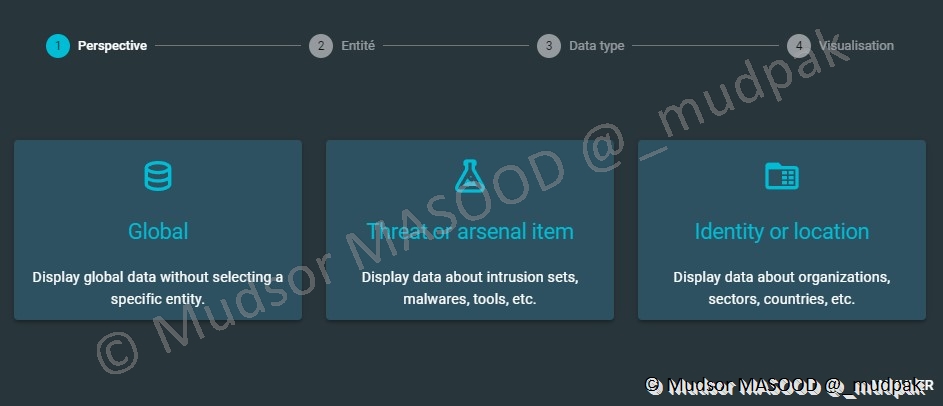
Il est possible de créer des tableaux de bords via différents critères tels que :
- Global : avoir un visuel général
- Threat or arsenal item : avoir des informations sur un élément spécifique
- Identity or location : avoir des informations sur une entité ou pays spécifique
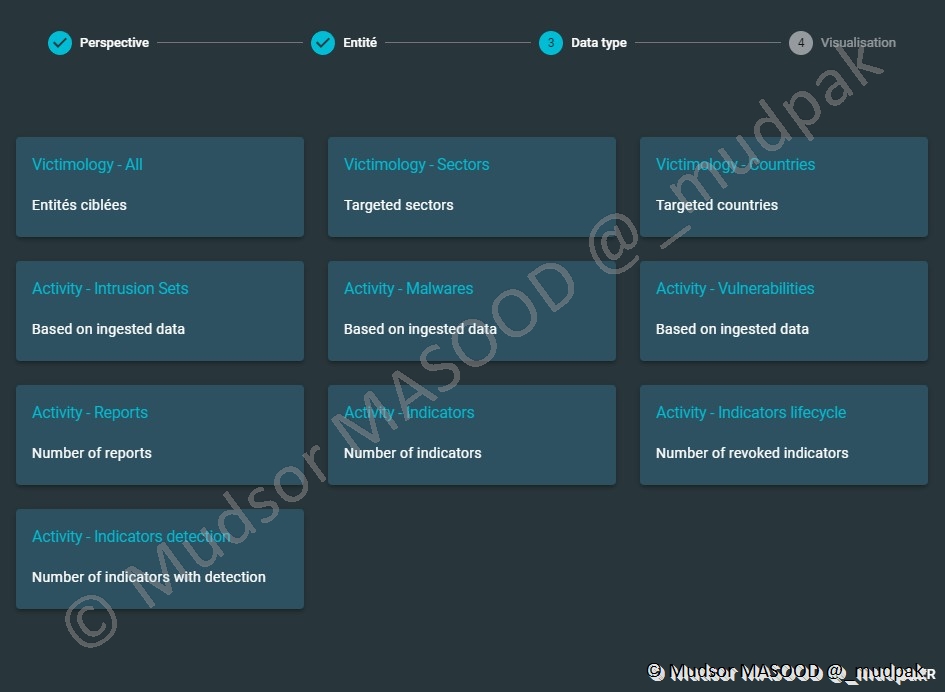
Selon le choix précédent, les données pourront être représentées sous différentes formes :
10.2.4 Investigations
Le but est de parcourir les graphes pour découvrir les relations.
10.2.5 Importation de données
Nous pouvons importer des données manuellement :
10.2.5.1 Fichiers uploadés
Nous pouvons uploader des fichiers :
- Soit en cliquant sur le logo du nuage pour sélectionner un fichier
- Soit en cliquent sur le logo du texte et saisir les informations en texte brute
10.2.5.2 Connecteurs d’import activés
Nous pouvons voir que les connecteurs sont bien actifs :
10.2.5.3 Fichiers en attente
Si des fichiers sont en attente ils seront listés ici :

10.2.6 Profil
Ce menu permet d’avoir les informations du compte utilisateur :
10.2.6.1 Profil
Nous pouvons voir et configurer les paramètres de votre compte à cet endroit.
Dans le cas présent nous pouvons constater que le compte actuel :
- Est un compte administrateur
- Est le compte de l’administrateur principal (=compte crée lors de la création de l’instance)
Important :
L’utilisation d’un compte à hauts privilèges en milieu de production est vivement déconseillée

10.2.6.2 Mot de passe
Nous pouvons modifier le mot de passe du compte à cet endroit :

10.2.6.3 Souscriptions & résumés
Feature qui permet de souscrire a des envois de mails concernant certaines informations.
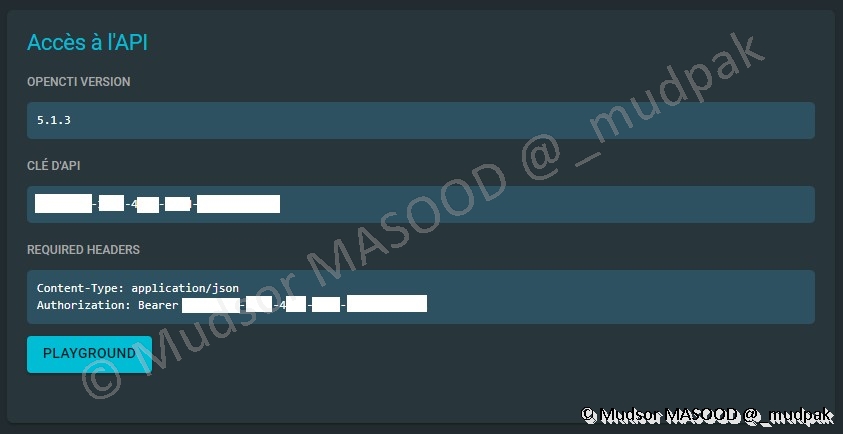
10.2.6.4 Accès à l’API
Nous avons quelques informations importantes dans cette partie, notamment la version de OpenCTI ainsi que la clé API du compte.
Par ailleurs en cliquant sur « PLAYGROUND » nous sommes redirigés vers une page « GraphSQL ».
10.2.7 Se déconnecter
Comme son nom l’indique, ce paramètre permet de se déconnecter de l’interface web.
10.3 Activités
Dans le menu latéral gauche nous allons nous intéresser aux sous-menus de « Activités » :
10.3.1 Analyses
Voici sans doute l’un des menus qui nous intéresse le plus ! En effet sous forme d’analyses sont représentées les informations issues de différents connecteurs.
Ce menu est composé de sous-menus :
- Rapports
- Notes
- Opinions
- Références externes

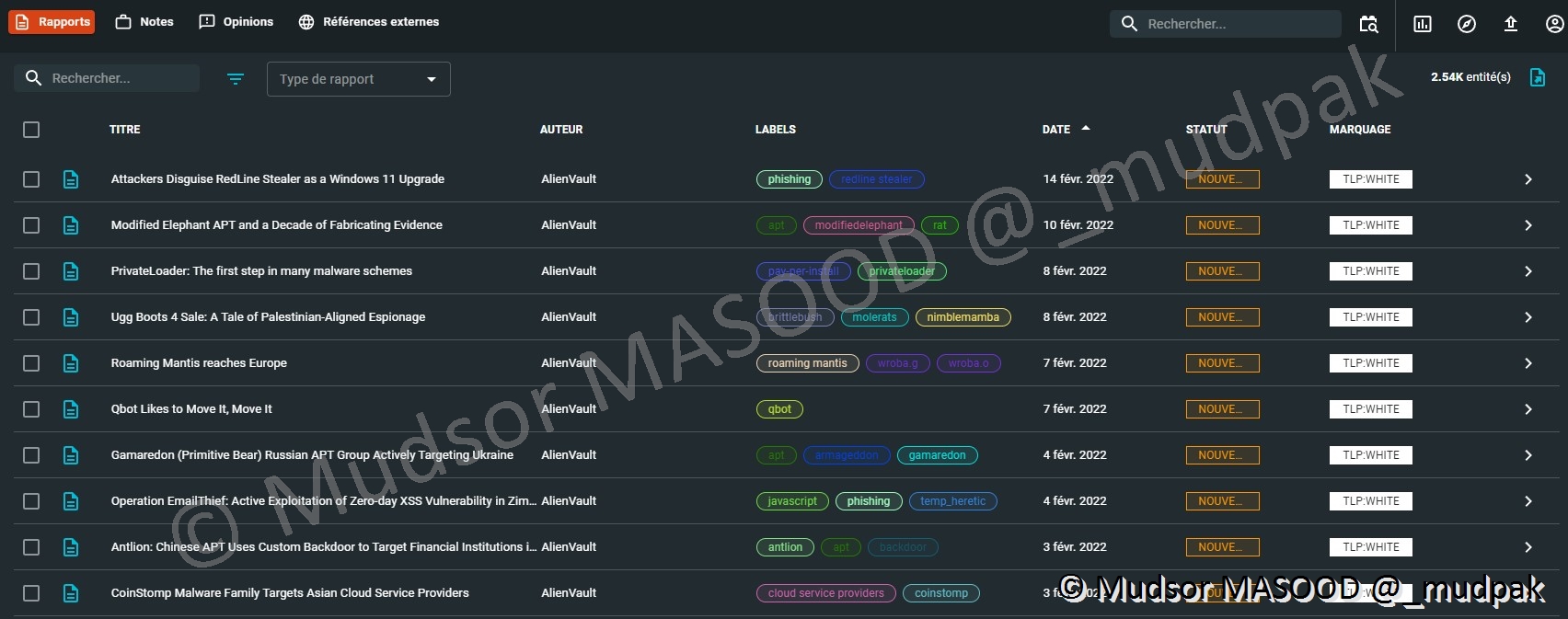
10.3.1.1 Rapports
Nous pouvons voir par exemple ci-dessous des rapports issus du connecteur AlienVault, les dates de création des rapports par le fournisseur, le statut ainsi que le marquage (=TLP).
Deux types de filtres sont présents :
- Recherche
- Type de rapport

Depuis ce menu et plus globalement tous les menus suivants il nous sera possible d’exporter les éléments sous différents formats (CSV, TXT, PDF …) effectuer cette opération il faut sélectionner un ou plusieurs éléments et cliquer sur le volet d’exports situé dans la zone supérieur droite de la fenêtre :
Voici un exemple d’export qui est prêt à être consulté :
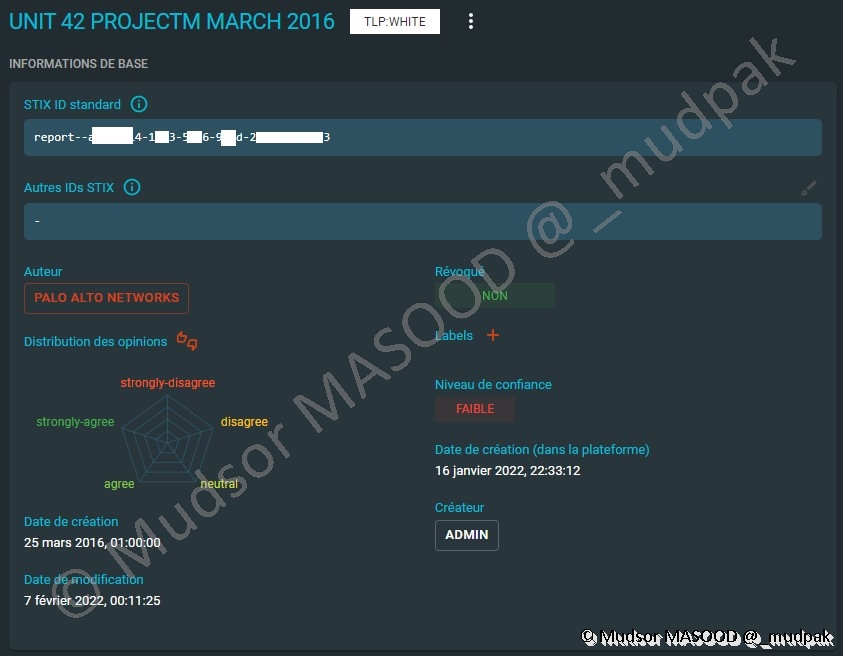
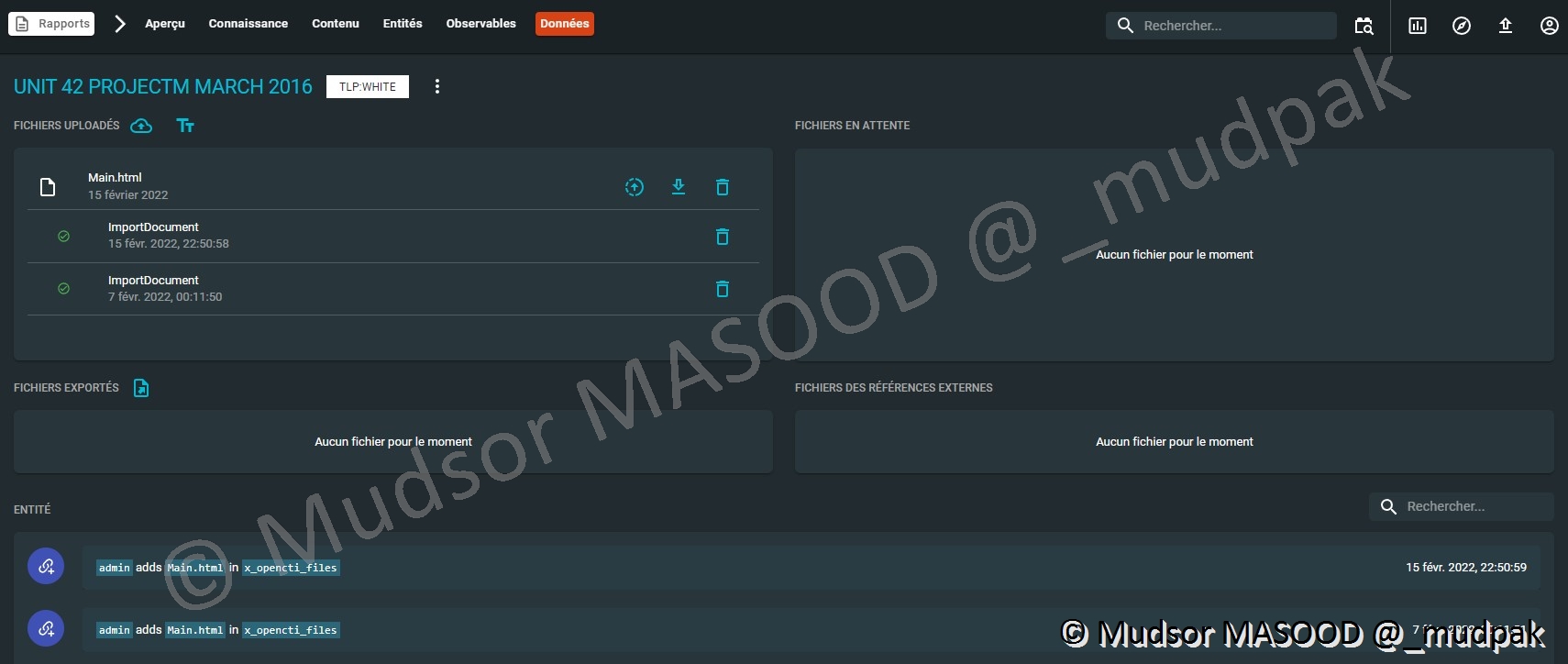
Pour visualiser la puissance de OpenCTI et ses fonctionnalités nous allons prendre le rapport « UNIT 42 PROJECTM MARCH 2016 » comme exemple.
Dans le menu général nous avons accès à différents sous-menus où se trouvent les informations sous différentes formes :

Informations de base » nous pouvons voir les informations suivantes :
- STIX ID standard : l’identifiant STIX donné au rapport
- Auteur : source qui a fourni le rapport
- Distribution des opinions : système de vote pour juger de la pertinence du rapport • Date de création : date à laquelle la source a créé le rapport
- Date de modification :
- Révoqué : est-ce que le rapport est toujours applicable ou non
- Labels : si des labels sont applicables
- Niveau de confiance : le niveau de confiance en ce rapport / fournisseur
- Date de création (dans la plateforme) : date à laquelle le rapport a été créé sur notre plateforme OpenCTI
- Créateur
- Le compte qui a été utilisé pour créer le rapport o C’est bien évidemment une mauvaise pratique que d’utiliser un compte de type administrateur pour créer des rapports
- Un rôle existe sur la plateforme pour les comptes de type « connecteur » ce qui est préférable dans ce type d’usage, nous verrons par la suite
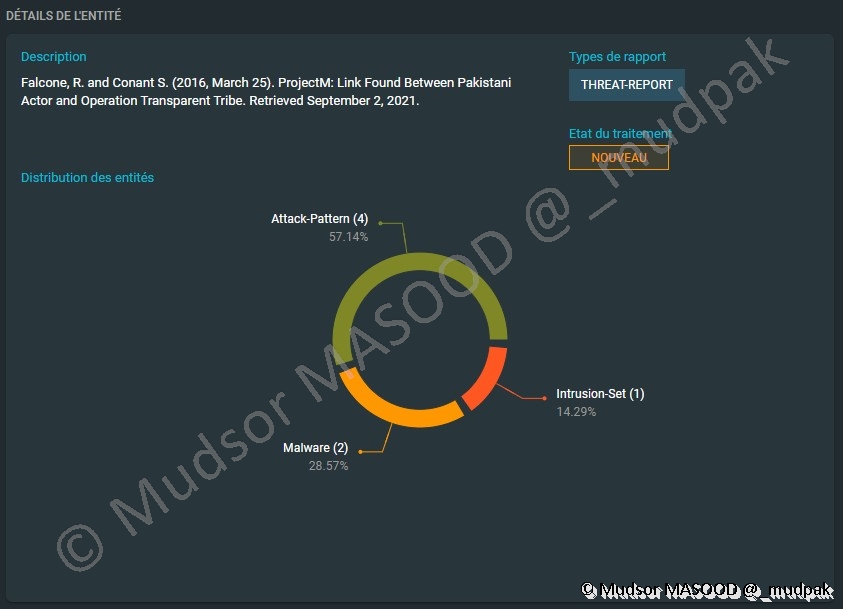
Détails de l’identité » nous pouvons voir différentes informations :
- Description : un résumé rapide du rapport, ce qui peut être pertinent pour des membres de type RSSI ou personnes souhaitant avoir une information globale du rapport
- Distribution des entités : quels types de données composent le rapport
- Types de rapport : est-ce que c’est un rapport de threat ou un rapport interne
- Etat du traitement : lié au système de workflow du concept.
Pour en savoir plus je vous invite à regarder la démo en live : https://demo.opencti.io/dashboard/settings/workflow?
Dans la partie « Références externes » nous pouvons consulter des éléments pour compléter notre étude du rapport :

