AIL - Analysis of Information Leaks - CIRCL

@_euzebius |Nhammmber One Mentor !| |Lundi 29 Août 2022 |Mudsor MASOOD
mudpak |Mise à jour vers blog (v1.0.1)| |Dimanche 28 Août 2022 |mudpak |Finalisation du document (v1.0.0)| |Samedi 27 Août 2022 |Paul VAN-ELSUE
Seimu |Relecture et validation (v0.0.12)| |Samedi 20 Août 2022 |Paul VAN-ELSUE
Seimu |Relecture et validation (v0.0.11)| |Lundi 15 Août 2022 |Paul VAN-ELSUE
Seimu |Relecture et validation (v0.0.10)| |Mardi 9 Août 2022 |Paul VAN-ELSUE
Seimu |Relecture et validation (v0.0.9)| |Vendredi 5 Août 2022 |mudpak |Configuration AIL Splash Manager (v0.0.8)| |Jeudi 4 Août 2022 |mudak |Soumission manuelle des données (v0.0.7)| |Jeudi 14 Juillet 2022 |Philippe SEGRET
Pich |Aide Technique (v0.0.6)| |Dimanche 10 Juillet 2022 |Paul VAN-ELSUE
Seimu |Aide Technique TOR (v0.0.5)| |Mercredi 6 Juillet 2022 |mudpak |Récolte et analye des données (v0.0.4)| |Mardi 5 Juillet 2022 |mudpak |Connexion au feed Pystemon (v0.0.3)| |Lundi 4 Juillet 2022 |mudpak |Mise en place du Lab (v0.0.2)| |Mercredi 22 Juin 2022 |mudpak |Création du document (v0.0.1)|

0. Avant-propos
Il existe de nombreux outils et méthodes pour effectuer de la CTI et précisément de la veille et analyse de leaks.
Ce document a pour but de guider l’utilisateur dans
- La mise en place
- Découverte
- Utilisation
De la plateforme « AIL – Analysis of Information Leaks » crée par le CIRCL (Computer Incident Response Center Luxembourg).
Aujourd’hui il est relativement facile de trouver des leaks, cependant au vu du volume et format que certaines peuvent représenter il devient fastidieux et les analyser.
C’est à cette problématique que réponds en partie AIL, en effet il va analyser, catégoriser les données à notre place.
Puisqu’il est possible d’interconnecter notre plateforme avec d’autres outils il nous restera donc à voir si la donnée est pertinente ou non et décider de la suite des actions à entreprendre :
- Envoyer dans MISP ?
- Envoyer dans TheHive ?
- Effectuer d’autres actions ?
La solution AIL permet
- D’analyser et catégoriser des données
- De trouver des données via les Feeders (bien que cela ne soit pas sa fonctionnalité principale)
AIL Framework permet de réaliser toutes ces opérations :
- Tant manuellement, avec la soumission des données
- Tant automatiquement, via le feeder pystemon par exemple
Différents modules seront présentés et utilisés par la suite, notamment :
- Pystemon : pour la récupération des données publiquement accessibles
- AIL Splash Manager : pour la surveillance des sites
Via Pystemon nous verrons comment récupérer des données et trouver du contenu sensible (emails, mot de passes, adresses IP, comptes utilisateurs, informations personnelles. . .).
Via AIL Splash Manager nous verrons comment
- Surveiller des sites
- Prendre des captures d’écrans manuelles et automatisée
Pour rester informé des changements.
Disclaimer Légal
Ni l’auteur du document, les personnes citées et ni les créateurs de la solution ne pourront être tenus responsables des usages illégaux qui pourraient en être fait.
Remarque
L’article ayant été réalisé en différentes phases, certaines sections ne sont pas complètes / détaillées et peuvent contenir des erreurs, n’hésitez pas à apporter votre aide si vous le souhaitez. Merci !
1. Définitions
Un certain nombre de termes et sigles sont utilisés dans le document, voici leur signification dans le contexte du projet.
1.1 AIL
Analysis of Information Leaks : Analyse de fuites de données.
1.2 CTI
Cyber Threat Intelligence est une branche des métiers du Blue Team.
1.3 Leaks
Fuites de données, données exposées publiquement alors qu'elles ne devraient pas l'être.
1.4 MISP
« Malware Information Sharing Platform » est une solution Open-Source de CTI, elle permet de partager des IOC et a été créée par . . . CIRCL
1.5 TheHive
C’est une plateforme Open-Source de réponse à incident.
1.6 CPU
Central Processing Unit : Processeur.
1.7 RAM
Random Access Memory : Mémoire vive.
1.8 CERT
Computer Emergency Response Team : centre d’alerte et de réaction aux attaques informatiques.
1.9 Feeder
Élément qui va venir alimenter en données notre outil.
1.10 TOR
Tor est un réseau informatique superposé mondial et décentralisé, il se compose de serveurs, appelés nœuds du réseau et dont la liste est publique.
Ce réseau permet d'anonymiser l'origine de connexions TCP.
1.11 AIL Splash Manager
C’est un programme qui permet de surveiller et prendre des captures d’écrans des sites à la fois sur le surface / deep web et dark web (.onion)
1.12 Crawler
Ou « robot d'indexation » est un logiciel qui explore automatiquement le Web. Il est généralement conçu pour collecter les ressources, afin de permettre à un moteur de recherche de les indexer.
2. Prérequis
Pour mettre en place l’infrastructure, il faut répondre à certains critères matériels et logiciels pour pouvoir l’utiliser dans les meilleures conditions.
Remarque
Ces prérequis sont mes choix, si vous êtes à l’aise ou souhaitez faire différemment libre à vous, toutefois je ne garantis pas que la solution va fonctionner ou même démarrer.
2.1 Matériel
Du point de vue des composants, voici la configuration matérielle qui a été utilisée :
| Composants: | Configuration : | Détails : |
|---|---|---|
| CPU | i7 (4coeurs logiques) | Un processeur dual-core peut convenir |
| RAM | 16 Go | Suffisamment de mémoire vive pour les opérations |
| Disque | 66 Go | Espace disque pour stocker les leaks + espace OS. Suffisant pour le lab mais pas pour de la production ! |
| Carte réseau | Mode bridge | Pour que la machine puisse communiquer et être joignable par le réseau sans NAT. |
2.2 Logiciel
Du point de vue logiciel, il faut
- Une machine hôte virtuelle dans notre cas
- Nous avons choisi Ubuntu Server 20.04.4 LTS
- Un accès internet
- Pour télécharger et installer les éléments
- Des droits administrateur / root sur la machine
3. CIRCL – Computer Incident Response Center Luxembourg

Le CIRCL est une initiative gouvernementale conçue pour fournir un dispositif de réponse aux menaces et incidents de sécurité informatique.
C’est un CERT (Computer Emergency Response Team) situé au Luxembourg et offre des services pour :
- Du secteur privé
- Des communes
- Des entités non gouvernementales
Les différents objectifs du CIRCL sont de
- Recueillir
- Examiner
- Signaler
Et répondre aux menaces cyber.
4. AIL – Analysis of Information Leaks Framework
4.1 Présentation