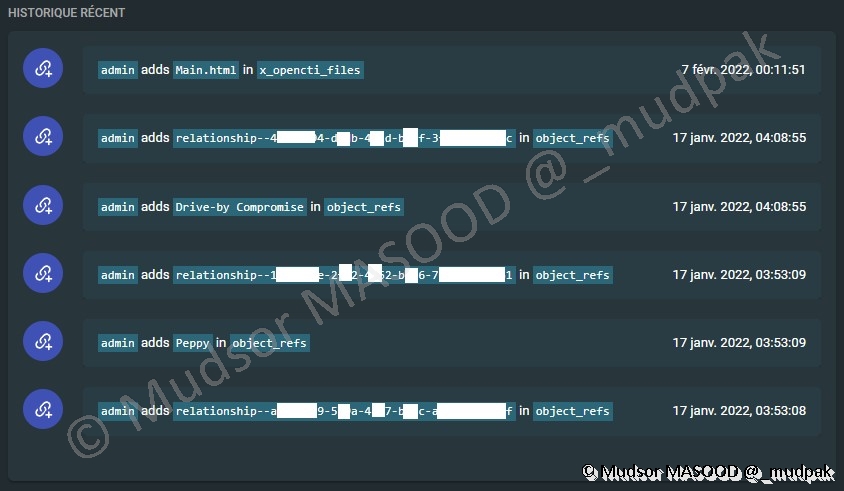
Dans la partie "Historique récent" nous pouvons voir les opérations qui ont été effectuées sur le rapport :
La dernière partie sur cette page « Notes à propos de cette entité » permet d’ajouter des éléments si on souhaite sous forme de note :
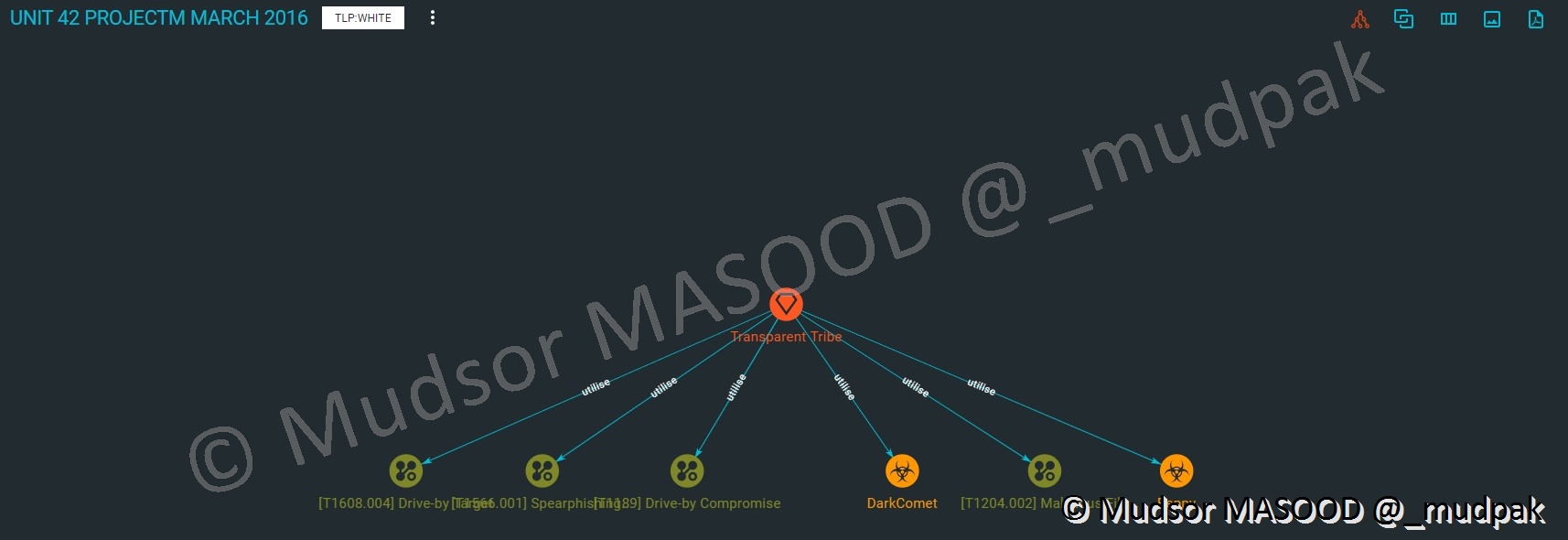
Explorons désormais la partie « Connaissances » du rapport :

Nous pouvons voir un affichage sous forme de graphe et relations entre les éléments, c’est une manière de représenter les éléments du rapport notamment les IOCs (=Indicator Of Compromission = Indicateurs de compromissions).
Parmi les éléments présents dans le graphe se trouve « DarkComet », c’est le moment idéal de saluer le bro Jean-Pierre LESUEUR (@darkcodersc)  ! You The Best !!
! You The Best !! 
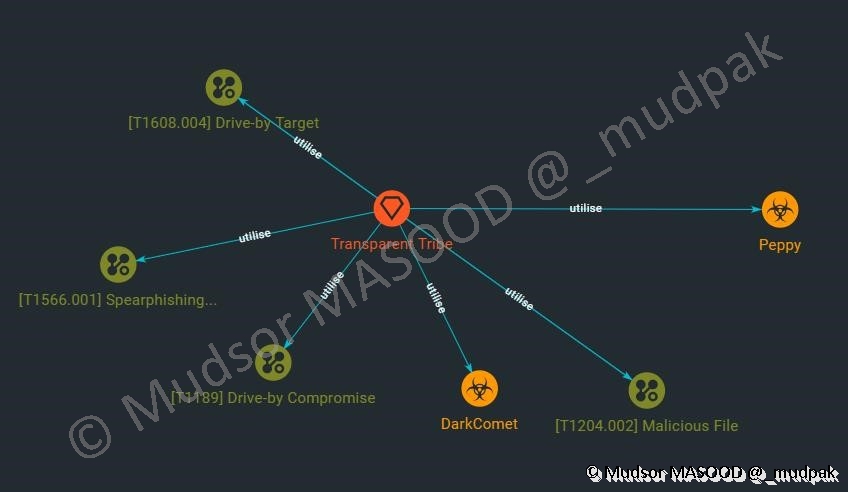
Le graphe étant tout à fait personnalisable, si nous avons du mal à visualiser certains éléments on peut les déplacer à souhait :
D’autres types de vues permettent d’avoir un visuel des relations de d’autres manières, comme c’est le cas de la « vue des corrélations » ci-dessous :

D’un point de vue Blue Team si nous souhaitons avoir comme base la MITRE & ATT&CK nous pouvons avoir le visuel « Tactics matrix view » ainsi les méthodes utilisées sont mises en avant via une couleur différente :
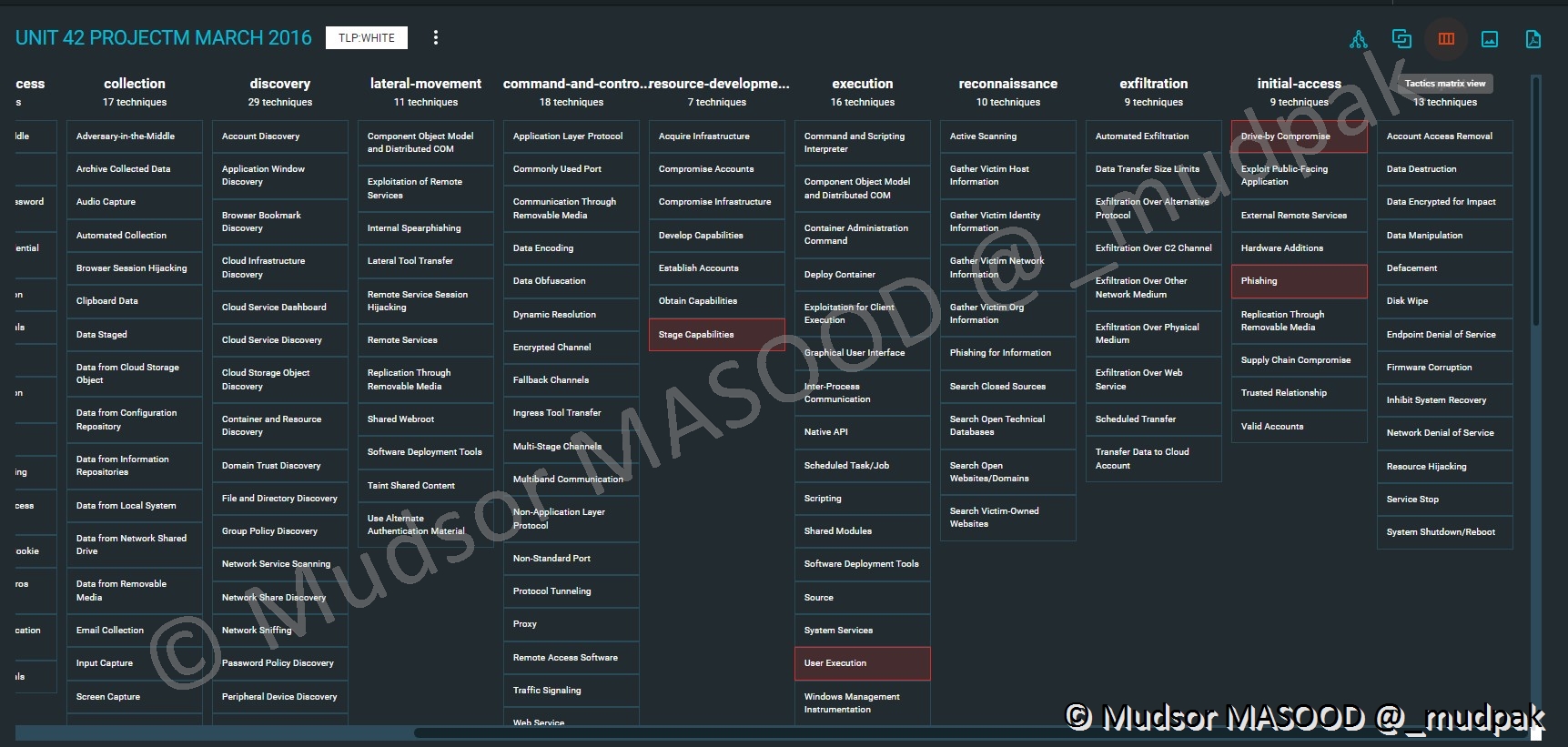
Quel que soit le visuel choisi nous pouvons exporter l’affichage en image :
Nous pouvons choisir parmi les différents types d’exports :
Il est également possible d’exporter le rapport au format PDF :
En plus du menu dans la zone supérieure, nous avons le menu de la zone inférieur qui permet d’effectuer d’autres opérations.
Nous pouvons afficher les relations sous forme 3D :

Voici un exemple de résultat qu’on peut obtenir :
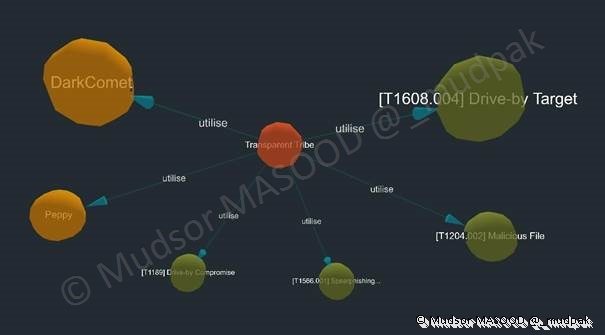
Par défaut le mode « tree » est activé sur les relations mais comme nous l’avons vu plus haut il est possible de changer pour un format plus adapté au besoin.

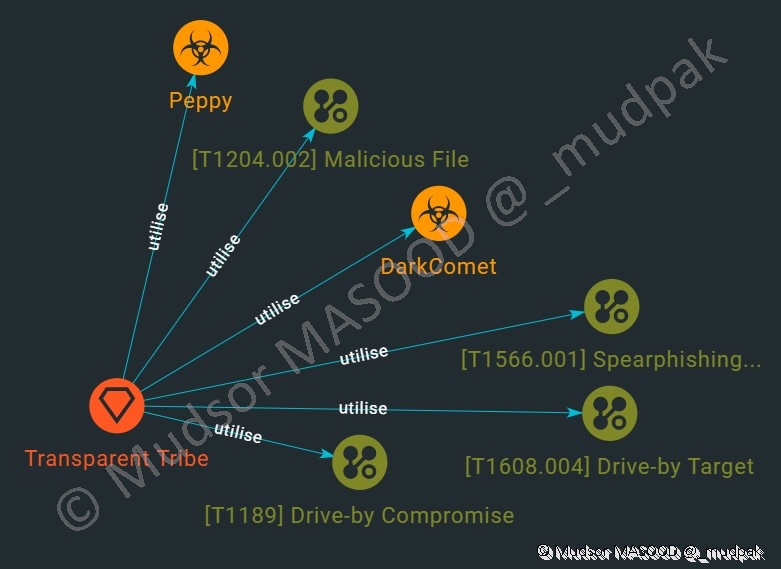
Nous pouvons visualiser les relations avec un modèle vertical :

Voici un exemple de résultat obtenu :
Il est possible de « désactiver les forces » chose que je vous déconseille car si vous déplacez les relations vous risquez de la superposer et puisque cette fonctionnalité n’est pas activée vous risquez de masquer des éléments :

Vous pouvez « Afficher le sélecteur d’intervalle de temps » qui permet de connaitre la date exacte d’ajout de chaque élément au rapport !
En réalité il est possible de connaitre cette date en sélectionnant un élément, mais l’avantage du sélecteur est qu’il affiche un cercle de taille proportionnelle aux changements effectués comme nous pouvons le voir ci-dessous :

Pour adapter l’affichage du graphe sur la fenêtre, on peut opter pour « Dimensionner le graphe à l’espace » ainsi le graphe sera affiché sur toute la fenêtre :

Si vous faites des opérations sur les relations, il se peut que l’affichage de celles-ci ne soit plus à celui d’origine, pour remettre à l’état d’origine les relations nous pouvons choisir d’utiliser la fonctionnalité « Libérer les nœuds et réappliquer les forces » :

Nous pouvons « Filtrer les types d’entité » via ce filtre, voici les trois filtres proposés :
- Code malveillant
- Mode opératoire
- Motif d’attaque

Si vous souhaitez « Filtrer les marquages » vous pouvez le faire via ce filtre, selon les types de marquages du rapport il vous sera possible de ne pas les afficher :

De la même manière que les précédents filtres, il est possible de « Filtrer les auteurs (crée par) » pour afficher ou non les auteurs du rapport :

Il est possible de « Sélectionner par type » les relations, voici les différents types :
- Code malveillant
- Mode opératoire
- Motif d’attaque

Pour ne pas avoir à sélectionner tous les nœuds un à un ou par types, nous pouvons tous les sélectionner via cette fonctionnalité :

Sur cette page nous avons vu quasiment tous les éléments, il reste les options disponibles dans la zone inférieur droite de la fenêtre lorsque nous sélectionnant un élément du rapport :

La première option permet d’ « Ajouter une entité à ce conteneur » :
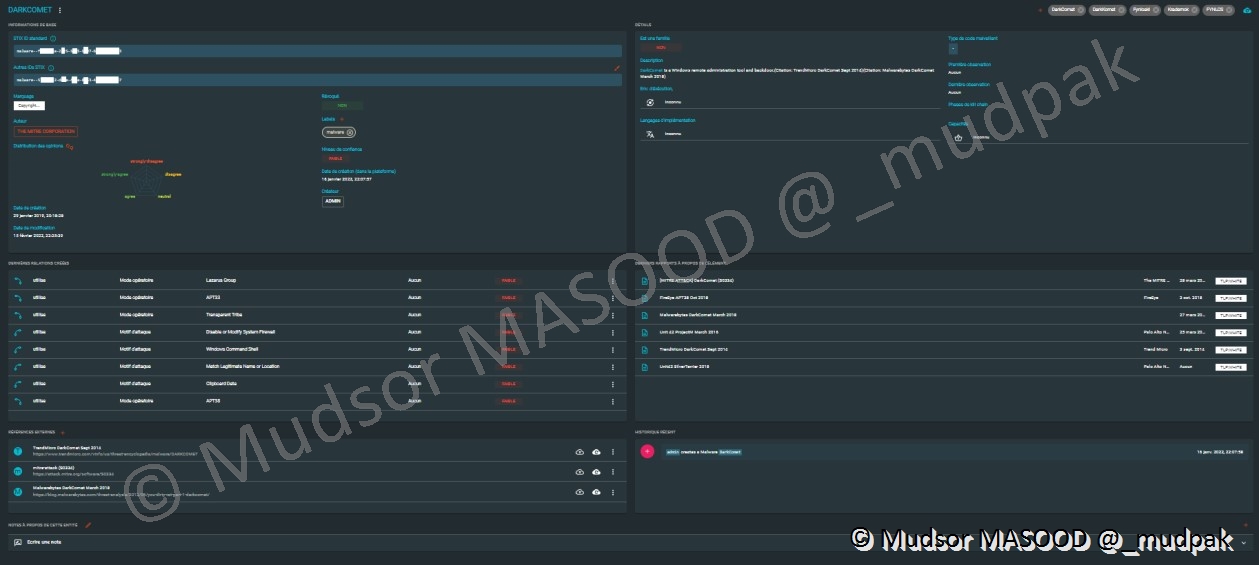
La seconde option permet de « Voir l’object », c’est-à-dire que nous serons redirigés vers une page avec tous les détails de l’élément sélectionné :

De la même manière qu’un « rapport » nous avons toutes les informations que l’élément :
Si vous sélectionnez au moins deux éléments il vous sera possible de « Créer une relation » entre ces éléments :
La dernière option permet de supprimer un ou plusieurs éléments sélectionnés :
Jusqu’à ce stade nous n’avons parcouru « que » deux sous menus de la partie « Analyses », avec ces éléments nous avons déjà beaucoup d’éléments qui nous permettent de faire notre CTI.
Mais pour compléter notre travail d’autres sous-menus vont nous aider.
Dans le menu « Contenu » nous avons la possibilité d’ajouter du contenu au rapport par différentes méthodes :
- EDITEUR ENRICHI : un éditeur de texte pour ajouter des éléments
- SOURCE MARKDOWN : non actif à cet instant
- VISUALISEUR PDF : non fonctionnel à cet instant
Dans le menu « Entités » nous retrouvons les mêmes informations que précédemment depuis la matrice MITRE ATT&CK ou d’autres visuels des relations car les données sont les mêmes mais représentées différemment :
Dans la partie « Observables » doivent apparaitre les éléments en relation avec le rapport :

Ces observables peuvent être de différents types, voici une liste réduite de types d’observables :
Dans le dernier menu « Données » nous pouvons voir les dates des mises à jour des données du rapport :
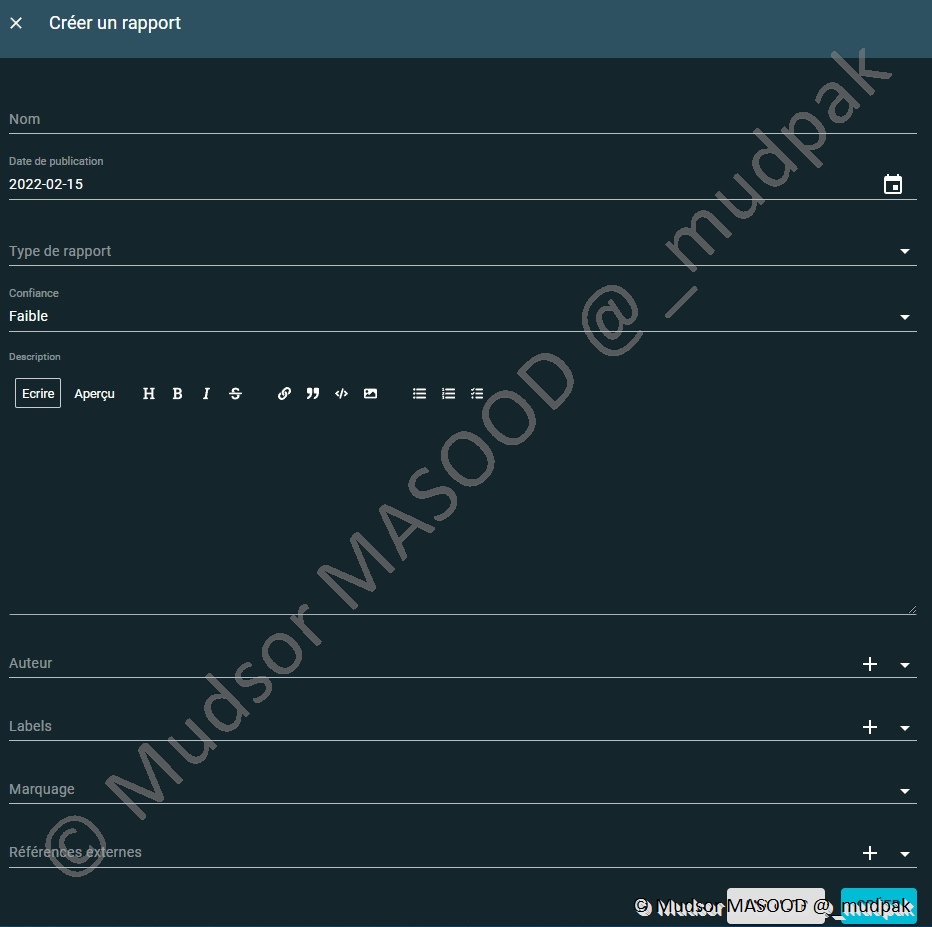
Au vu des éléments que nous fournissent les rapports de différents types de ressources, si le résultat ne vous satisfait pas il est également possible de créer des rapports manuellement.
Tout comme pour les rapports existants vous pouvez appliquer les mêmes changements sur ces rapports.
Pour cela il faut renseigner les champs suivants :
- Nom : le nom qui sera affiché
- Date de publication : date à laquelle publier le rapport
- Type de rapport : est-ce que c’est un rapport interne ou sur une menace ?
- Confiance : le niveau de confiance accordé entre (aucun, faible, modéré, bon et fort) • Description : détails qu’on souhaite ajouter au rapport
- Auteur
- Quelle entité est à l’origine de ce rapport ?
- Vous pouvez créer des entités personnalisées comme nous le verrons par la suite
- Labels : labels qui correspondent au rapport
- Marquage : sur quel niveau de du protocole TLP (White, Green, Amber ou Red) se situe la criticité de ce rapport
- Références externes : si vous souhaitez ajouter des références externes pour compléter le rapport
10.3.1.2 Notes
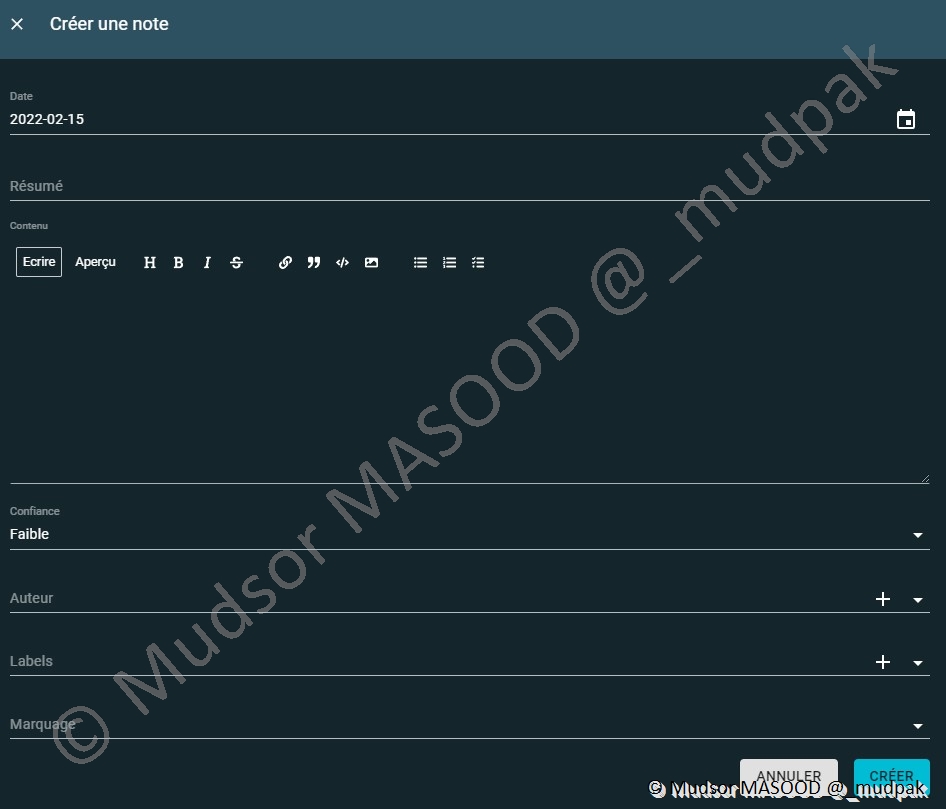
Si vous revenons dans le menu « Notes » nous pouvons visualiser les notes s’il y en a :