AIL – Analysis of Information Leaks Project est un framework Open-Source composé de différents modules pour
- Collecter
- Explorer
- Investiguer
- Analyser
Des données non structurées.
Il permet une analyse de données collectées provenant de différentes sources :
- Discord
- Telegram
- Manuelles
- . . .
Il prend également en charge l'exploration des services cachés de Tor ainsi que l'exploration de sites Web et de forums protégés avec des cookies de session préenregistrés.
Voici quelques exemples de fonctionnalités offertes par l’outil :
- Extraction des fuites potentielles de numéros de carte de crédit, identifiants, ...
- Extraction des adresses e-mail divulguées
- Alerte au MISP pour partager les fuites trouvées au sein d'une plate-forme de renseignements sur les menaces à l'aide de la norme MISP
- Détecter les clés Amazon AWS, Google API, l'adresse Bitcoin, les clés privées Bitcoin, les clés privées, certificat, clés SSH, OpenVPN, les IBAN
- Robot d'exploration de services cachés Tor pour explorer et analyser la sortie
- Robot d'exploration Web générique pour déclencher l'exploration à la demande ou à intervalles réguliers URL ou services cachés de Tor
- . . .
Remarque
La liste complète des fonctionnalités est disponible sur le site du projet ainsi que sur la page GitHub de celui-ci.
4.2 Types d’installation
Il existe plusieurs méthodes pour installer la solution, voici les deux premières testées mais non retenues :
- Méthode 1 – Installation via GitHub sur Ubuntu Server 22.04 LTS
- Lors des différentes phases de compilations de nombreuses erreurs sont apparues et je n’ai pas les compétences pour debugger.
- Ces erreurs sont du très probablement dues à l’installation sur une machine Ubuntu Server 22.04 LTS, qui n’est pas l’architecture adaptée pour AIL
- Méthode 2 – Installation via container LXC
- Le container fonctionne, mais il faut penser à exposer les ports de celui-ci pour se connecter à l’interface web à partir d’une autre machine du réseau, sinon il faut disposer de l’interface web sur la machine hôte pour accéder directement
- Ce container étant basé sur Ubuntu 20.04, cette information cruciale m’a donné la bonne piste pour la suite des évènements.
Et enfin la dernière que nous allons utiliser pour la suite du document
- Méthode 3 – Installation sur Ubuntu Server 20.04.4 LTS
- Puisque le container LXC est basé sur cette même version j’évite les problèmes d’incompatibilité et diverses erreurs
- L’installation aurait très bien pu se faire via containers mais cela aurait rajouté une complexité potentielle pour les différentes phases
Remarque
Si vous savez gérer les containers LXC et notamment la partie interconnexion réseau, la méthode la plus simple et rapide c’est d’utiliser l’installation via container LXC (Méthode 2) car un container officiel, prêt et à jour est utilisable.
Pour le récupérer il faut se rendre sur le site du projet.
5. Ubuntu Server 20.04.4 LTS
Avant de commencer le projet il faut effectuer quelques étapes de préparation du serveur.
5.1 Nom du serveur
Nous allons mettre à jour le nom du serveur pour le refléter au nom du projet.
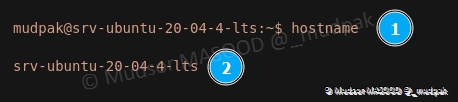
5.1.1 Affichage du nom actuel
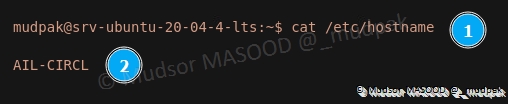
Pour afficher le nom, saisir la commande suivante :
1 | |
Détails de la commande :
1 | |
- 1 : commande utilisée
- 2 : le nom actuel s’affiche
5.1.2 Modification du nom
Pour modifier le nom, saisir la commande suivante :
1 | |
Détails de la commande :
1 2 3 | |

Voici le nouveau nom du serveur :
Pour enregistrer les modifications, effectuer les combinaisons des touches « ctrl +x » et saisir
- Yes
Appuyer sur la touche « entrée :

Nous pouvons afficher le nom qui a été renseigné dans le fichier de configuration, mais ce n’est pas pour pourtant que les modifications sont effectives :
5.1.3 Application des modifications
Pour appliquer les modifications il faut redémarrer la machine, saisir la commande suivante :
1 | |

5.1.4 Affichage du nouveau nom
Après le redémarrage du poste nous pouvons à nouveau saisir la commande « hostname » et constater que le nom du poste à bien changé :

5.2 Mise à jour de la liste des paquets
Nous allons mettre à jour la liste des paquets pour une installation future, saisir la commande suivante :
1 | |
Détails de la commande :
1 2 3 | |
Différentes étapes se succèdent pour nous informer :
- De la mise à jour de la liste des paquets
- De la place occupée par cette opération
Il nous est proposé d’effectuer la commande « apt list --upgradable » pour afficher la liste des paquets pouvant être mis à jour :

5.3 Serveur SSH
Par défaut SSH n’est pas installé sur la distribution, nous allons l’installer et vérifier son activation pour ensuite prendre le contrôle à distance sur le serveur.
5.3.1 Installation du serveur OpenSSH
Pour installer le serveur OpenSSH, saisir la commande suivante :
1 | |
Détails de la commande :
1 2 3 4 | |
- 2 : d’autres paquets seront installés en plus du paquet demandé
- 3 : des paquets sont suggérés
- 4 : la place qui sera occupée est indiquée
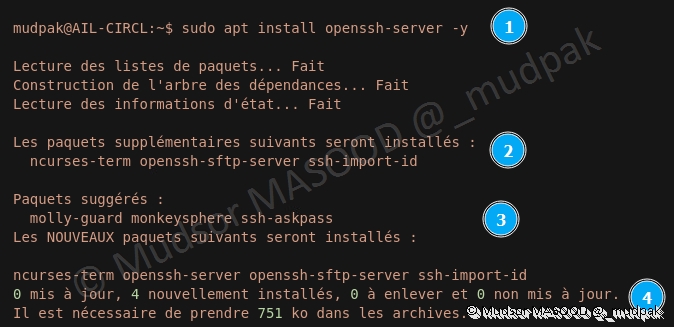
La récupération des paquets commence :