Nous pouvons créer des notes en renseignant les champs suivants :
- Date : date de création de la note
- Résumé : descriptif rapide de la note
- Contenu : détails de la note
- Confiance
- Auteur
- Labels
- Marquage
10.3.1.3 Opinions
De la même manière que les notes nous pouvons visualiser les « Opinions » dans ce menu :

S’il n’en existe pas nous pouvons en créer en remplissant les champs suivants :
- Opinion : type d’opinion (strongly-disagree, disagree, neutral, agree, strongly-agree) • Explication : raisons de l’opinion
- Auteur
- Labels
- Marquage

10.3.1.4 Références externes
Comme nous l’avons vu précédemment dans les rapports une partie « Références externes » permet de rassembler des liens qui mènent à des ressources pour compléter notre analyse ou servent de sources.
Nous pouvons retrouver ces éléments dans ce menu :
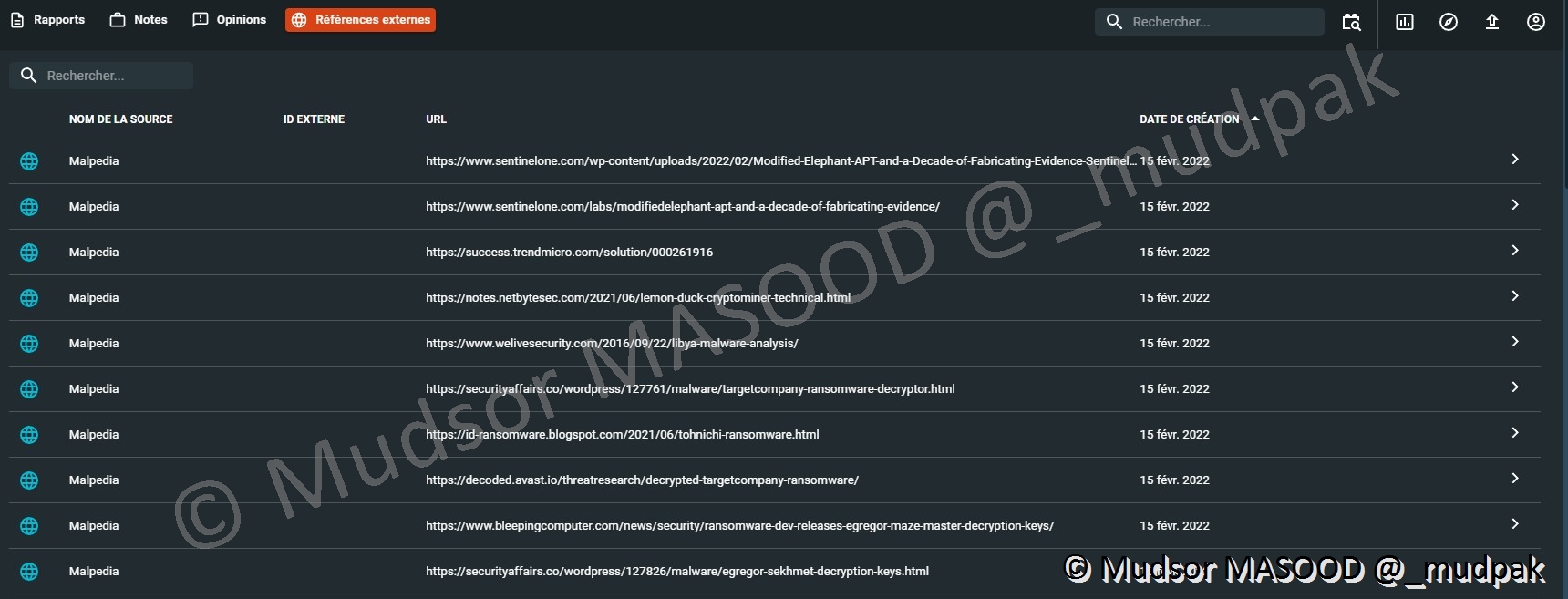
Si vous souhaitez créer une référence manuellement il est tout à fait possible en remplissant les champs suivants :
- Nom de la source : le nom que vous souhaitez donner à cette référence
- ID externe : si vous souhaitez attribuer un identifiant à cette référence
- URL : lien qui mène vers la référence
- Description : détails sur la référence
- Choisir un fichier … : vous pouvez joindre un fichier
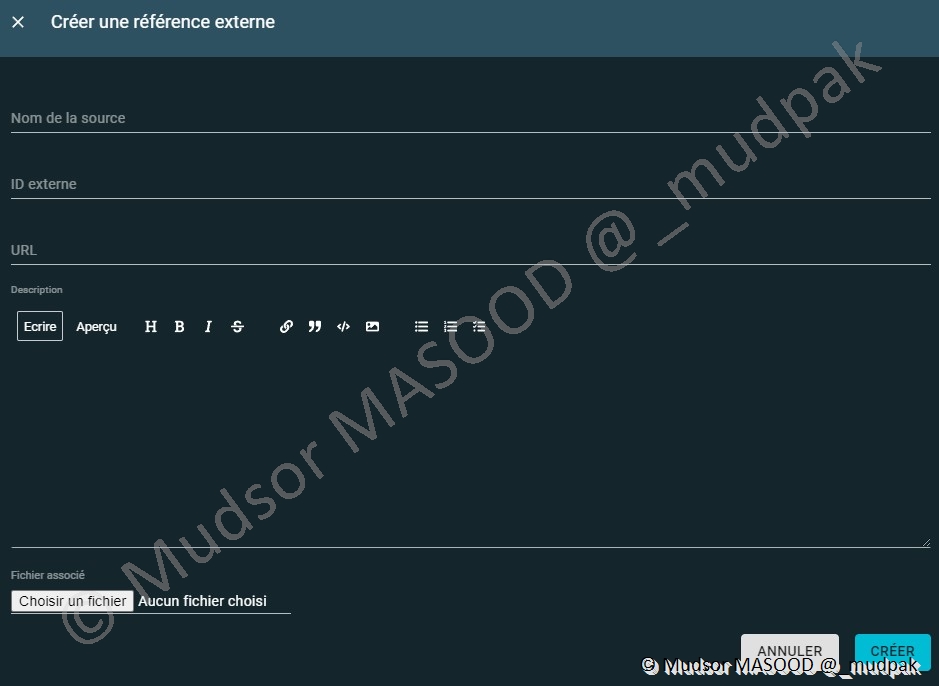
10.3.2 Evènements
Les évènements peuvent être de différents types :
- Incidents
- Détections
- Données observées

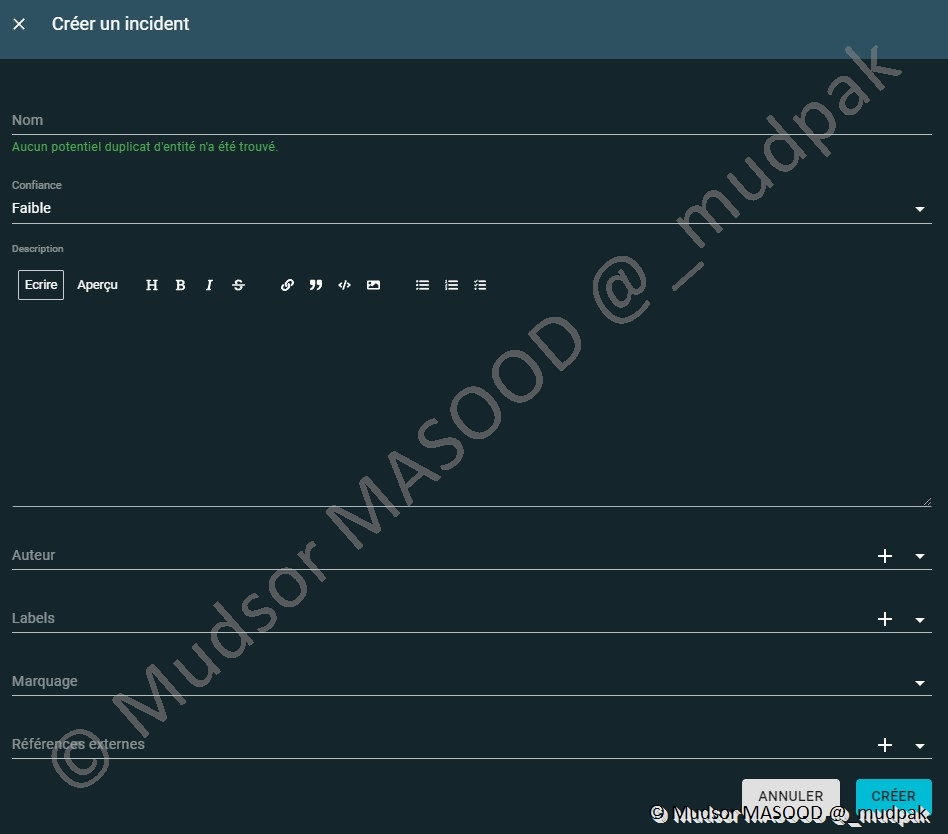
10.3.2.1 Incidents

Pour créer un incident il faut remplir les champs suivants :
- Nom
- Confiance
- Description
- Auteur
- Labels
- Marquage
- Références externes
10.3.2.2 Détections

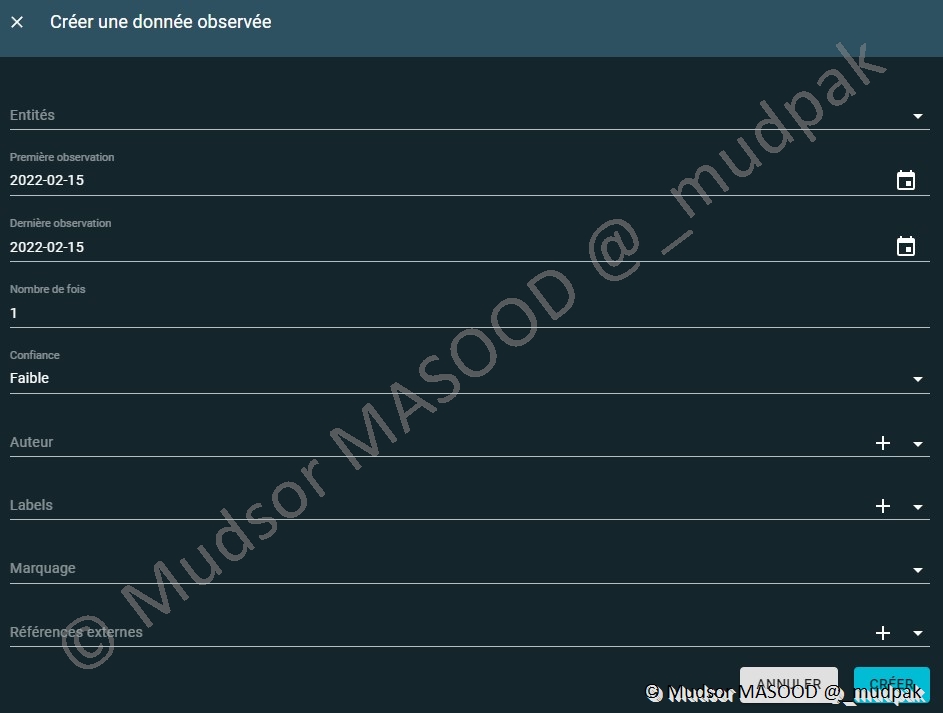
10.3.2.3 Données observées

Pour créer une donnée observée, il faut remplir les champs suivants :
- Entités
- Première observation
- Dernière observation
- Nombre de fois
- Confiance
- Auteur
- Labels
- Marquage
- Références externes
10.3.3 Observations
Il y a différents types d’observables
- Observables
- Artefacts
- Indicateurs
- Infrastructures