Lorsque les paquets sont récupérés, différentes phases se succèdent pour l’installation :
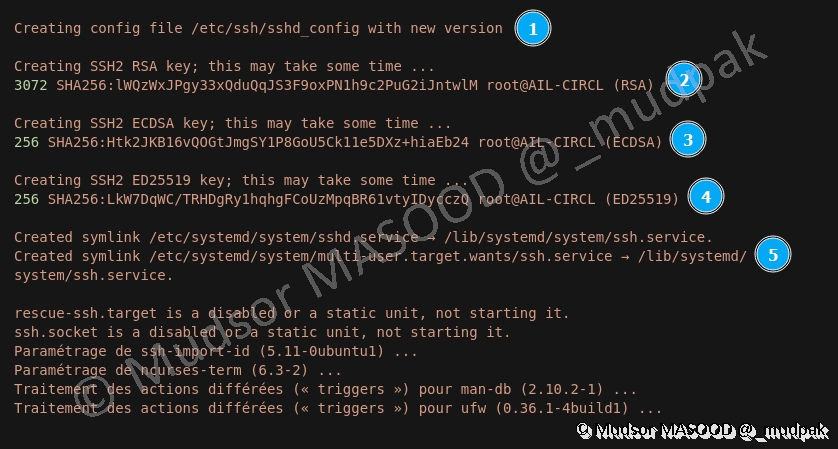
La configuration du service et la génération des clés s’effectue :
- 1 : création du fichier de configuration du service
- 2 : génération de la RSA
- 3 : génération de la clé ECDSA
- 4 : génération de la clé ED25519
- 5 : création des liens symboliques
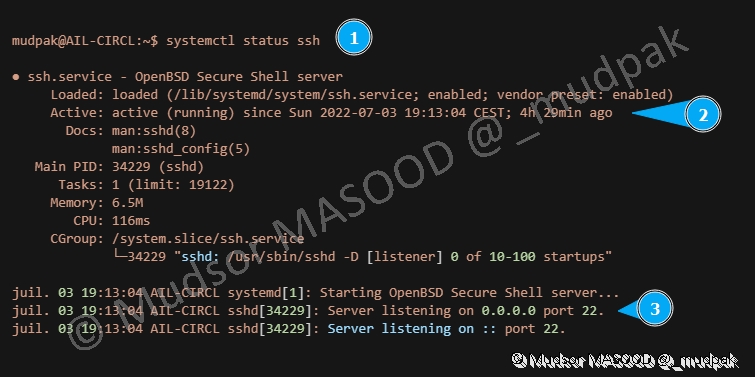
5.3.2 Vérification de l’état du service
Pour vérifier que le service fonctionne, saisir la commande suivante :
1 | |
Détails de la commande :
1 2 3 | |
- 2 : nous pouvons voir que le service est actif depuis près de 4heures et 30minutes
- 3 : le serveur est en écoute vers toutes les IP sources et sur le port 22 (port par défaut du service ssh)
5.3.3 Connexion SSH
Lorsque nous nous connectons via SSH, nous pouvons observer que le serveur a bien journalisé la session :

6. Installation
Pour rappel nous avons choisi d’installer la solution sur Ubuntu Server 20.04.4 LTS, via la méthode GitHub.
6.1 GitHub
Le script d’installation du programme est disponible à l’adresse suivante :
1 | |
6.2 Récupération du script
Pour récupérer le script, saisir la commande suivante :
1 | |
Détails de la commande :
1 2 3 | |

Nous pouvons observer différentes phases successives :
- 1 : création du dossier « ail-framework »
- 2 : énumération des objets se trouvant dans le répertoire distant est effectuée
- 3 : les objets sont comptés
- 4 : compression réalisée avant la réception
- 5 : affichage d’un résumé à ce stade
- 6 : réception des objets
- 7 : vérification entre ce qui devait être reçu et ce qui l’a été

6.3 Vérification de la réception
Nous pouvons également vérifier si le dossier a bien été créé, saisir la commande suivante :
1 | |
Détails de la commande :
1 2 3 4 5 | |
Ci-dessous nous voyons bien que le répertoire existe :

Pour la suite des évènements nous allons nous déplacer dans le répertoire, saisir la commande suivante :
1 | |
Détails de la commande :
1 2 | |
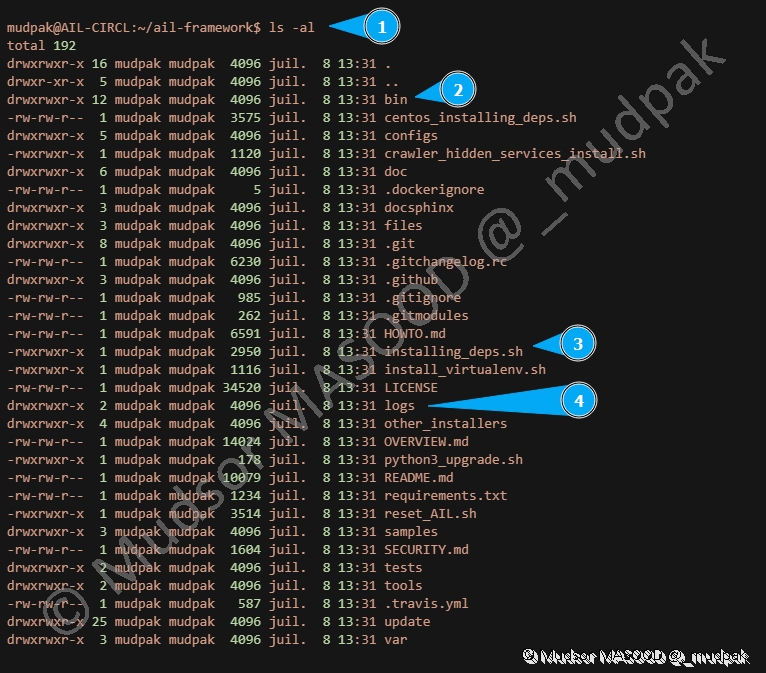
6.4 Contenu du répertoire
Pour lister le contenu du répertoire nous allons utiliser la commande « ls -al » et voici quelques éléments à noter pour la suite :
- 2 : le dossier « bin » contient le script d’exécution du programme
- 3 : le script « installing_deps.sh » que nous allons utiliser pour installer le programme
- 4 : le dossier « logs » va contenir les journaux d’évènements du programme
6.5 Aperçu du script d’installation
Avant de passer à la phase d’installation, nous allons parcourir les différentes sections du script d’installation pour comprendre dans les grandes lignes les différentes actions réalisées par celui-ci.
Pour faire simple, nous utilisons ci-dessous la commande « file » pour identifier le type de fichier et nous pouvons voir que c’est un script bash :

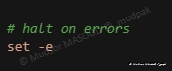
6.5.1 Halt on errors
Cette section active le paramètre « -e » qui permet d’arrêter l’exécution du script dans cas d’erreurs :
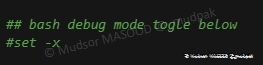
6.5.2 Bash debug mode togle below
Cette section étant commentée et donc ignorée lors de l’exécution, cependant il peut être intéressant d’activer le mode debug pour avoir des informations encore plus détaillées sur les erreurs éventuelles qui pourraient se produire.
Le paramètre « -x » permet d’afficher les commandes ainsi que les arguments utilisés.
6.5.3 Update and package installation
La liste de la mise à jour des paquets est effectuée ainsi que l’installation de nouveaux :

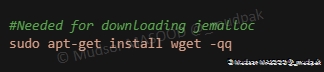
6.5.4 Needed for downloading jemalloc
Installation de wget, c’est un utilitaire qui permet de télécharger de manière non interactive les fichiers via différents protocoles (HTTP, HTTPS, FTP. . . ).
6.5.5 Needed for blom filters
Installation de divers paquets :
- libssl-dev : "Ce paquet fait partie de l'implémentation du projet SSL des protocoles cryptographiques SSL et TLS pour communiquer de façon sécurisée sur internet."
- libfreetype6-dev : "The FreeType project is a team of volunteers who develop free, portable and high-quality software solutions for digital typography."
- Numpy : "The fundamental package for scientific computing with Python"
Sources :
1 2 3 | |

6.5.6 pyMISP
Les lignes étant commentées, elles sont ignorées :

6.5.7 DNS deps
Installation de libadns1 : "Adns est une bibliothèque de résolution pour les programmes en C (et C++). . ."
Sources :
1 2 | |