10.3.3.1 Observables
La liste des observables est disponible à cet endroit, on peut les trier via différentes colonnes :
- Type
- Valeur
- Labels
- Date de création
- Marquage
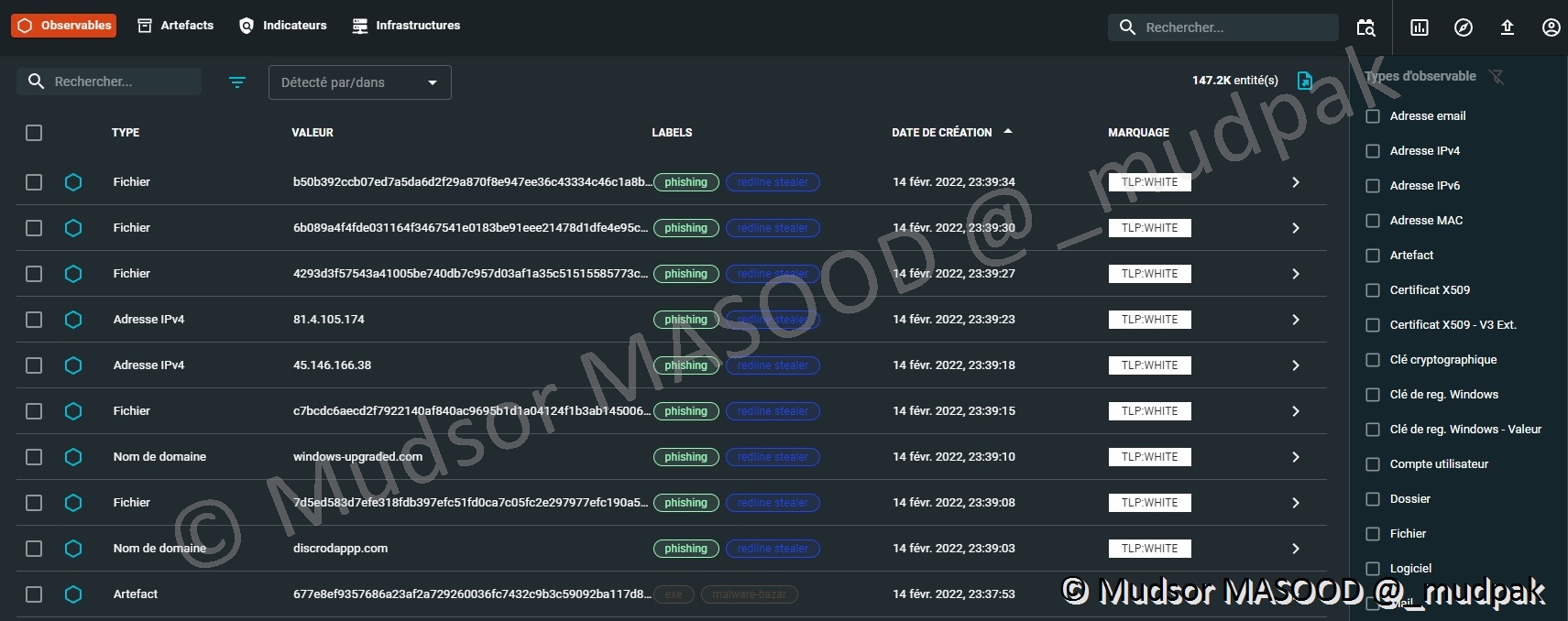
Voici un extrait de types d’observables :
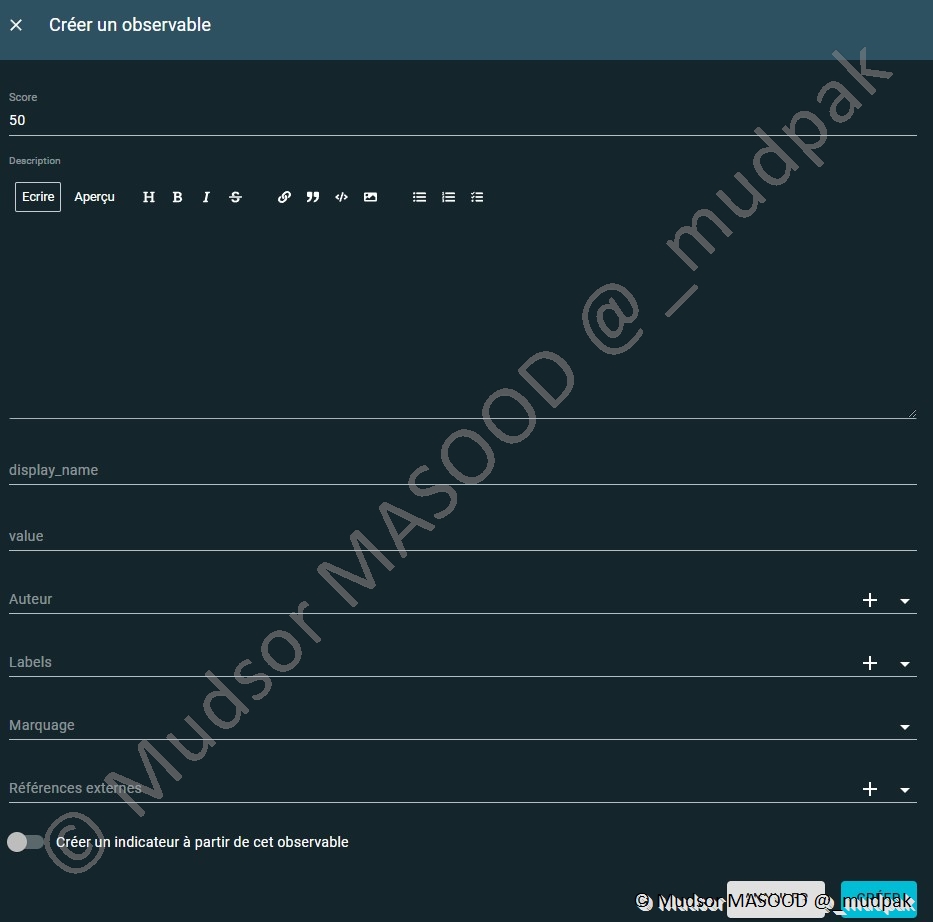
Pour créer un observable il faut remplir les champs suivants :
- Score
- Description
- Display_name : nom d’affichage
- Value : la valeur à attribuer
- Auteur
- Labels
- Marquage
- Références externes
10.3.3.2 Artefacts
Les artefacts peuvent être triés via les colonnes suivantes :
- Valeur
- Nom de fichier
- MIME/TYPE
- File size
- Labels
- Date de création
- Marquage
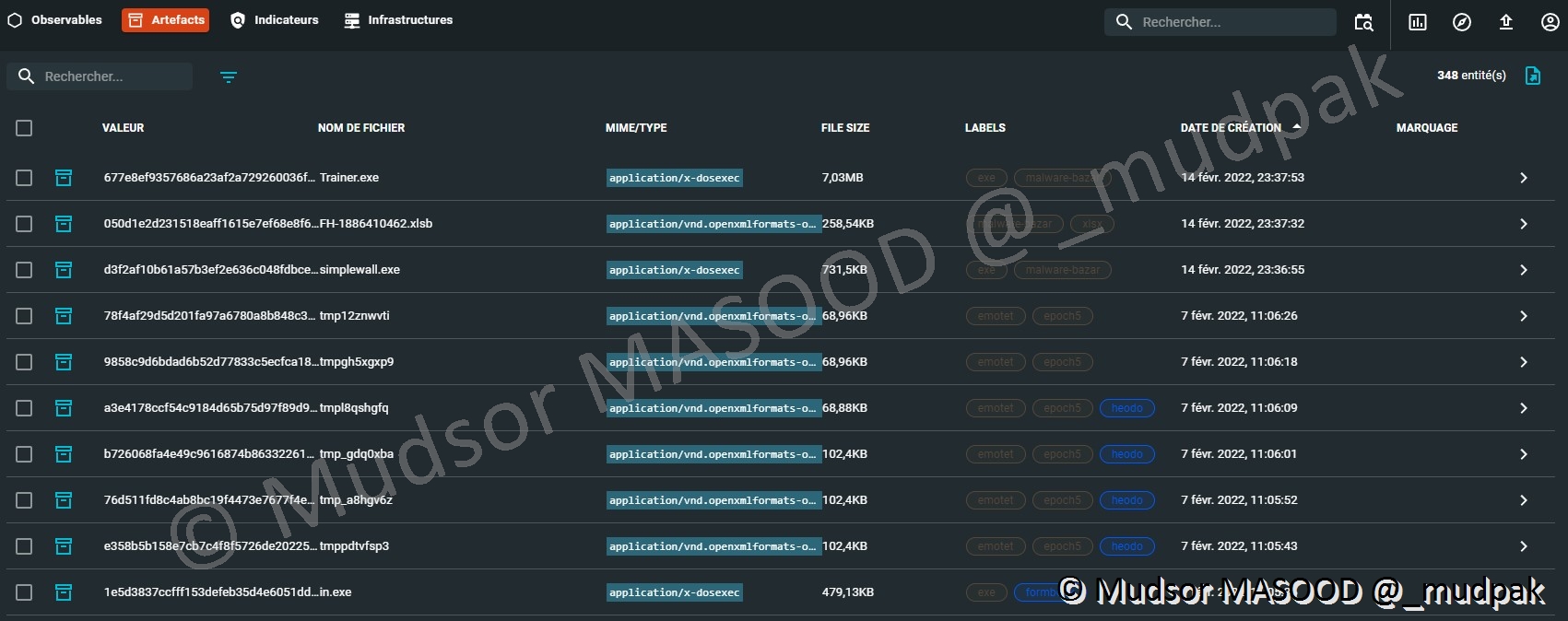
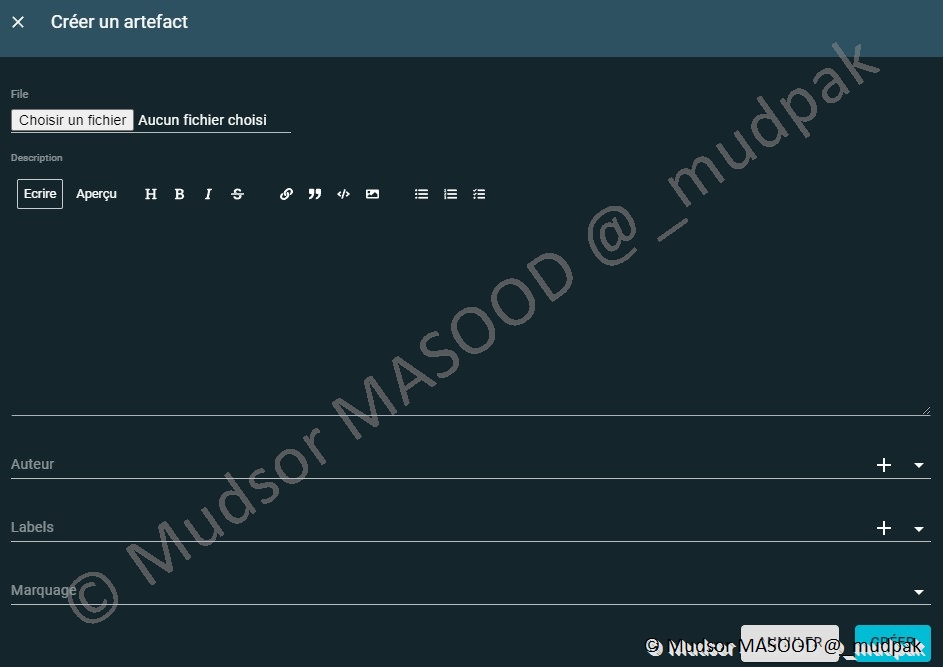
Pour créer un artefact il faut remplir les champs suivants :
- Choisir un fichier : qui sera l’artefact
- Description
- Auteur
- Labels
- Marquage
10.3.3.3 Indicateurs
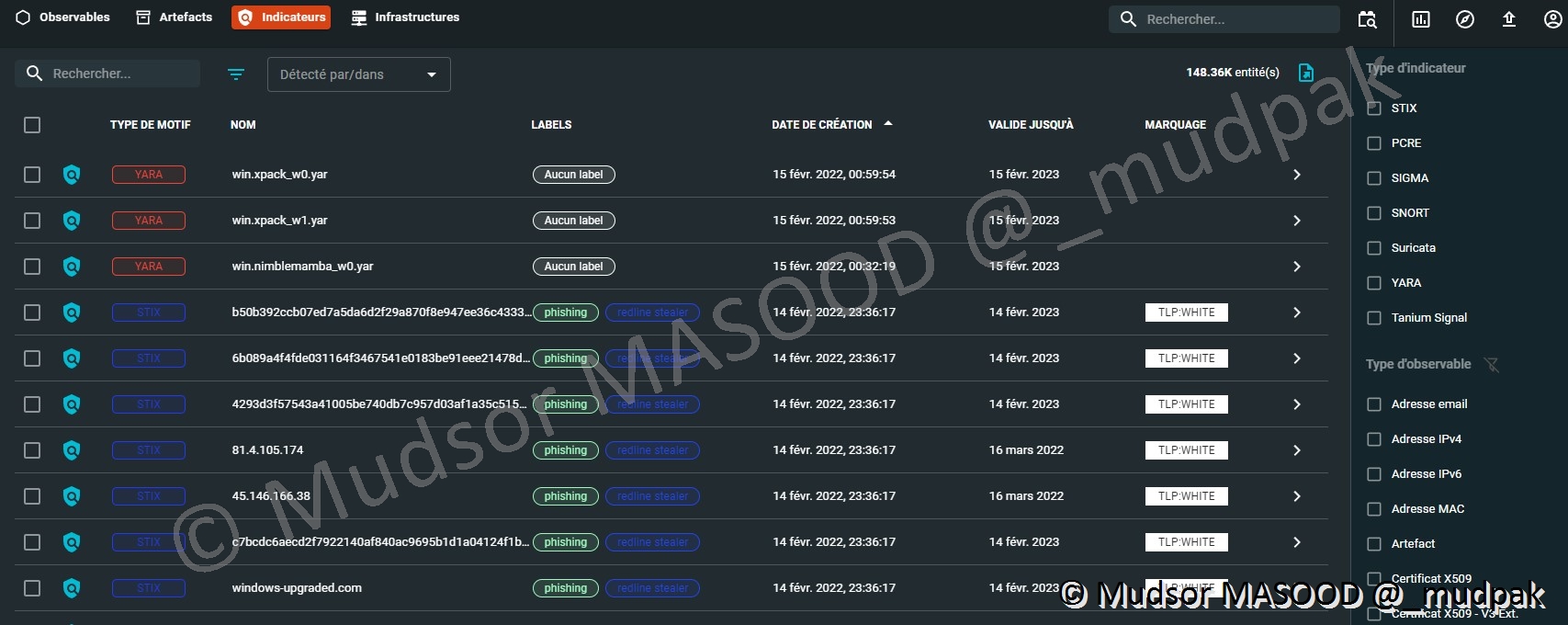
Les indicateurs peuvent être triés via les colonnes suivantes :
- Type de motif
- Nom
- Labels
- Date de création
- Valide jusqu’à
- Marquage
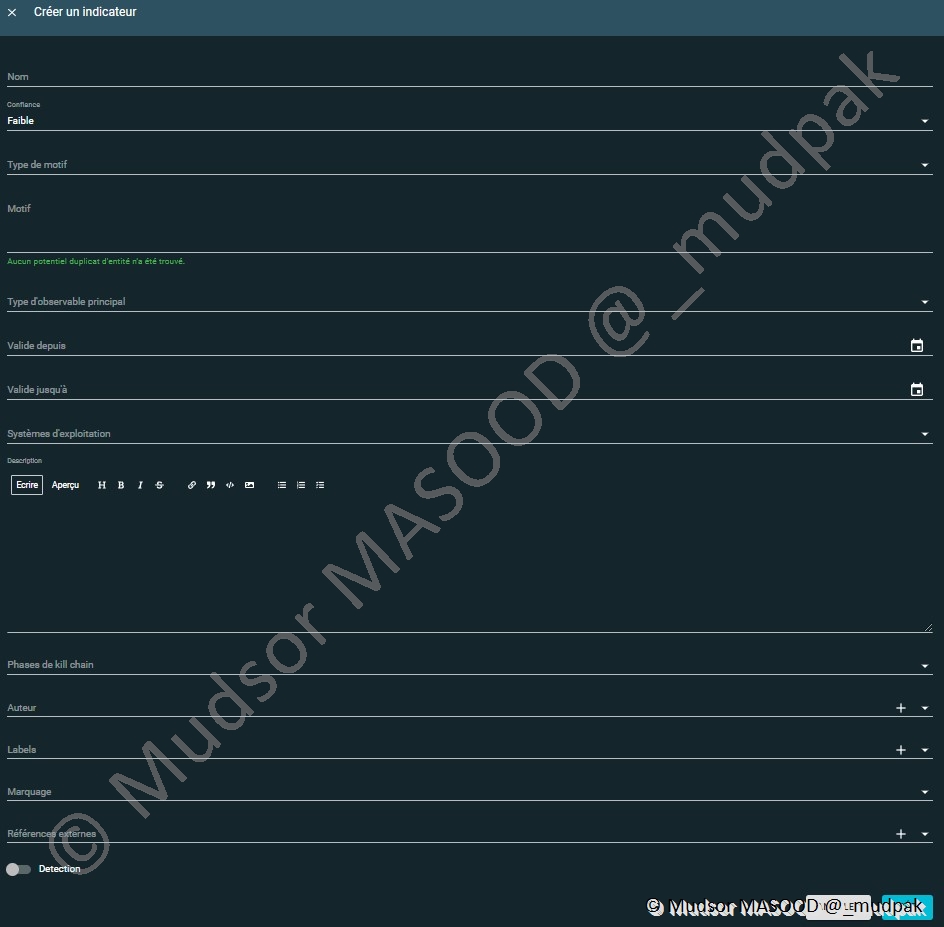
Il est possible de créer un indicateur en remplissant les champs suivants :
- Nom
- Confiance
- Type de motif
- STIX
- PCRE
- SIGMA
- SNORT
- Suricata
- YARA
- Tanium Signal
- Type d’observable principal : Parmi une longue liste de choix (adresse email, IPv4, IPv6, Fichier, URL …)
- Valide depuis
- Valide jusqu’à
- Système d’exploitation
- Android
- MacOS
- Linux
- Windows
- Description
- Phases de kill chain : sur quelle phase de la cyber kill chain se trouve cet élément
- Auteur
- Labels
- Marquages
- Références externes
10.3.3.4 Infrastructures

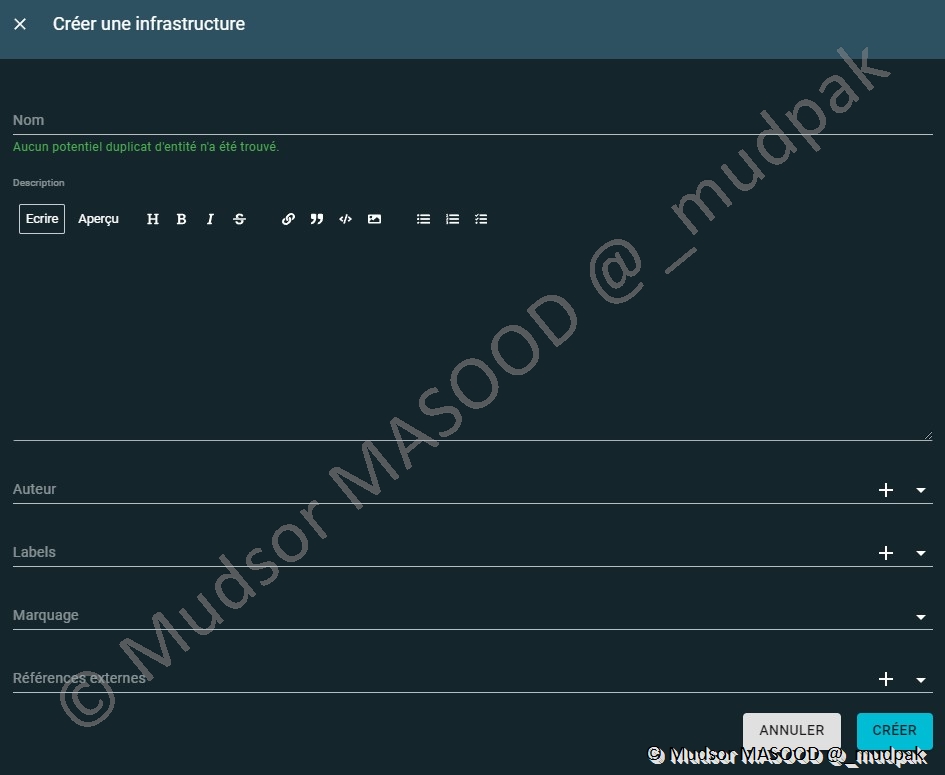
Pour créer une infrastructure il faut remplir les champs suivants :
- Nom
- Description
- Auteur
- Labels
- Marquage
- Références externes
10.4 Connaissances
Il y a différents types de connaissances
- Menaces
- Arsenal
- Entités
10.4.1 Menaces
Il y a différents types de menaces
- Acteurs
- Modes opératoires
- Campagnes

10.4.1.1 Acteurs

Pour créer un acteur il faut remplir les champs suivants :
- Nom
- Type d’acteur : choisir parmi la liste proposée (activiste, concurrent, hacker …)
- Confiance
- Description
- Auteur
- Labels
- Marquage
- Références externes
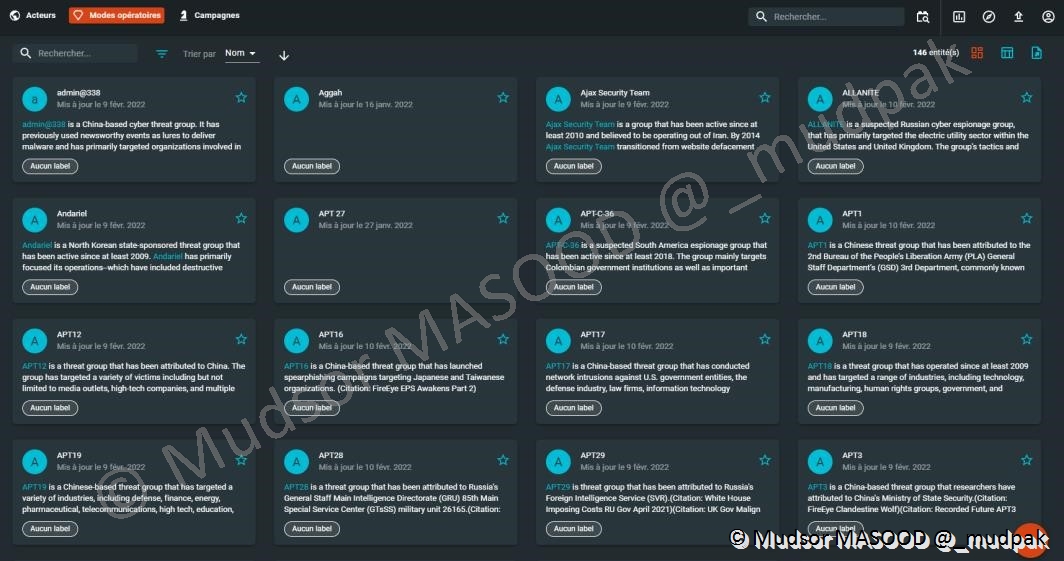
10.4.1.2 Modes opératoires
Les modes opératoires recensent les TTPs utilisés par les différents attaquants, ils sont consultables sous formes de rapports :
Pour créer un mode opératoire il faut remplir les champs suivants :
- Nom
- Confiance
- Description
- Auteur
- Labels
- Marquage
- Références externes
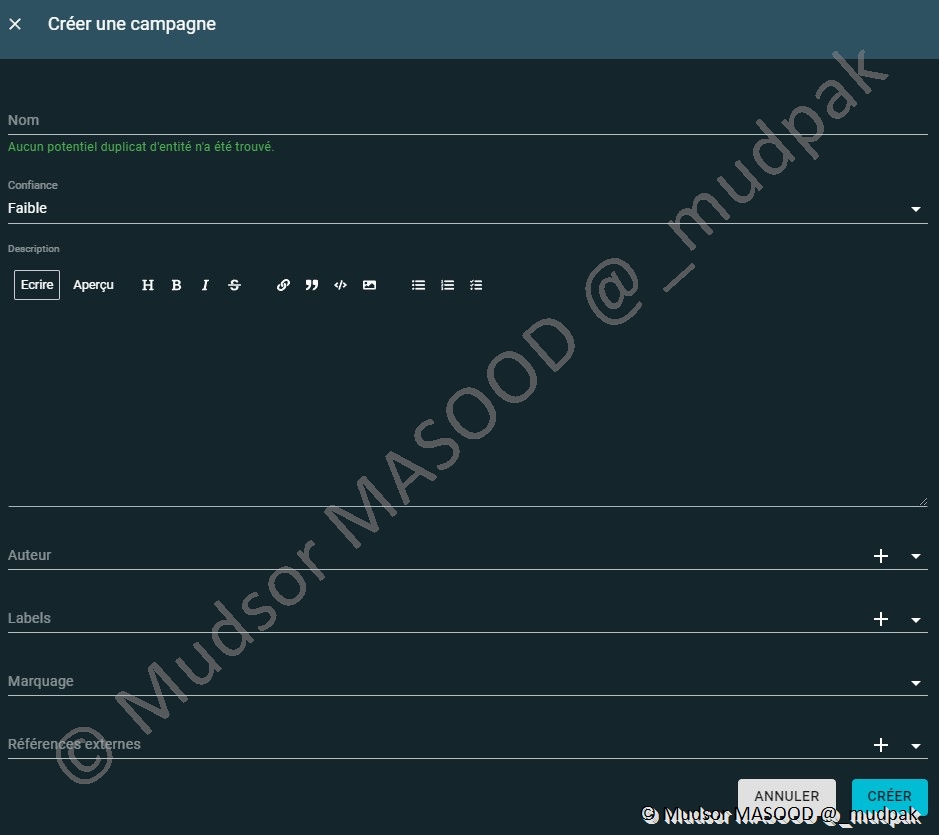
10.4.1.3 Campagnes

Pour créer des campagnes il faut remplir les champs suivants :
- Nom
- Confiance
- Description
- Auteur
- Labels
- Marquage
- Références externes
10.4.2 Arsenal
Il y a différents types d’éléments dans la catégorie Arsenal :
- Codes malveillants
- Motifs d’attaque
- Conduites à suivre
- Outils
- Vulnérabilités

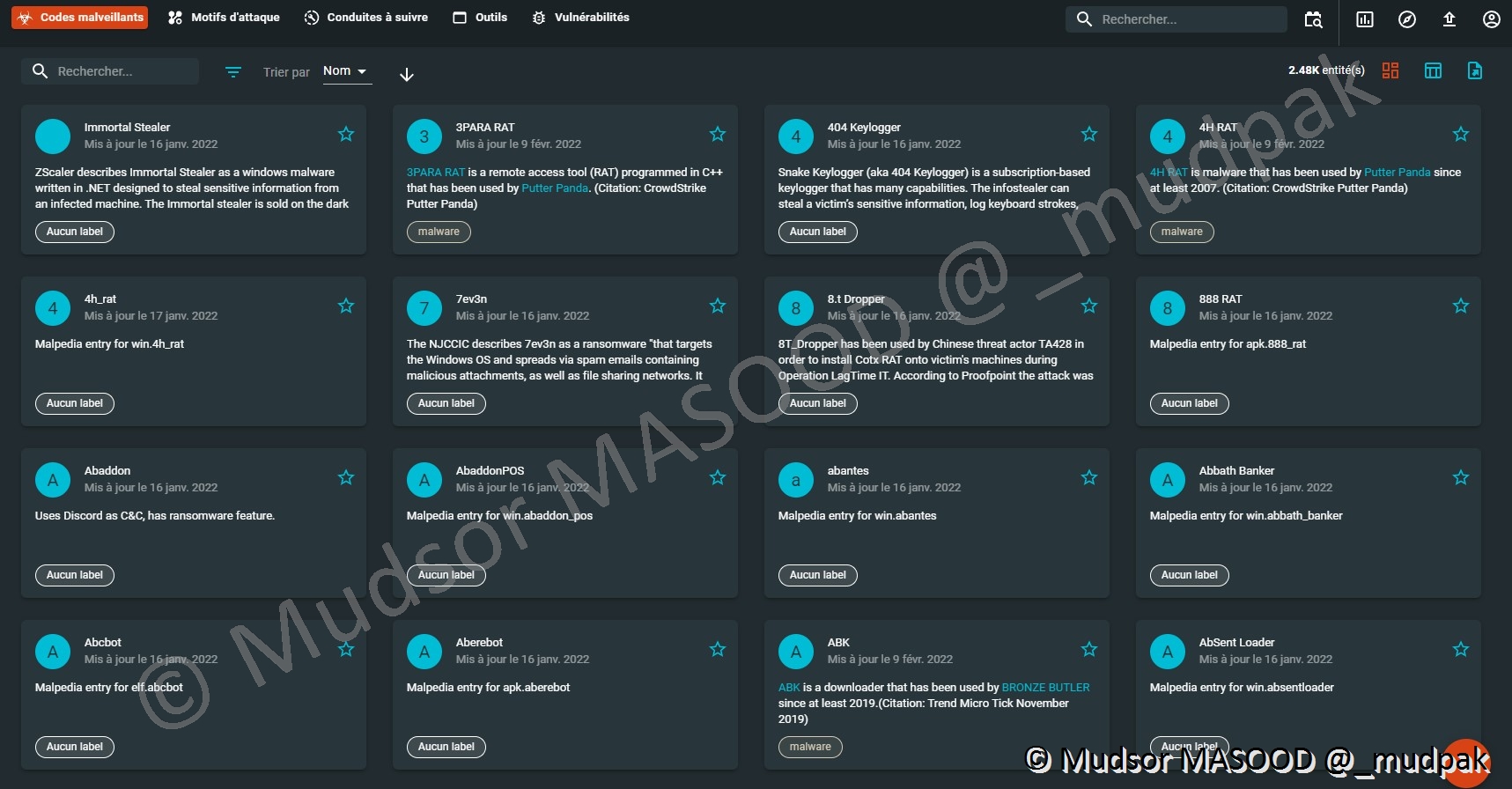
10.4.2.1 Codes malveillants
Cette catégorie recense les codes utilisés par les acteurs malveillants :
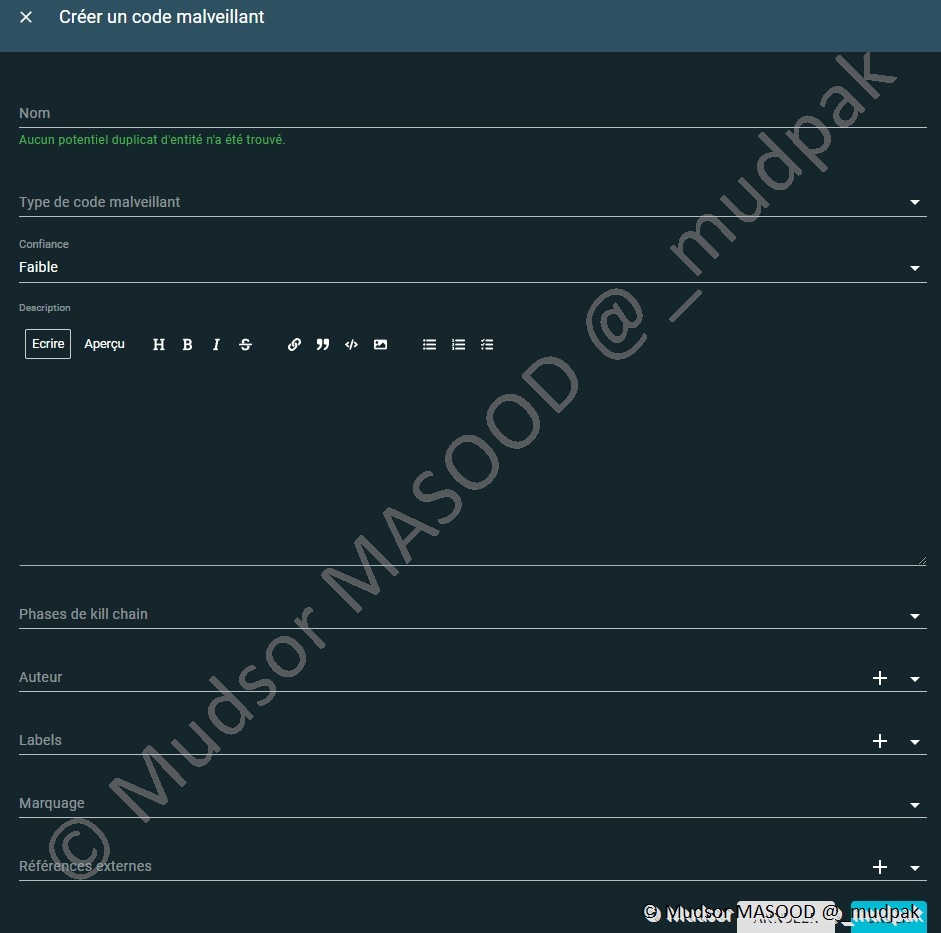
Pour ajouter un élément de type code malveillant, il faut remplir les champs suivants :
- Nom
- Type de code malveillant : choisir parmi la liste proposée (adware, backdoor, bot…)
- Confiance
- Description
- Phases de kill chain
- Auteur
- Labels
- Marquage
- Références externes
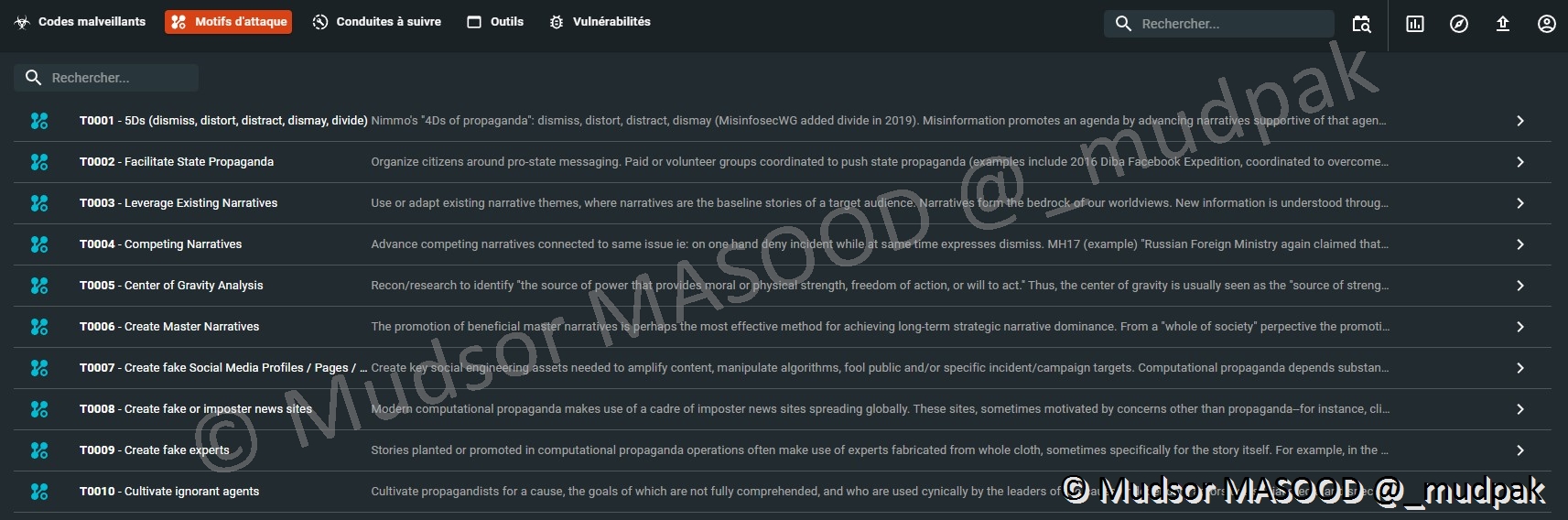
10.4.2.2 Motifs d’attaques
Les motifs d’attaques sont les TTPs présents dans la matrice MITRE ATT&CK :
Pour ajouter un nouveau motif d’attaque il faut remplir les champs suivants :
- Nom
- ID externe : c’est l’identifiant issue de la MITRE ATT&CK de l’élément
- Description
- Phases de kill chain
- Auteur
- Labels
- Marquage
Exemple :
« Active Scanning » correspondant à la référence suivante : https://attack.mitre.org/techniques/T1595/ et l’ID associé est « T1595 »
10.4.2.3 Conduites à suivre
Cette partie très importante pour la partie remédiation permet de proposer des mesures correctives face à des menaces :
Pour ajouter une conduire à suivre il faut remplir les champs suivants :
- Nom
- Description
- Auteur
- Labels
- Marquage
10.4.2.4 Outils
Dans cette partie sont recensés les outils qui ont été trouvés durant les attaques, et une page de rapport leur est dédiée pour donner plus de détails notamment sur les attaques durant lesquels ils ont été détectés / utilisés :
Pour ajouter un outil il faut remplir les champs suivants :
- Nom
- Description
- Phases de kill chain
- Auteur
- Labels
- Marquage
- Références externes
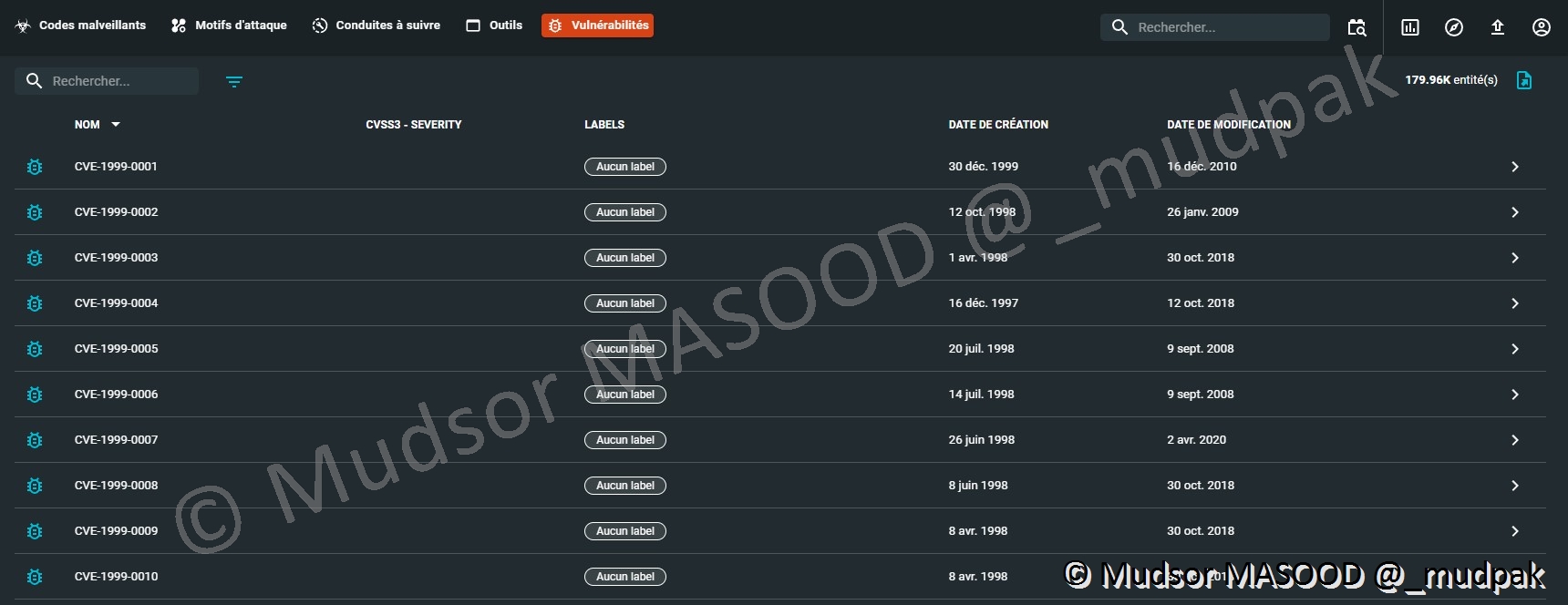
10.4.2.5 Vulnérabilités
Cette partie recense les vulnérabilités qui ont été exploitées par les attaquants :
Pour ajouter une vulnérabilité il faut remplir les champs suivants :
- Nom
- CVSS3 – Score : le score correspondant à la vulnérabilité avec l’échelle CVSS3
- CVSS3 – Severity : le niveau de criticité correspondant à la vulnérabilité avec l’échelle CVSS3
- CVSS3 – Attack vector : le vecteur d’attaque utilisé en se basant sur l’échelle CVSS3
- Auteur
- Labels
- Marquage
10.4.3 Entités
Il y a différents types d’entités
- Secteurs
- Pays
- Villes
- Positions
- Organisations
- Systèmes
- Individus

Parmi la liste ci-dessus on peut s’étonner de voir des villes, positions, et mêmes individus !
Tout dépend de votre type de CTI, mais il est tout à fait possible de faire de la veille :
- Sur des villes : si une entreprise possède plusieurs filiales dans le même pays elle peut plus aisément attacher les rapports à chaque ville
- Sur des positions : pour des raisons spécifiques une entreprise peut avoir besoin de localiser de manière précise des positions
- Sur des individus : il n’est pas rare que les équipes cyber / sureté fassent de la veille sur les membres « VIP » d’une entreprise, donc il peut être pertinent de créer dans votre CTI des « individus » et avoir des « rapports » à leur sujet.
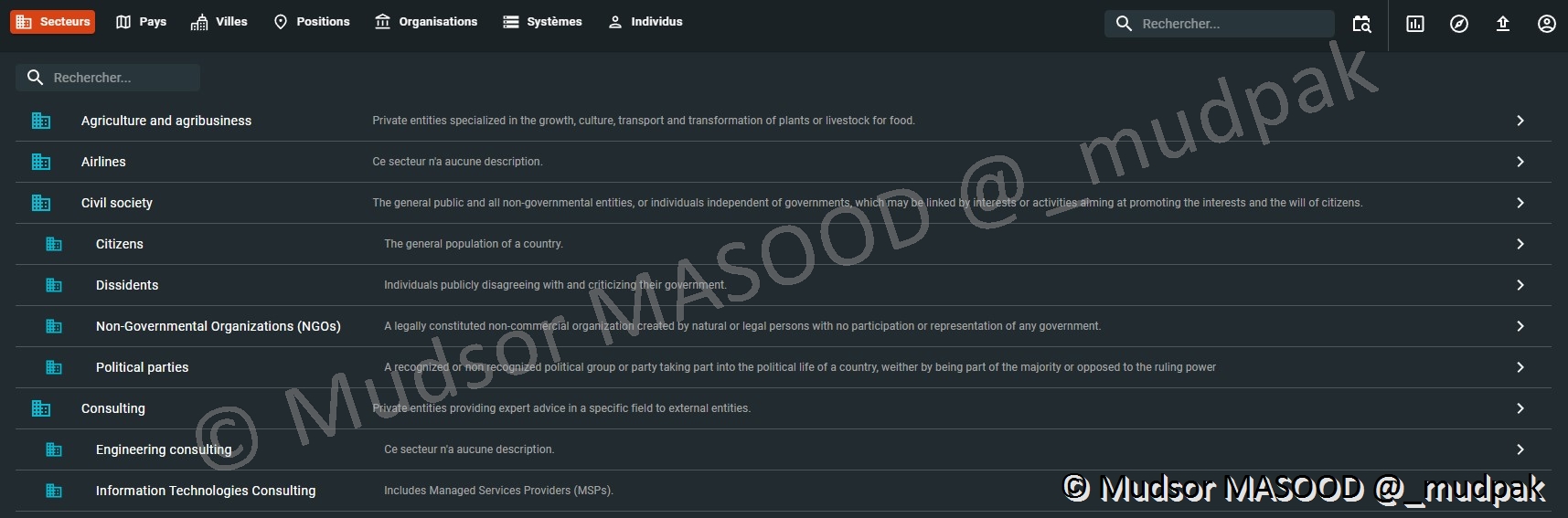
10.4.3.1 Secteurs
Une liste de secteurs est par défaut présente dans la plateforme :
Si vous souhaitez ajouter un secteur il faut remplir les champs suivants :
- Nom
- Description
- Auteur
- Marquage
- Références externes
10.4.3.2 Pays
La liste des pays du monde est présente par défaut :
Nous pouvons
- Créer un pays
- Créer une région
Pour créer un pays il faut remplir les champs suivants :
- Nom
- Description
- Auteur
- Marquage
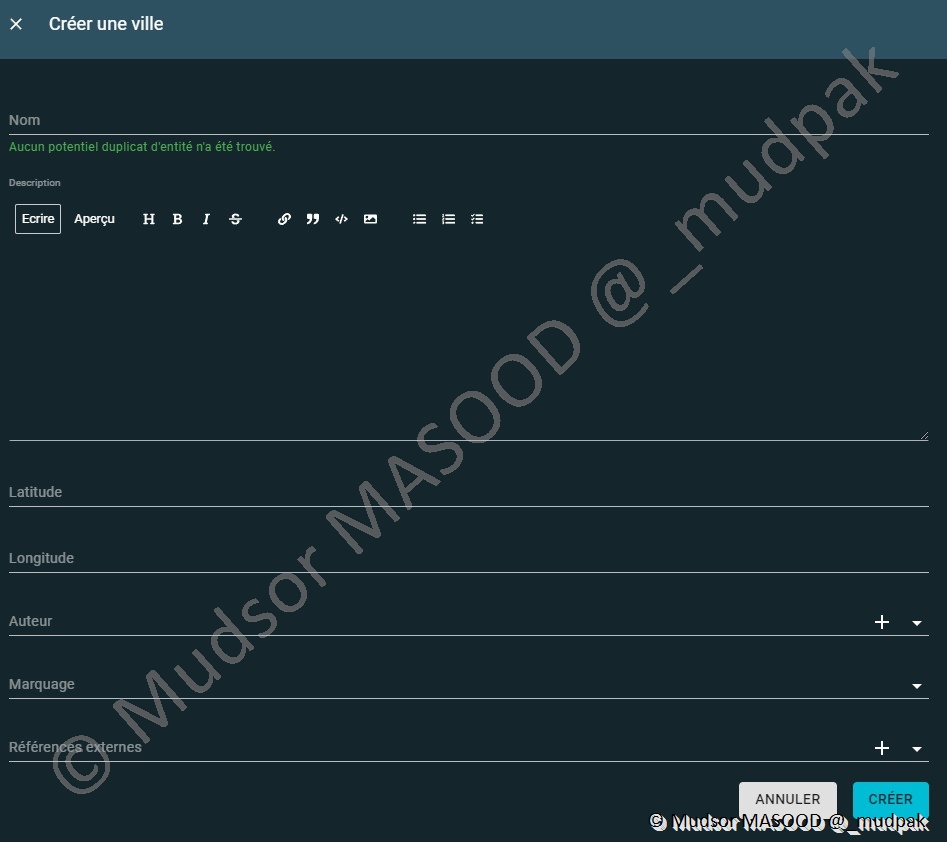
10.4.3.3 Villes
Par défaut il n’y a pas de villes présentes :

Si vous souhaitez ajouter une ville il faut remplir les champs suivants :
- Nom
- Description
- Latitude
- Longitude
- Auteur
- Marquage
- Références externes
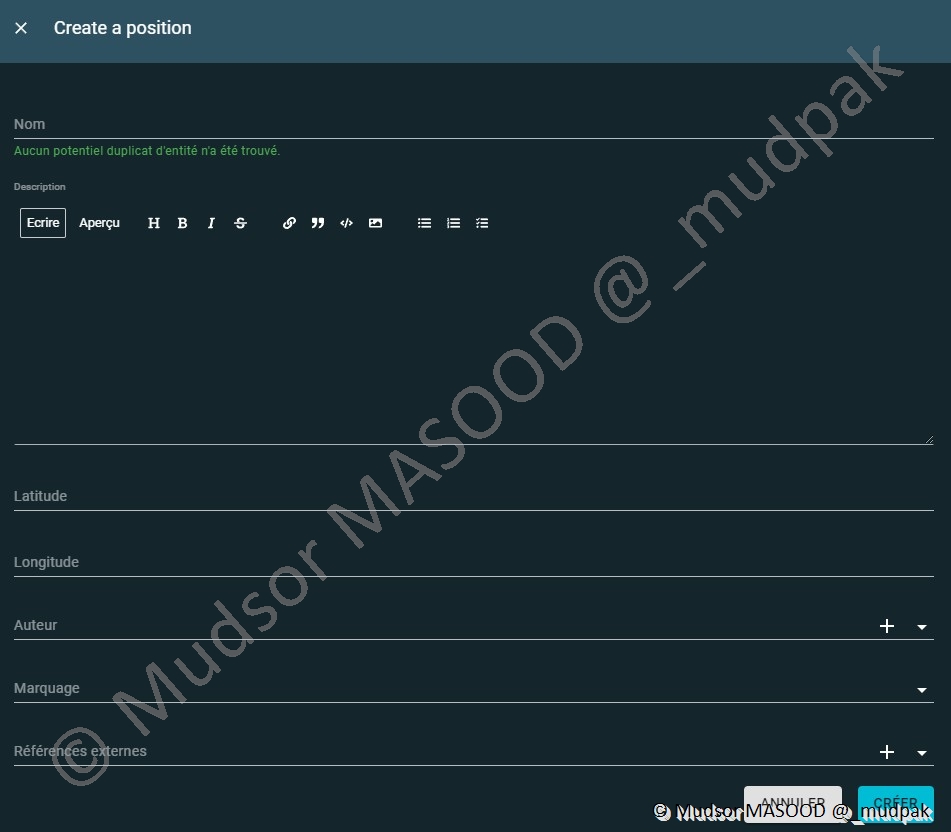
10.4.3.4 Positions
Si ce n’est pas une ville ou un pays alors on peut ajouter une position spécifique via ses coordonnées de latitude et longitude.