6.5.8 Needed for redis-lvlDB
Installation de libev-dev : "libev provides a full-featured and high-performance event loop that is loosely modelled after libevent."
Et de libgmp-dev : "provides the header files and the symbolic links to allow compilation and linking of programs that use the libraries provided in the libgmp10 package."
Sources :
1 2 | |

6.5.9 Need for generate-data-flow graph
Installation de graphviz qui permet de créer des graphes :

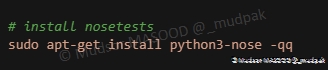
6.5.10 Install nosetests
Installation de python3-nose qui permet d’étendre les fonctionnements d’essai de unittest :
6.5.11 ssdeep
Installation de divers paquets :
- libfuzzy-dev : "ssdeep is a tool for recursive computing and matching of Context Triggered Piecewise Hashing (aka Fuzzy Hashing)."
- build-essential : "...Ce paquet contient une liste informative des paquets qui sont considérés essentiels pour construire des paquets Debian."
- libffi-dev : "This package contains the headers and static library files necessary for building programs which use libffi."
- automake : "GNU Automake is a tool for automatically generating Makefile.in files compliant with the GNU Coding Standards. Automake requires the use of GNU Autoconf."
- autoconf : "Autoconf is an extensible package of M4 macros that produce shell scripts to automatically configure software source code packages."
- libtool : "GNU Libtool is a generic library support script that hides the complexity of using shared libraries behind a consistent, portable interface."
Sources :
1 2 3 4 5 6 | |

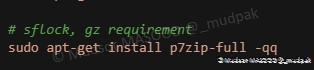
6.5.12 sflock, gz requirement
Installation de pzip pour la gestion des archives :
Source :
1 | |
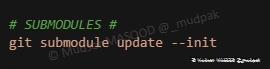
6.5.13 SUBMODULES
Mise à jour des modules git :
6.5.14 Redis
Compilation et installation de redis :
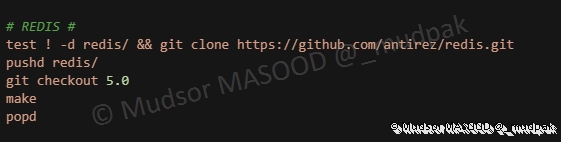
6.5.15 Faup
Compilation et installation de Faup :
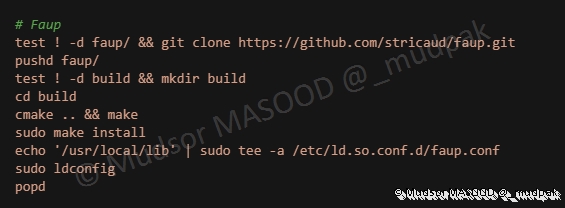
6.5.16 tlsh
Compilation et installation de TLSH :
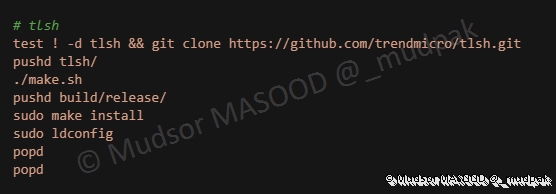
6.5.17 pgpdump
Compilation et installation de PGPDump :
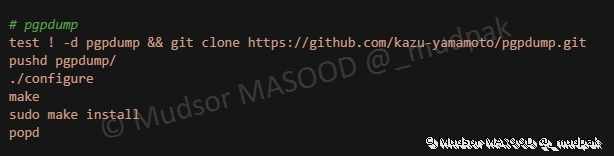
6.5.18 ARDB
Compilation et installation de ARDB :
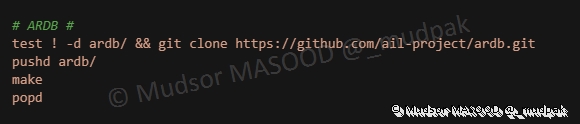
6.5.19 KVROCKS
Les commandes sont ignorées car elles sont commentées :

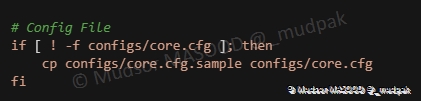
6.5.20 Config file
Vérification sinon cp du fichier de configuration dans le dossier « configs » :
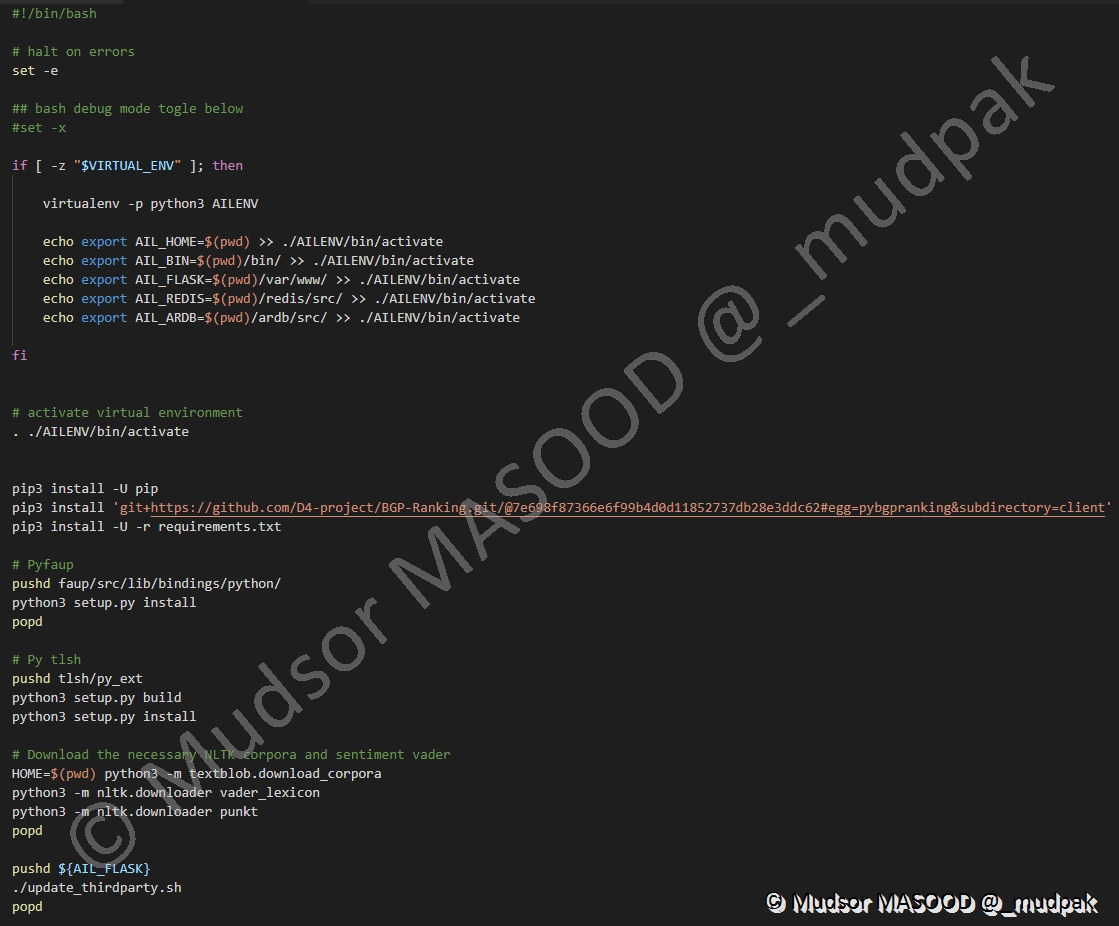
6.5.21 Create AILENV + Install python packages
Lancement du script « Install_virtualenv.sh » :