Pour ajouter une position il faut remplir les champs suivants :
- Nom
- Latitude
- Longitude
- Auteur
- Marquage
- Références externes
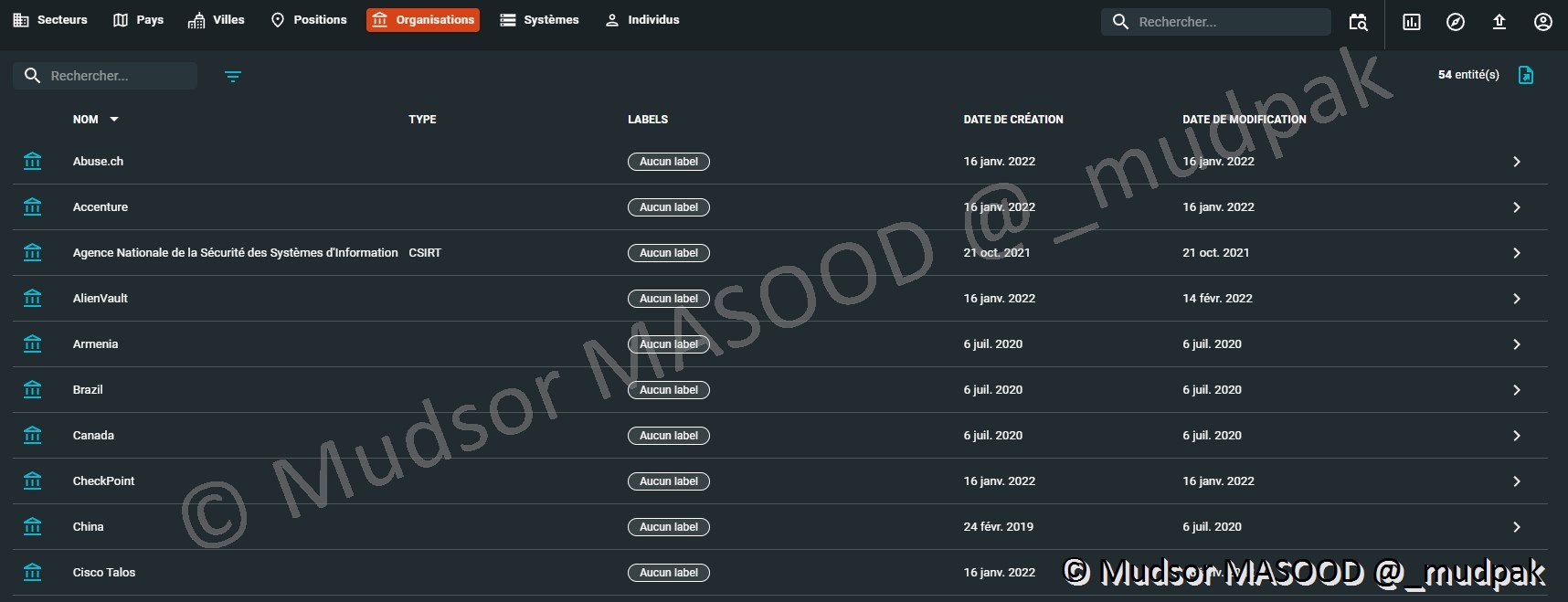
10.4.3.5 Organisations
La liste des organisations s’enrichit en même temps que les autres données lorsque des connecteurs sont ajoutés :
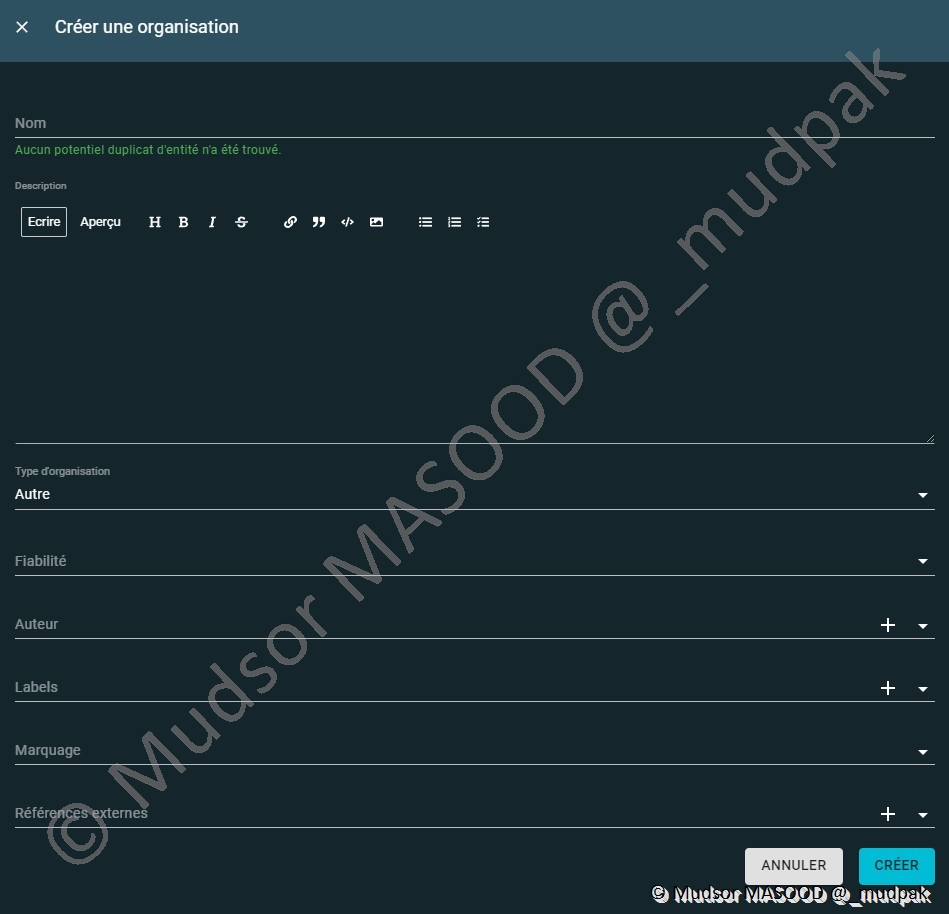
Pour ajouter manuellement une organisation il faut remplir les champs suivants :
- Nom
- Description
- Type d’organisation : choisir parmi la liste proposée (CSIRT, Partenaire, Editeur …)
- Fiabilité
- Auteur
- Labels
- Marquage
- Références externes
10.4.3.6 Systèmes

Pour ajouter un système il faut remplir les champs suivants :
- Nom
- Description
- Auteur
- Labels
- Marquage
- Références externes
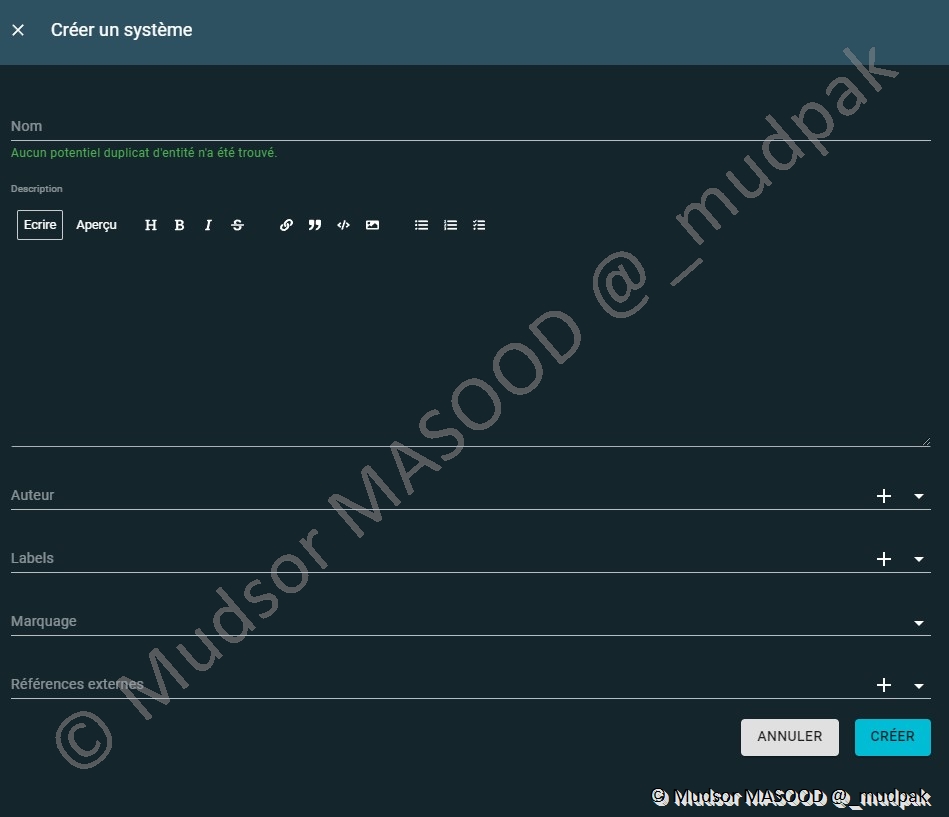
10.4.3.7 Individus
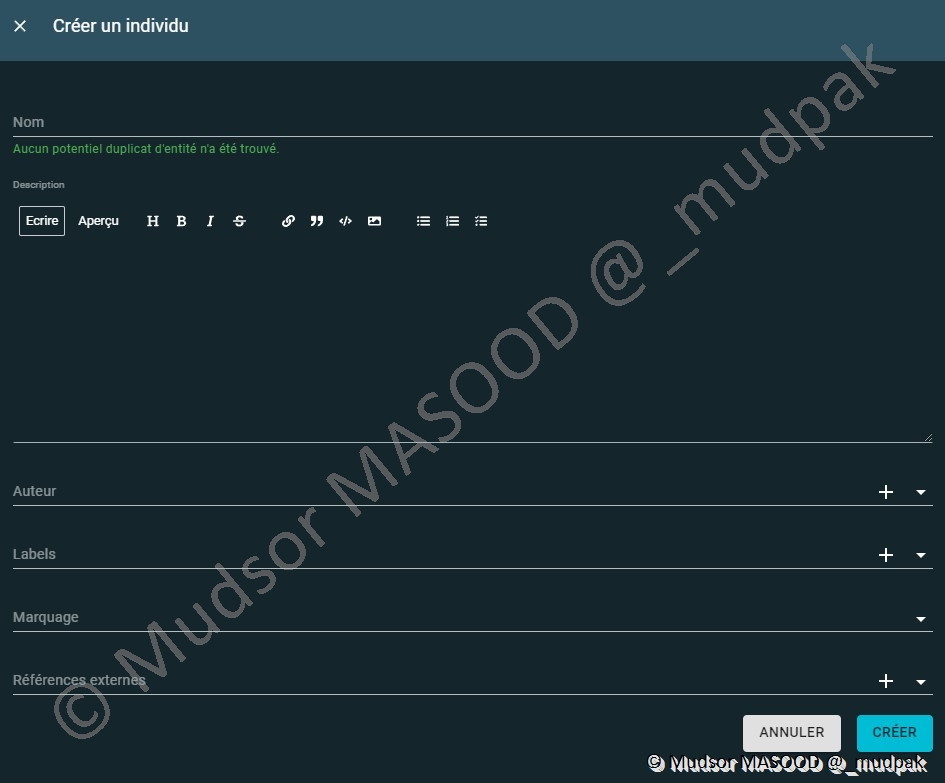
Par défaut il n’y a pas de liste d’individus :

Pour ajouter un individu il faut remplir les champs suivants :
- Nom
- Description
- Auteur
- Labels
- Marquage
- Références externes
10.5 Données
Dans ce menu se trouvent différents sous-menus :
- Entités
- Tâches de fond
- Connecteurs -Synchronisation
- Partage de données
- Collections TAXII

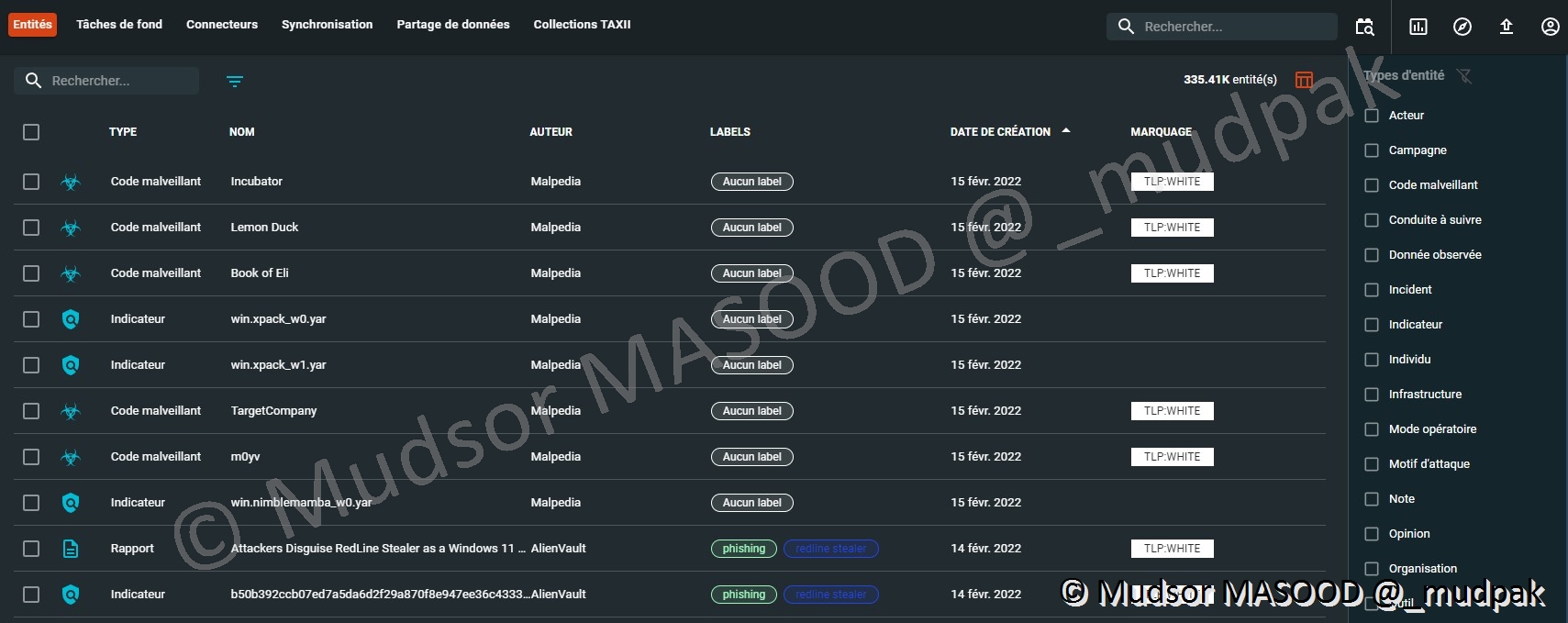
10.5.1 Entités
Représente toutes les données de la plateforme sans les relations, afin de pouvoir faire des opérations de masse.
10.5.2 Tâches de fond
Les tâches de fond sont consultables depuis ce menu :

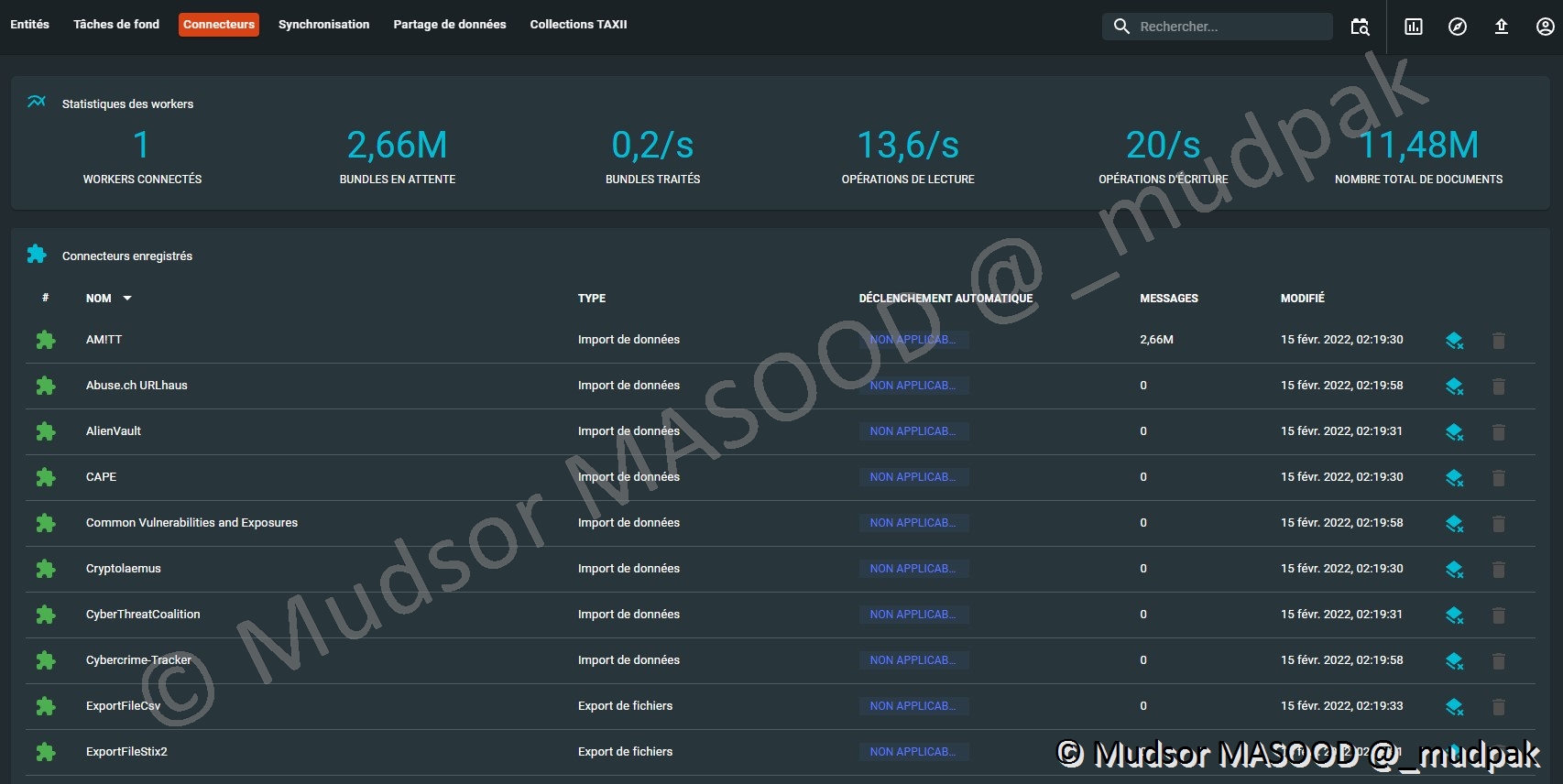
10.5.3 Connecteurs
Voici un des menus les plus importants de la plateforme ! En effet c’est depuis cet endroit que nous pouvons observer :
- Le nombre de Worker connectés
- Les bundles en attentes
- Les bundles traités
- Les opérations de lecture
- Les opérations d’écriture
- Le nombre total de documents
Mais au-delà de ces informations nous pouvons observer en temps réel la liste et l’état des connecteurs, notamment :
- Les noms des connecteurs
- Le type de connecteur
- Le type de déclenchement
- Le nombre de messages en attente d’import vers notre OpenCTI
- La date de la dernière modification apportée par le connecteur
- Réinitialiser l’état du connecteur
- Supprimer le connecteur
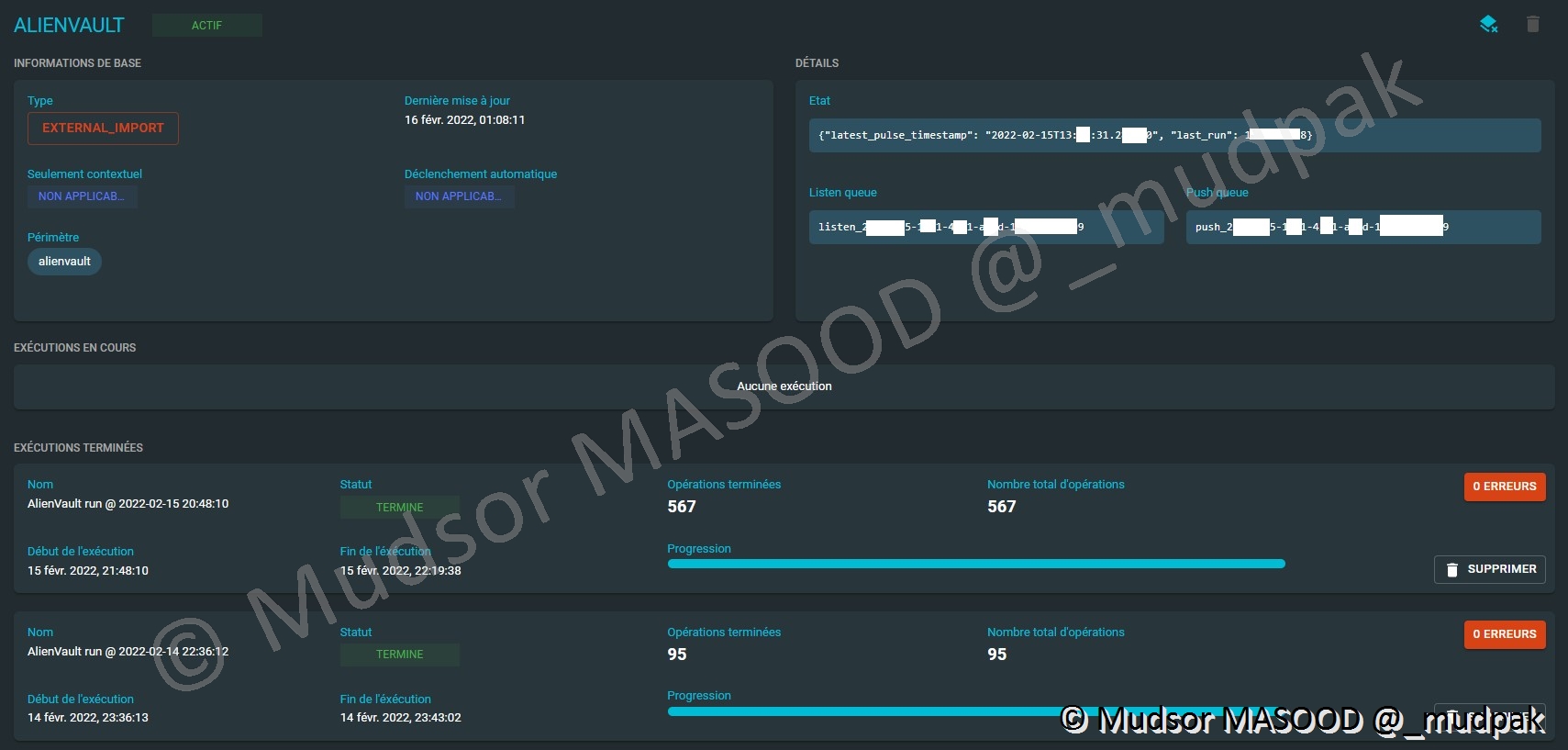
Si nous regardons en détails par exemple le connecteur « AlienVault », voici les informations que nous pouvons observer :
- Informations de base :
- Un état général du connecteur
- Quel type d’import est effectué ?
- La date de la dernière mise à jour
- Détails
- L’état du connecteur avec les paramètres d’horodatage
- Listen queue : informations techniques liées à rabbitmq
- Push queue : informations techniques liées à rabbitmq
- Exécution en cours : est-ce que le connecteur est en cours d’exécution ou non, par là il faut comprendre est-ce que le connecteur est en cours d’importation des données vers notre plateforme
- Exécutions terminées :
- La liste des exécutions
- Début et fin de l’exécution
- Le statut
- Opérations terminées : combien d’éléments ont été importés
- Nombre total d’opérations : nombre total d’éléments importés
- Supprimer : si vous souhaitez supprimer la tâche
Remarque :
En cliquant sur « Erreurs » vous êtes redirigés vers une page qui affichera les détails des erreurs s’il y en a.
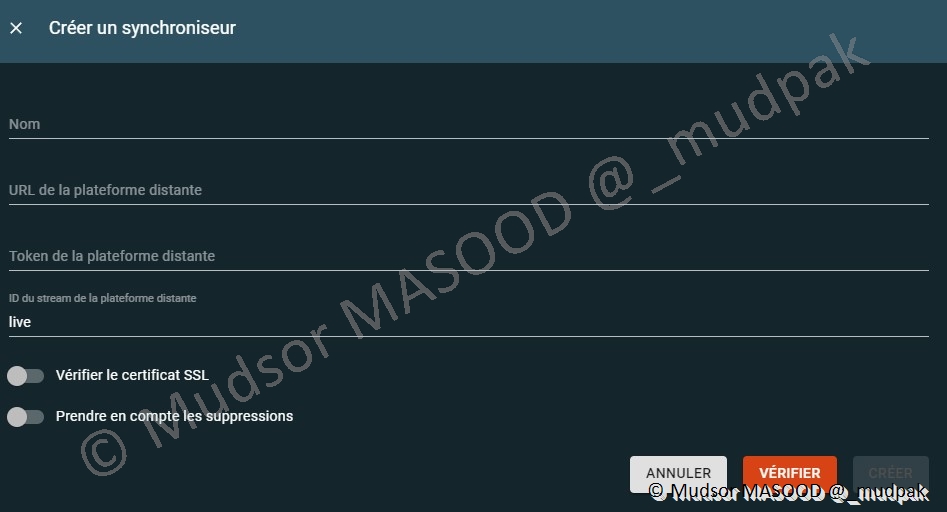
10.5.4 Synchronisation
Possibilité de se connecter et récupérer des informations en temps réel d’une autre plateforme OpenCTI qui aurait publié un live stream.