Voici le contenu du script « install_virtualenv.sh » :
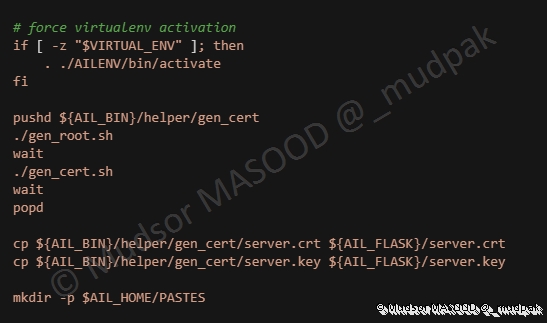
6.5.22 Force virtualenv activation
Création du certificat TLS :
6.5.23 Create the file « all_module_data_flow_graph.sh » in doc
Éxécution d'un script ?

6.5.24 DB Setup
6.5.24.1 Init update version
Pushd permet de modifier le répertoire actif :
6.5.24.2 Shallow clone
?
6.5.24.3 Launch ARDB
Lancement de ARDB (Analytical Results DataBase) :
6.5.24.4 Create default user
Création du compte « ail », c’est ce compte qui sera utilisé par le programme :
6.6 Exécution du script
Pour exécuter le script, saisir la commande suivante :
1 | |
Remarque
Le script effectue toutes les étapes de manière automatisée, la fin du processus peut prendre un certain temps.

6.6.1 Exemple d’installation d’un paquet
Comme précisé aux étapes précédentes, le script exécute les différentes commandes et ci-dessous nous pouvons observer :
- La sélection
- La préparation
- Le dépaquetage
Du paquet « python3-pip » :

Ci-dessous nous pouvons voir la configuration du paquet « python3-pip » qui va commencer :

6.6.2 Exemple de préparation de la compilation
Parmi les différentes phases qui seront effectuées, voici un exemple de phase de préparation à la compilation :
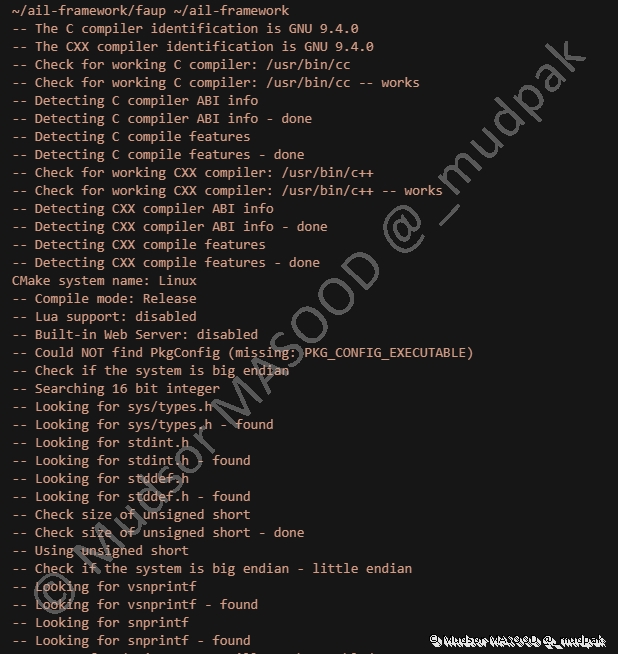
6.6.3 Exemple de compilation
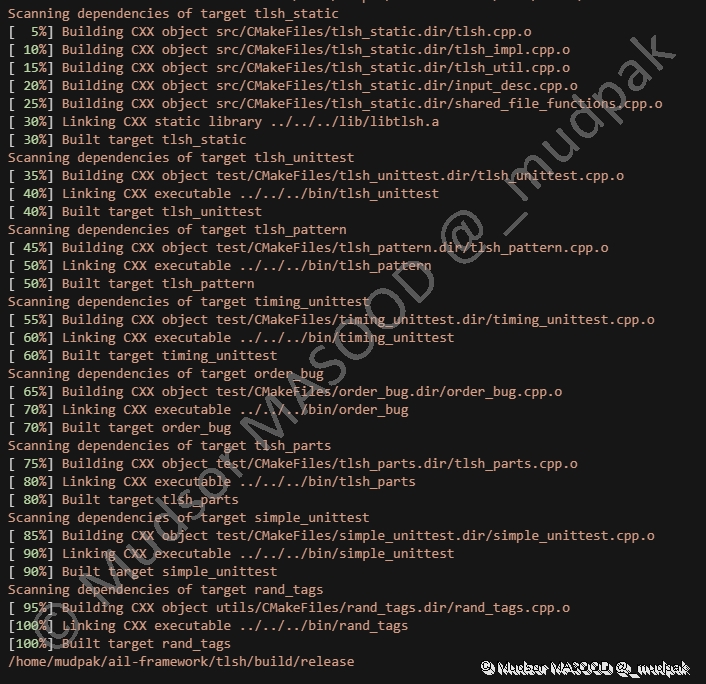
Voici un exemple de compilation :
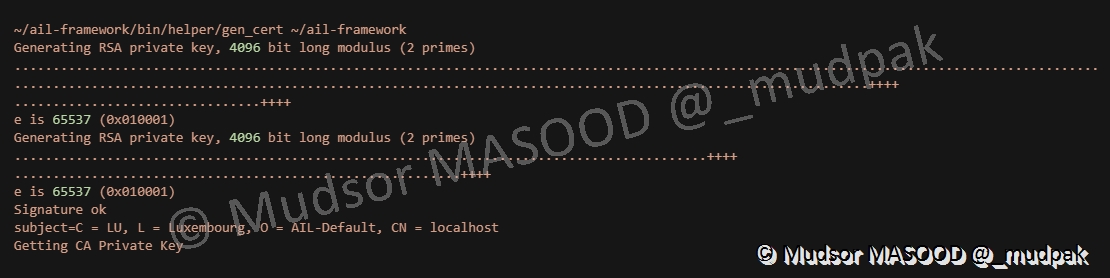
6.6.4 Génération des certificats
Voici l’étape de génération des certificats TLS pour le serveur web :
6.6.5 Fin de l’installation
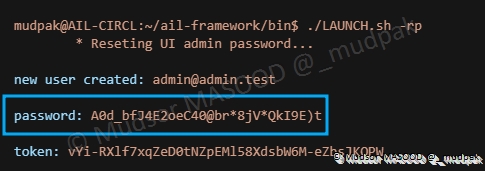
Lorsque l’installation est terminée, des informations cruciales sont affichées :
- 1 : la version de AIL utilisée
- 2 : AIL nous informe que certains services sont démarrés
- 3 : l’adresse email à utiliser pour le compte « admin »
- 4 : le mot de passe du compte
- 5 : le token (clé API) du compte

7. Paramètres du programme
Avant de démarrer le programme, nous allons voir les différentes options d’exécution de celui-ci, pour lancer l’aide il faut se rendre dans le dossier « bin » et saisir la commande suivante :
1 | |
Remarque
Si vous souhaitez passer directement au chapitre suivant vous pouvez lancer la plateforme via la commande « ./LAUNCH.sh -l » (lettre L minuscule) et passer ce chapitre.
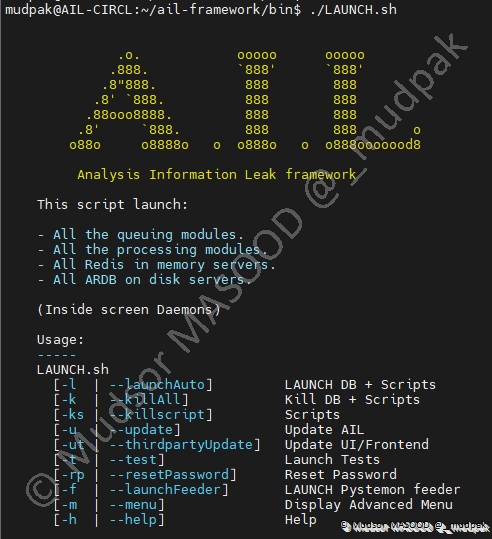
7.1 LAUNCH DB + Scripts
Ce paramètre permet de lancer le programme :
- Démarrage de la base de données
- Démarrage des scripts
C’est aussi la méthode la plus simple et rapide pour démarrer le framework.
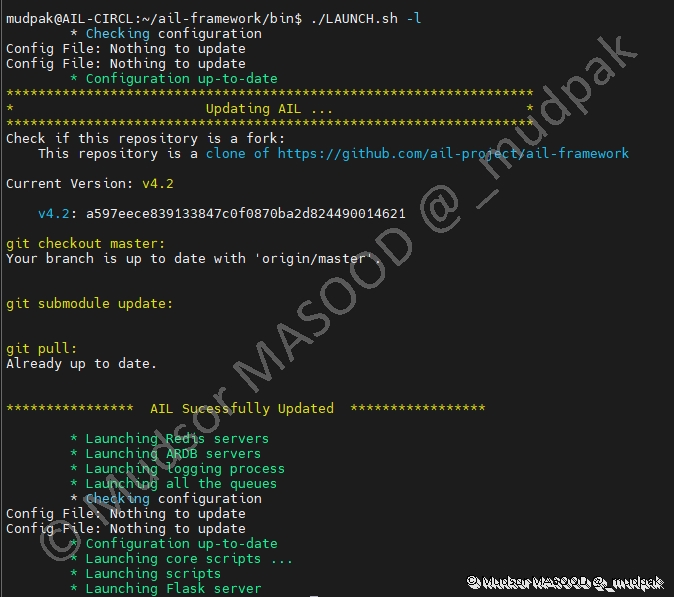
7.2 Kill DB + Scripts
Ce paramètre permet de mettre fin au programme en arrêtant :
- Les services de bases de données
- Les scripts (des différents modules connectés à AIL)

7.3 Scripts
Ce paramètre permet de stopper uniquement les scripts, laissant ainsi la base de données en cours d’exécution :

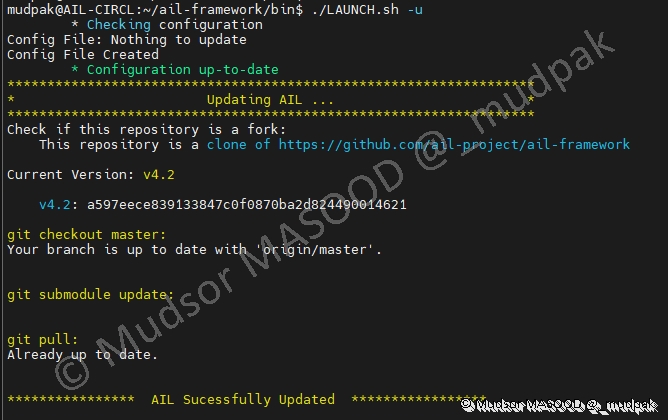
7.4 Update AIL
Ce paramètre permet de mettre à jour la solution :
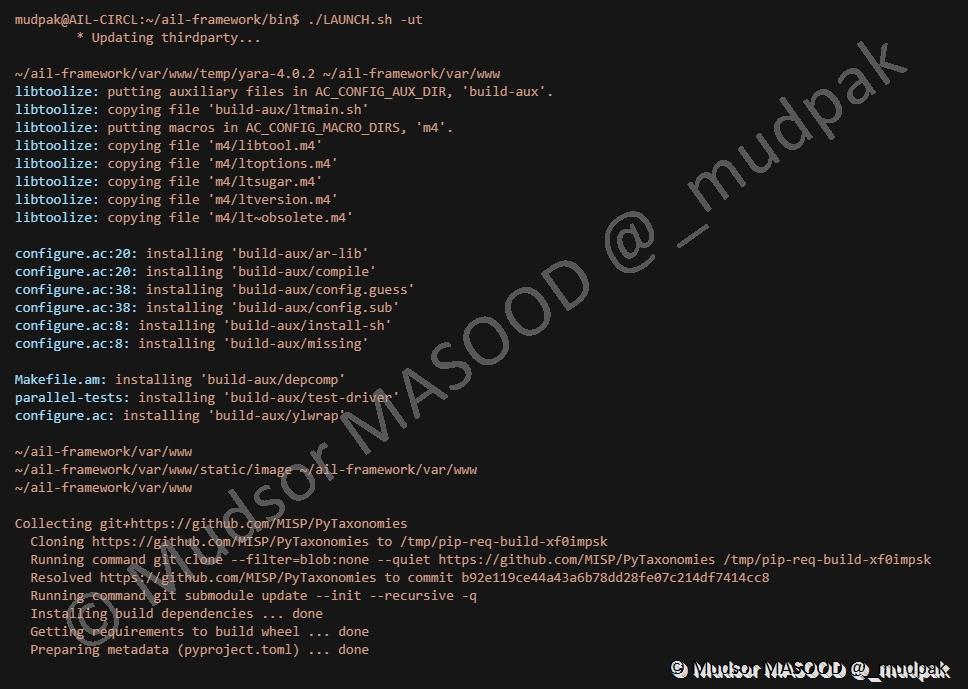
7.5 Update UI/Frontend
Ce paramètre permet de mettre à jour les éléments tiers utilisés :
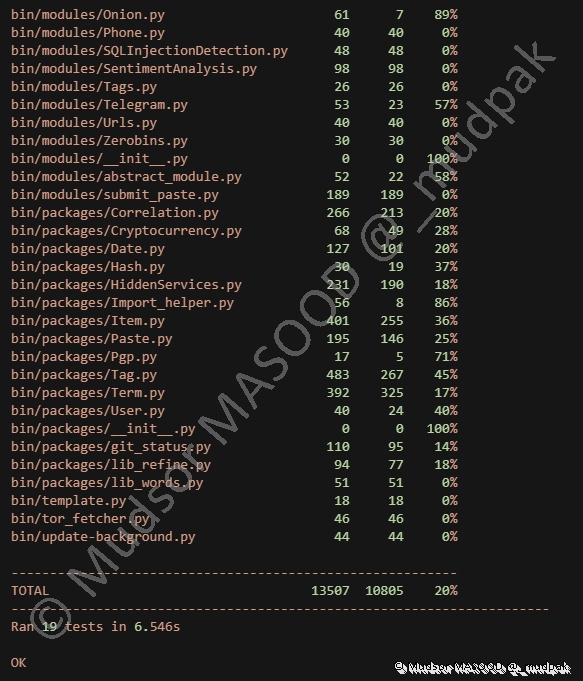
7.6 Launch Tests
Ce paramètre permet de tester le bon fonctionnement de la plateforme :
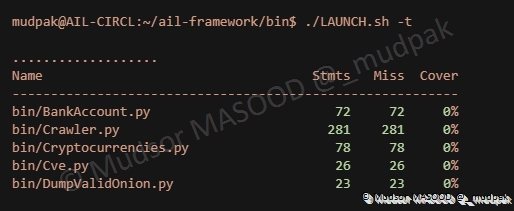
Un certain nombre de modules sont testés, et un résultat est affiché à la fin :
7.7 Reset Password
Ce paramètre permet de réinitialiser le mot de passe du compte administrateur :
7.8 LAUNCH Pystemon feeder
Ce paramètre permet de démarrer le feeder « Pystemon ».
Remarques
Bien que le feeder démarre, il faut penser à la configurer en amont pour avoir des données.
Plus tard nous verrons comment le configurer pour la réception.