Pour créer un synchroniseur il faut remplir les champs suivants :
- Nom
- URL de la plateforme distance
- Token de la plateforme distance
- ID du stream de la plateforme distance
Vous pouvez vérifier si la connexion avec l’hôte distante est fonctionnelle en cliquant sur
- VÉRIFIER
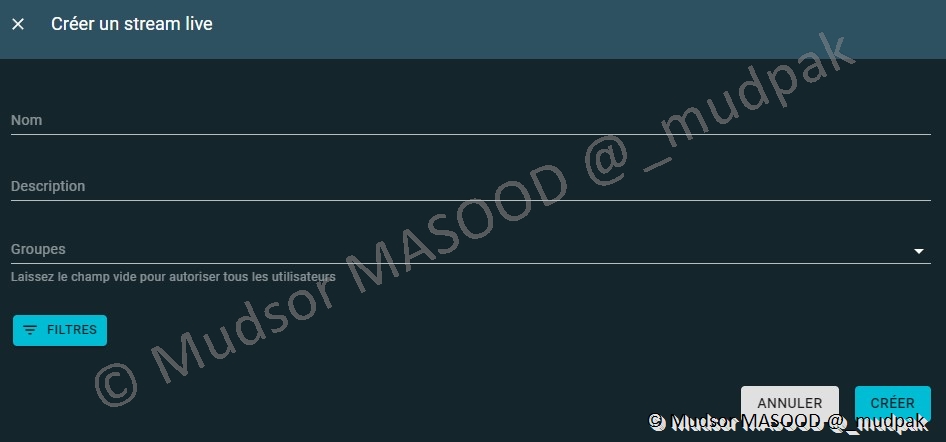
10.5.5 Partage de données
Par défaut deux types de streams de données sont disponibles :
- /stream/live : pour les données « traitées »
- / stream : pour les données au format « brute »

Voici un exemple de « stream live » :

Voici un exemple de « stream brut » :

Vous pouvez créer un stream personnalisé pour cela il faut remplir les champs suivants :
- Nom
- Description
- Groupes
- Filtres
10.5.6 Collections TAXII
Expositon serveur TAXII :
Pour exposer un TAXII server je vous invite à regarder la source suivante : https://oasis-open.github.io/cti-documentation/taxii/intro.html
Synchronisation serveur TAXII :
Pour synchroniser TAXII je vous invite à voir la source suivante : OpenCTI data sharing > https://medium.com/luatix/opencti-data-sharing-6da7dc045d14

Pour créer une collection TAXII il faut remplir les champs suivants :
- Nom
- Description
- Filtres

10.6 Paramètres
Cette partie contiens différents menus qui sont les suivants :
- Paramètres
- Accès
- Workflows
- Politiques de rétention
- Moteur de règles
- Labels & Attributs

10.6.1 Paramètres
Le menu paramètre contiens différentes parties.
10.6.1.1 Configuration
Dans cette partie nous avons les champs suivants :
- Nom : nom sur s’affiche sur l’onglet du navigateur
- Adresse mail d’expédition : adresse email à utiliser pour les envois de mail
- Thème : nous pouvons choisir un thème clair ou sombre ou même en créer un !
- Langue
- La langue de la plateforme
- Par défaut le paramètre « automatique » est utilisé ainsi selon la langue du système la plateforme s’adapte entre le Français et l’Anglais.

10.6.1.2 Thème
Il est tout à fait possible de créer un thème personnalisé qui vous corresponde mieux :
10.6.1.3 Stratégies d’authentification
Nous pouvons définir un message à afficher lorsqu’on arrive sur la page d’authentification :
10.6.1.4 Outils
La liste des outils et leur état est affiché :

10.6.2 Accès

Le menu « Accès » est composé de différentes parties :
- Rôles
- Utilisateurs
- Groupes
- Marquages
- Sessions
10.6.2.1 Rôles
Différents types de rôles sont par défaut existants :
- Administrateur : un compte avec tous les privilèges sur la plateforme
- Connector
- Le fameux rôle dont j’ai parlé à plusieurs reprises plus haut dans le document !
- Je vous conseille vivement de créer un compte utilisateur et de lui appliquer ce rôle, ainsi le Token / clé API de ce compte sera utilisé pour les connecteurs
- Pour aller plus loin je dirais même qu’il faut un compte par connecteur pour séparer les connecteurs
- Default

Il est possible de créer un nouveau rôle pour cela il faut remplir les champs suivants :
- Nom
- Description
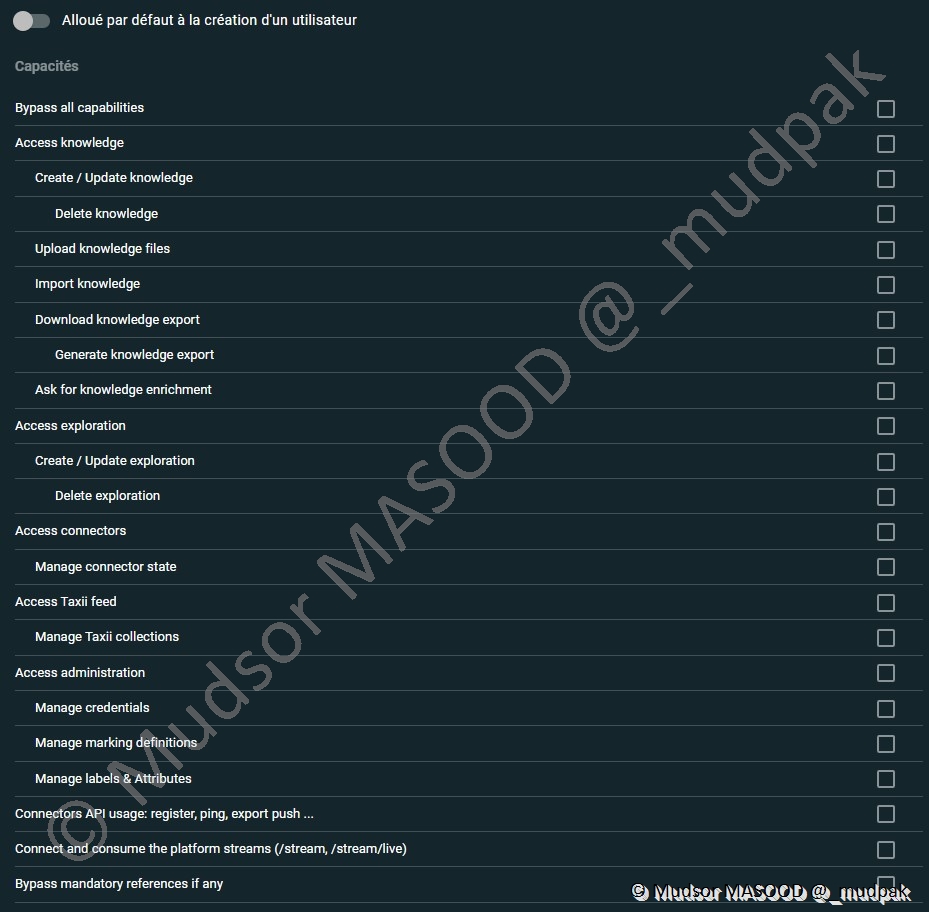
Une fois que le rôle est créé, il faut lui attribuer des droits, voici la liste des droits qu’on peut attribuer :
10.6.2.2 Utilisateurs
Par défaut un compte de type administrateur est présent :

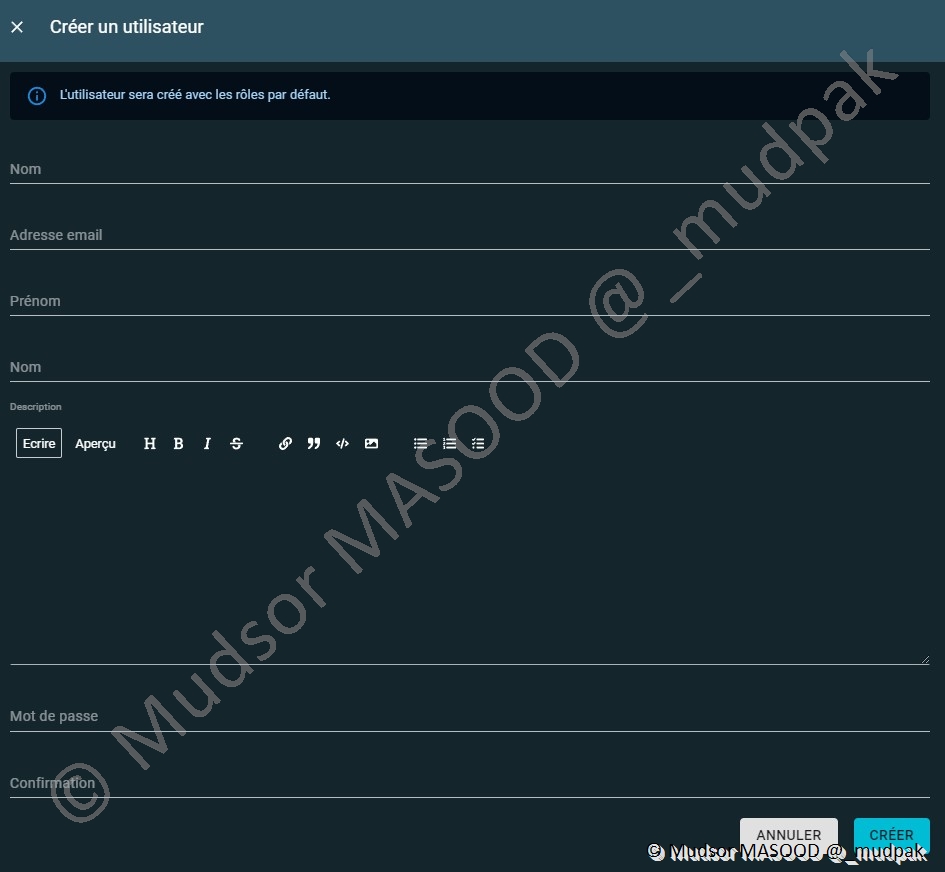
Pour créer un nouveau compte il faut remplir les champs suivants :
- Nom
- Adresse email
- Prénom
- Nom
- Description
- Mot de passe
- Confirmation
A noter :
Il est important de noter que nous n’avons pas traité la partie emailing.
Ainsi l’utilisateur aura beau se connecteur avec une adresse email aucun email ne lui sera envoyé puisque nous n’avons pas mis en place un serveur de messagerie.
10.6.2.3 Groupes
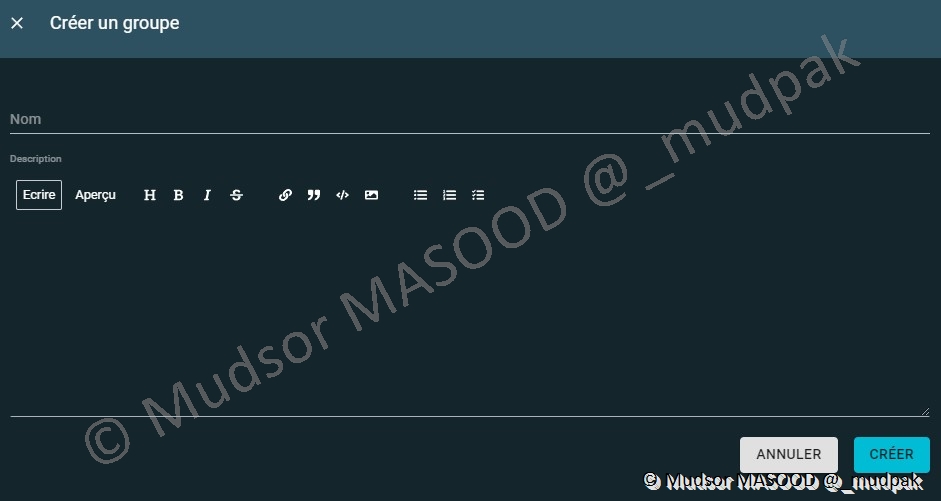
Par défaut il n’y a pas de groupes, pour des raisons de sécurité et de bonnes pratiques il est recommandé de créer des groupes :

Pour créer un groupe il faut remplir les champs suivants :
- Nom
- Description
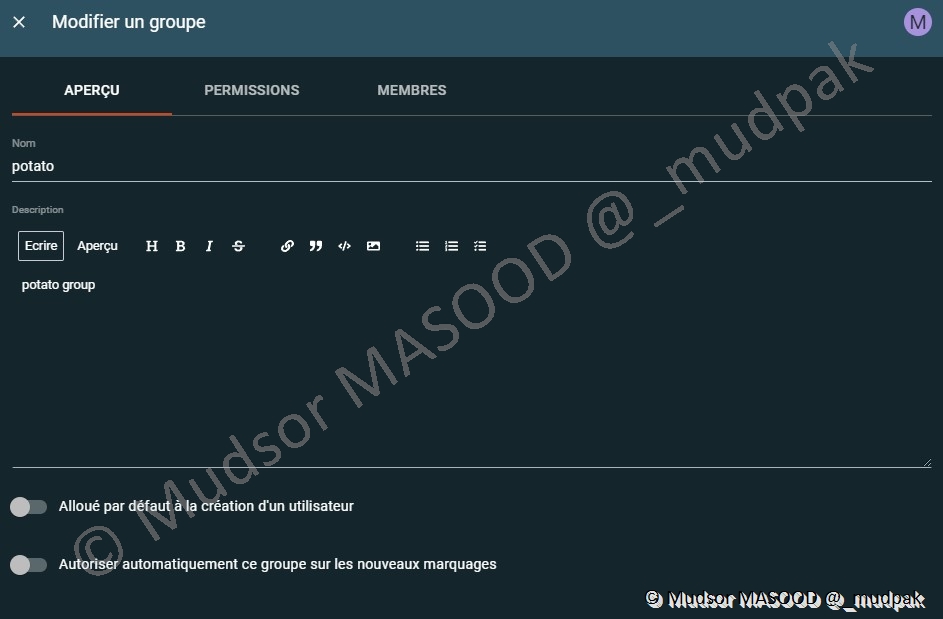
Lorsque le groupe est créé il faut modifier les paramètres :
- Alloué par défaut à la création d’un utilisateur : est-ce qu’on souhaite ajouter tous les nouveaux comptes crée à ce groupe ?
- Autoriser automatiquement ce groupe sur les nouveaux marquages : est-ce qu’on ajoute ce groupe sur tous les nouveaux marquages ?
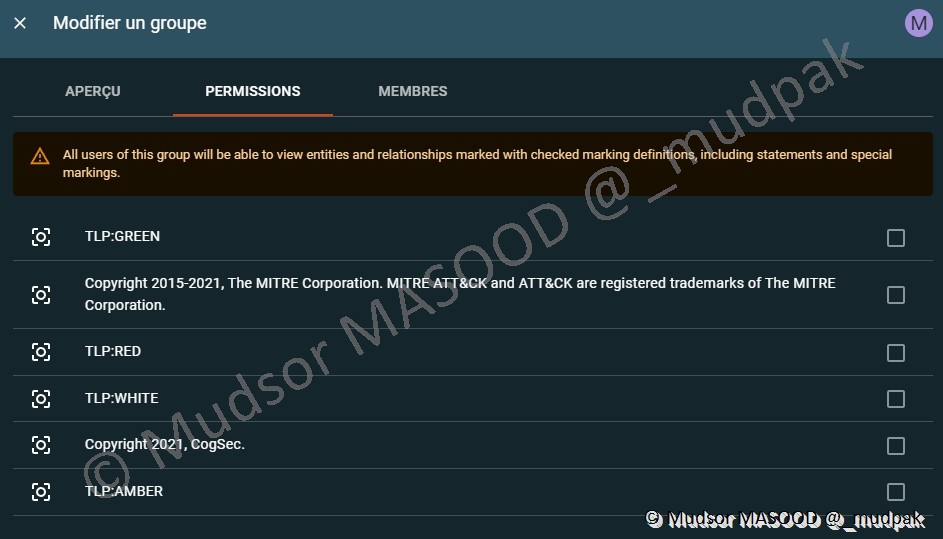
Dans l’onglet permissions nous pouvons ajuster les droits pour que le groupe puisse accéder à un TLP spécifique de rapports :
Dans le dernier onglet on peut voir ou ajouter des membres à ce groupe :