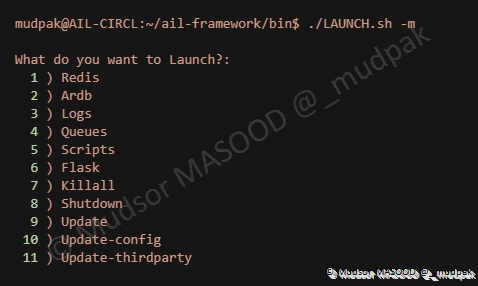
7.9 Display advanced menu
Ce paramètre permet d’accéder au menu avancé :
8. Découverte
Maintenant que l’installation est terminée, nous allons faire un tour des différents menus et pages.
Remarque
Certaines sections ne seront pas vues en détails car je n’ai pas pu mettre en place les fonctionnalités.
Pour rappel il faut utiliser la commande suivante pour lancer l’instance :
1 | |
Remarque
Ici c’est la lettre « l » comme « launch ».
8.1 Accès à l’interface web
Pour accéder à l’interface web, via un navigateur web il faut se rendre à la page suivante :
1 | |

8.1.1 Authentification
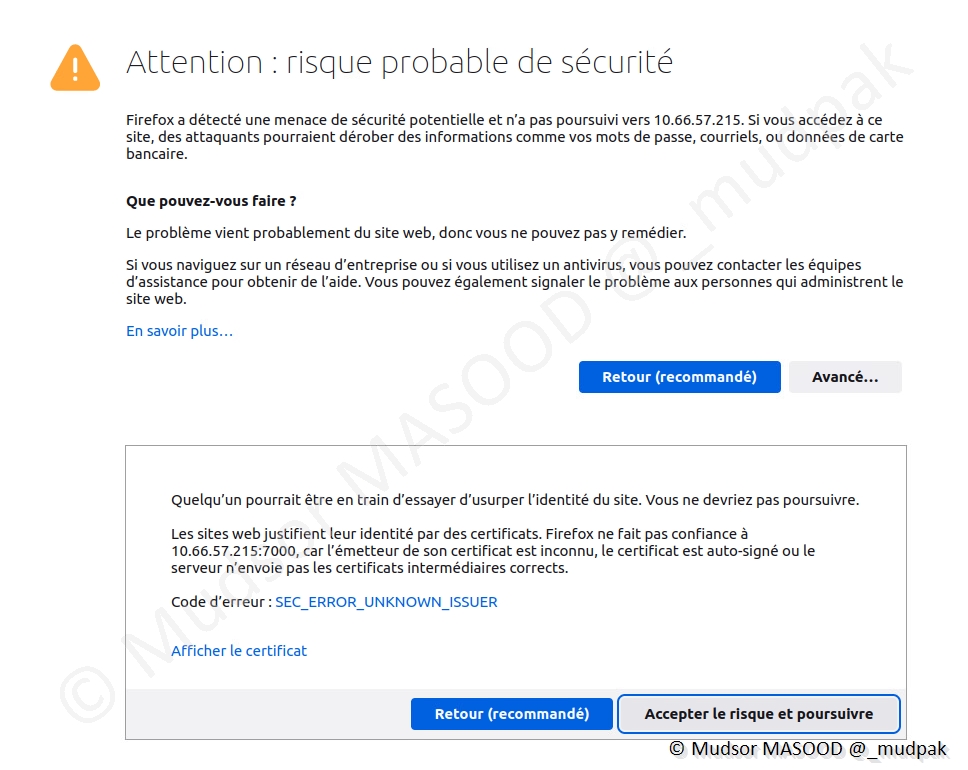
Une mise en garde s’affiche car le certificat est autosigné, cliquer sur
- Avancé. . .
Cliquer sur
- Accepter le risque et poursuivre
Remplir les champs suivants :
- Email address
- Par « admin@admin.test
- Par défaut il n’est pas possible de changer cette adresse email
- Password
- Par le mot de passe aléatoire qui a été généré lors de l’installation
- Par défaut c’est le suivant « G4FP7EabeXfuNPi »
Cliquer sur
- Sign in