10.6.2.4 Marquages
Tout au long du document j’ai évoqué les « TLP », voici donc les différents types de TLP du niveau le plus critique au moins critique :
- RED
- AMBER
- GREEN
- WHITE
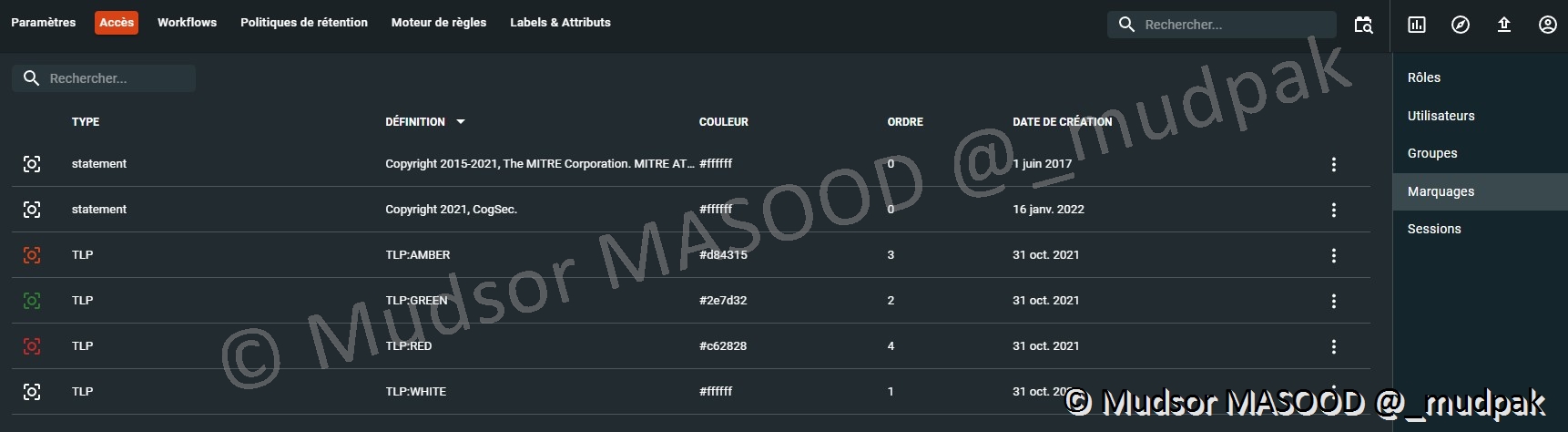
Vous pouvez créer un type de marquage adapté à vos besoins, pour cela il faut remplir les champs suivants :
- Type
- Définition
- Couleur
- Ordre

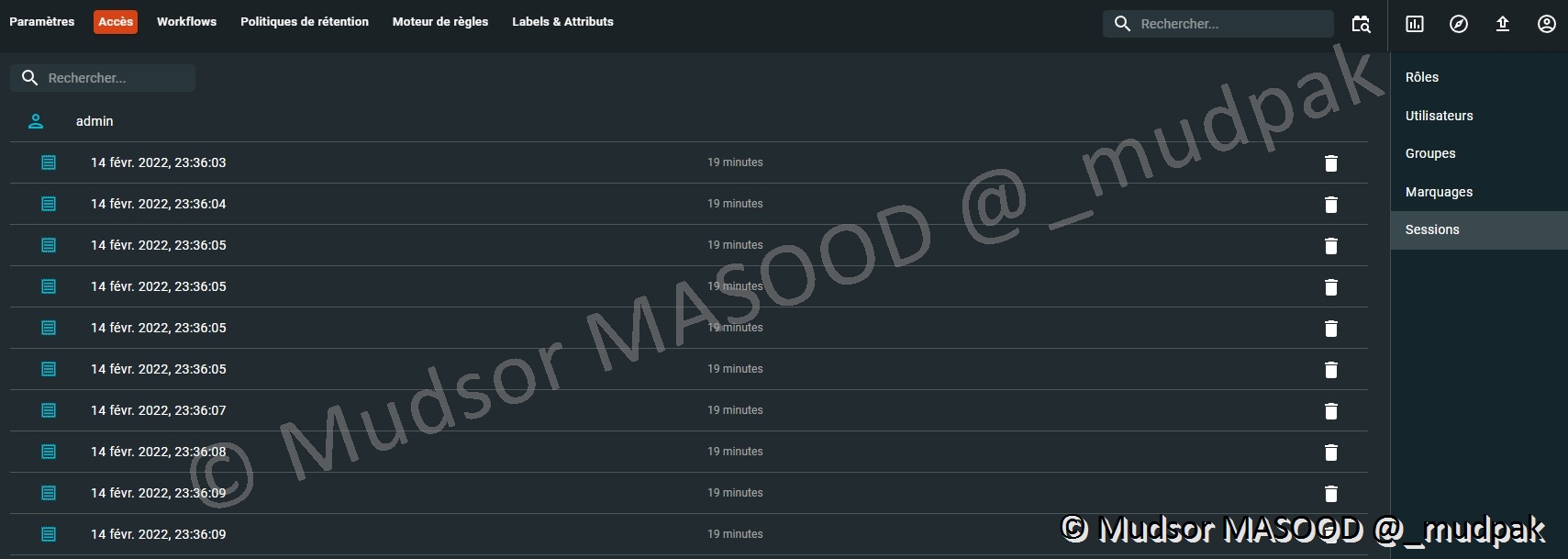
10.6.2.5 Sessions
Dans cette partie nous pouvons voir l’historique des connexions des différents utilisateurs.
Il est tout à fait possible de révoquer la connexion à un utilisateur en cliquant sur la corbeille située à droite de la fenêtre :
10.6.3 Workflows
Permet d'associer un workflow manuel.
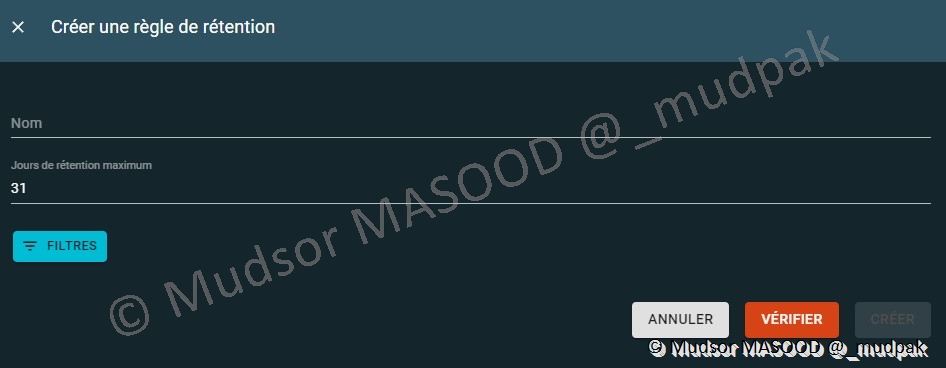
10.6.4 Politique de rétention
Par défaut il n’y a pas de politique de rétention, donc les données sont enregistrées jusqu’à saturation du disque dur :

Nous pouvons créer une règle de rétention en remplissant les champs suivants :
- Nom
- Jours de rétention maximum : durée après laquelle les données peuvent être supprimées
- Filtres : ces filtres vous permettront de sélectionner précisément par exemple quels niveaux de TLP sélectionner pour la conservation
10.6.5 Moteur de règles
C’est un moteur qui permet de créer des relations différentes entres des éléments.
Par exemple si MALWARE1 target CITY et CITY part-of COUNTRY alors MALWARE1 target COUNTRY.
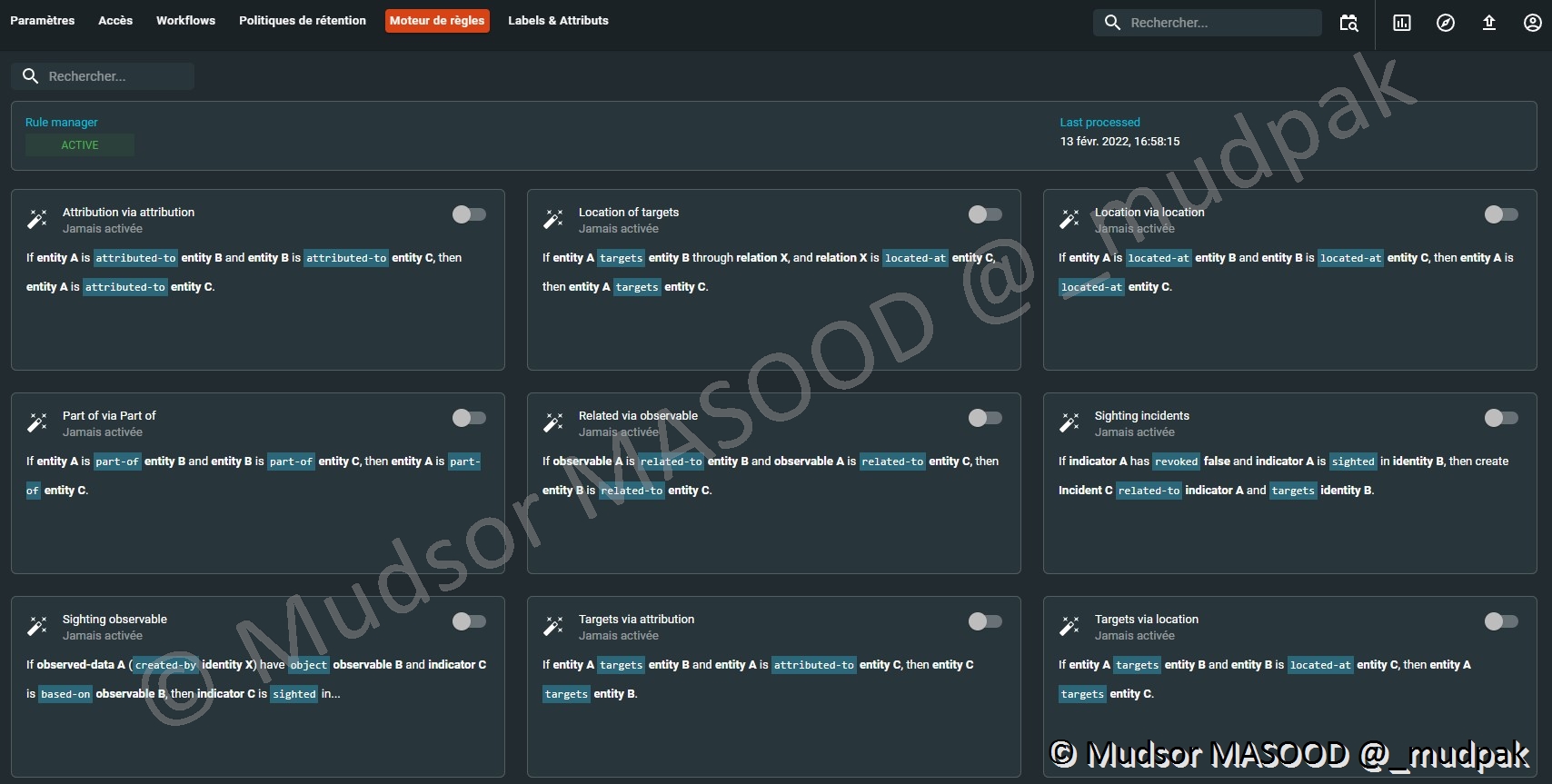
10.6.6 Labels & attributs
Ce menu est composé de différents onglets :
- Labels
- Phases de kill chain
- Types de rapport
10.6.6.1 Labels
Tout au long du document nous avons vu sur chaque rapport l’existence de labels dès qu’il y en fait, au-delà de cet aspect lors de la création d’un élément quasi systématiquement cette option était proposée, en fait on peut la comparer au système de « tags », cela permet de trier / retrouver des éléments plus rapidement.
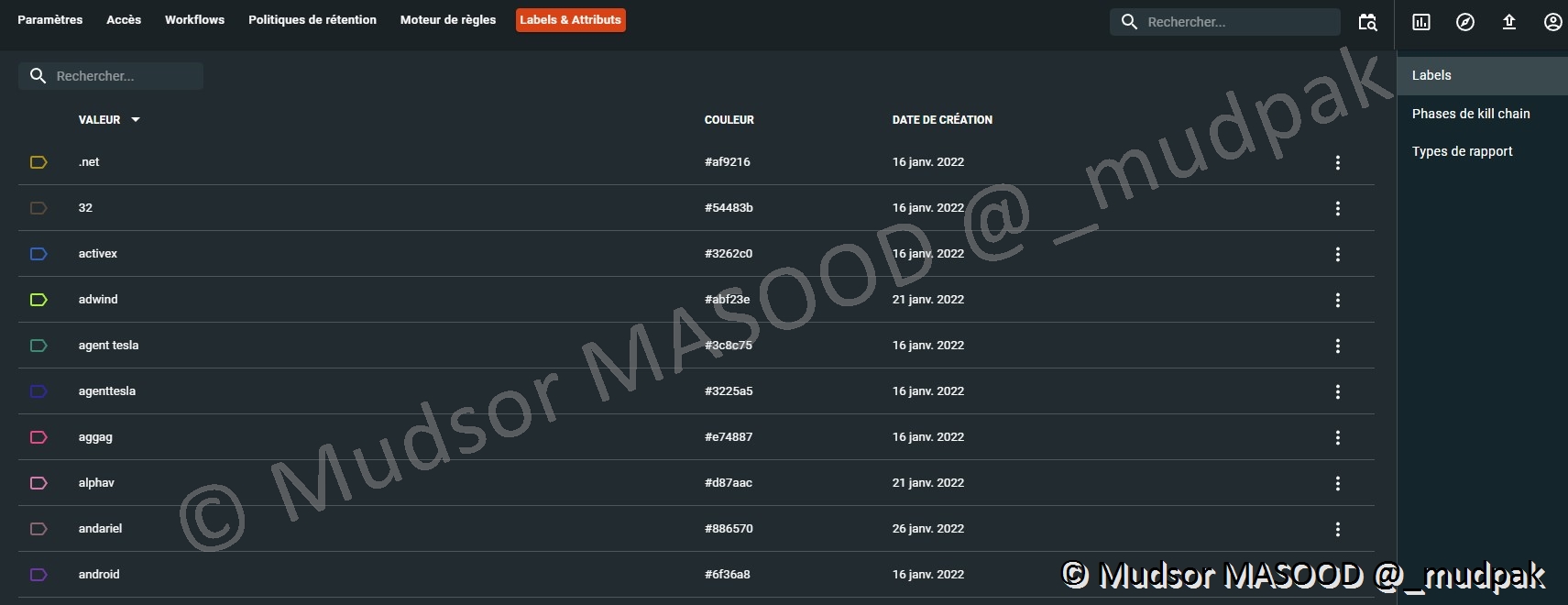
Pour créer un attribut il faut remplir le champ suivant :
- Valeur : par la valeur que l’attribut va porter

10.6.6.2 Phases de kill chain
Comme nous l’avons vu précédemment ici nous avons une autre représentation de la matrice MITRE ATT&CK :
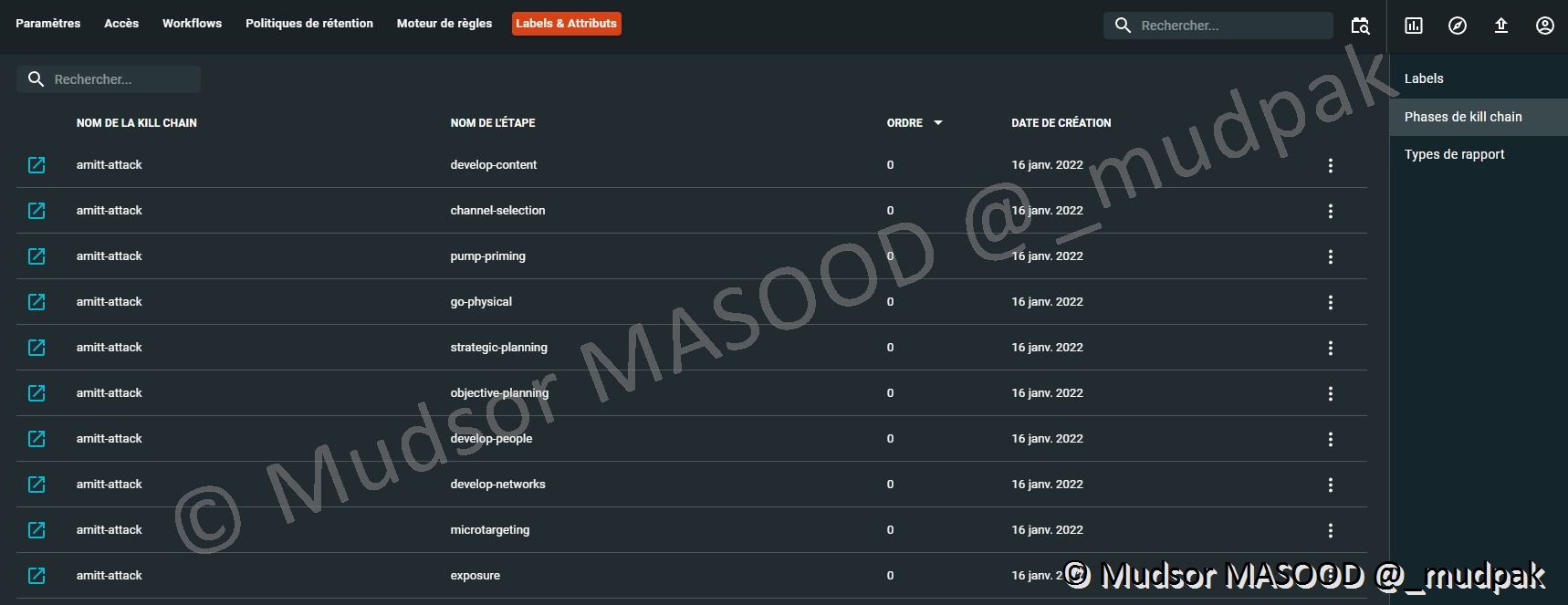
Pour créer un nouvel attribut il faut remplir le champ suivant :
- Valeur

10.6.6.3 Types de rapport
Sur les rapports que nous avons pu visualiser sur la plateforme ils correspondaient à une des deux catégories ci-dessous :

Il peut être pertinent des créer une catégorie adaptée à votre contexte, pour créer un nouvel attribut il faut remplir le champ suivant :
- Valeur

11. Erreurs courantes
Voici une liste des erreurs les plus courantes que j’ai pu rencontrer et leurs solutions.
11.1 Docker
11.1.1 Cas 1
Problème : Impossible d’exécuter docker en tant que simple utilisateur :
Solutions :
a. Est-ce que « docker rootless » a été configuré ?
b. Est-ce que l’utilisateur à été ajouté au groupe « docker » ?
c. Est-ce que l’utilisateur s’est déconnecté et reconnecté à son compte ?
11.2 Docker-Compose
11.2.1 Cas 2
Problème : La nouvelle configuration du fichier « docker-compose.yml » ne fonctionne pas :
Solutions :
a. Est-ce que la stack a été stoppée ?
b. Est-ce que le pull de nouveaux containers a été réalisée ?
c. Est-ce que le fichier de configuration « docker-compose.yml » contient les informations du connecteur qui ne fonctionne pas ?
11.3 OpenCTI
11.3.1 Cas 3
Problème : L’accès à l’interface web ne fonctionne pas :
Solutions :
a. Est-ce que tous les containers ont fini de démarrer ?
b. Est-ce que le port a bien de connexion a été modifié ?
11.3.2 Cas 4
Problème : La carte des pays s’affiche mais selon le nombre de rapports il n’y a pas de coloration sur la carte :
Solution : Est-ce que le connecteur « opencti » a été ajouté au fichier « dockercompose.yml » ?
12. Conclusion
A travers ce long document nous avons vu les différentes étapes pour la mise en place, alimentation et utilisation de la plateforme OpenCTI.
Il existe des méthodes plus simples et rapides pour la mise en place tel que l’utilisation de la machine virtuelle ou simplement de l’utilisation de la démo avant d’implémenter la solution en entreprise ou chez soi.
Quoi qu’il en soit en tant que français nous pouvons être fiers d’avoir un tel outil Made In France car il a bien des concurrents en place déjà depuis des années mais aucun d’entre eux n’intègre la CTI pour tous types de personnes au même endroit et c’est une des forces de OpenCTI !
Je ne peux que vous inviter à utiliser la solution que ce soit pour un usage professionnel, ou personnel par exemple pour faire de la veille cyber !
Pour aller plus loin il est possible de contribuer au projet de différentes manières :
- En faisant partager la solution à un maximum de monde !
- En améliorant la documentation
- En ajoutant des fonctionnalités via GitHub
- En rejoignant la communauté Slack
- En aidant financièrement o En effectuant un don
- En devenant un « membre actif » ou « Sponsor »
13. Sources
Voici les différentes sources qui m’ont été utiles pour la réalisation de ce document :
- https://demo.opencti.io/
- https://www.opencti.io/fr/
- https://github.com/orgs/OpenCTI-Platform/repositories
- https://github.com/OpenCTI-Platform/connectors/tree/master/external-import
- https://www.notion.so/OpenCTI-Public-Knowledge-Based411e5e477734c59887dad3649f20518