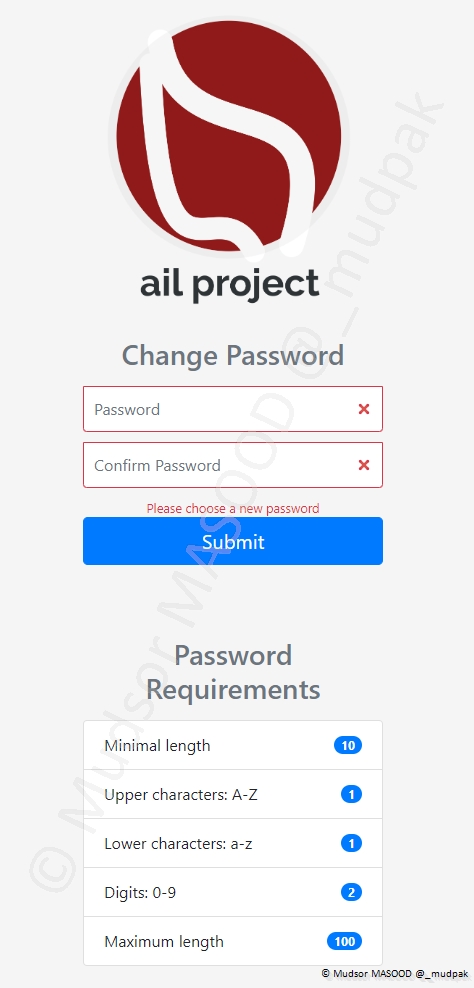
8.1.2 Changement du mot de passe
Lors de la première connexion il faut réinitialiser le mot de passe tout en respectant les critères ci-dessous.
Remplir les champs suivants :
- Password
- Confirm Password
Cliquer sur
- Submit
8.2 Home
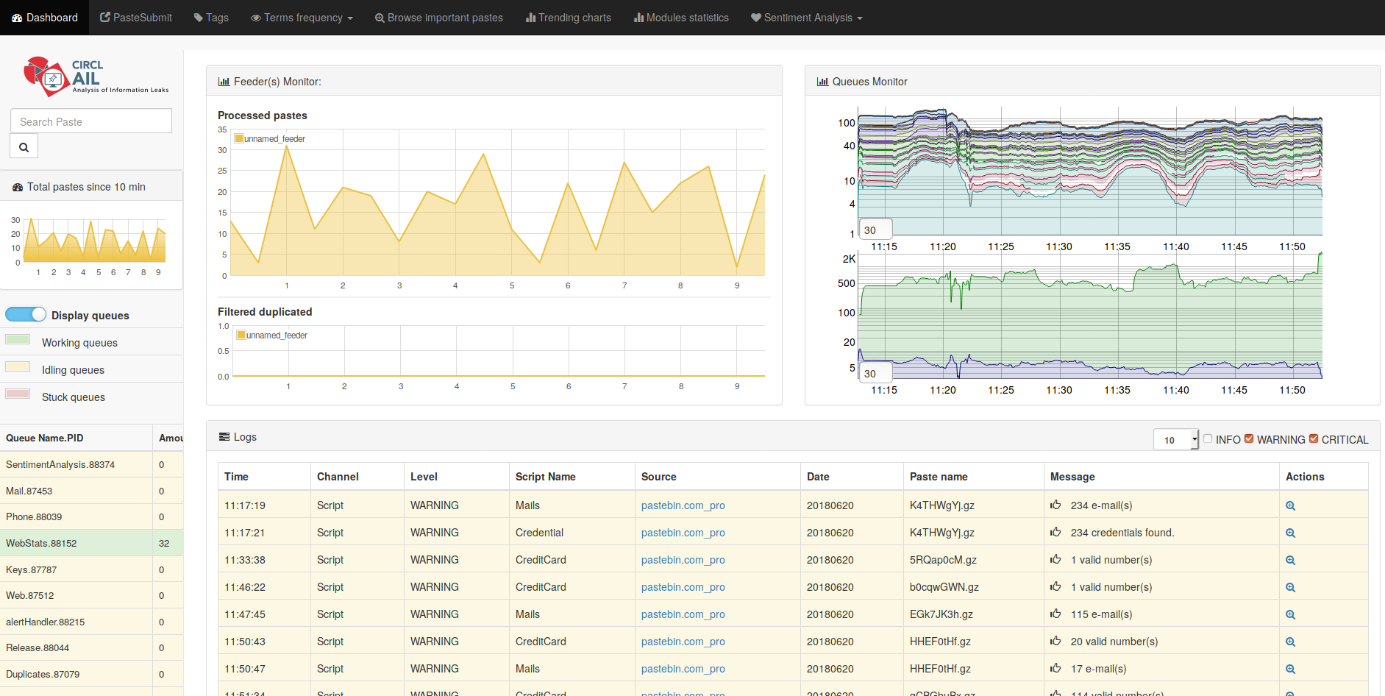
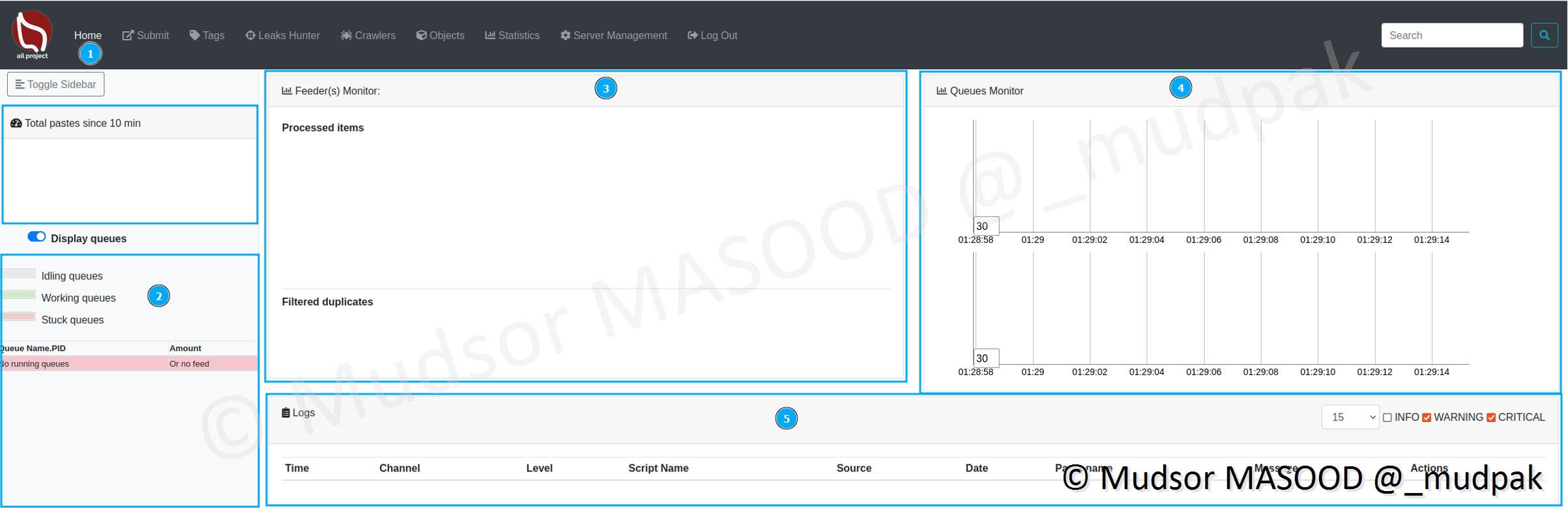
Voici la page d’accueil de la plateforme et ses différentes sections qui seront vues en détails par la suite :
- 1 : Home
- 2 : Queues
- 3 : Feeder(s) Monitor
- 4 : Queues Monitor
- 5 : Logs
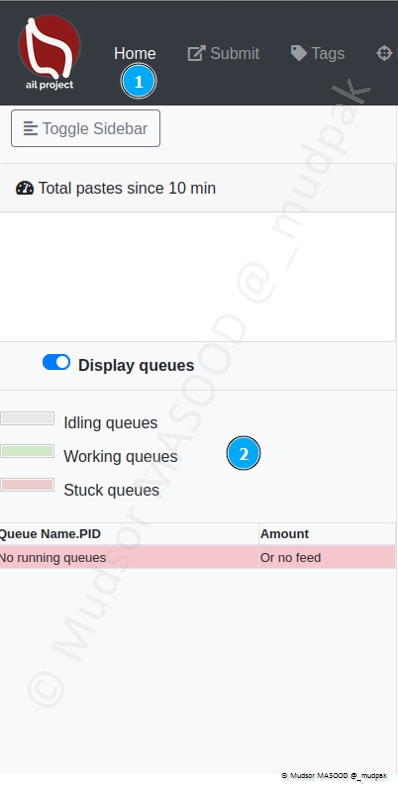
8.2.1 Total pastes since 10 min
Dans cette partie va afficher un graphe pour donner un aperçu du nombre de fichiers analysés.
8.2.2 Display queues
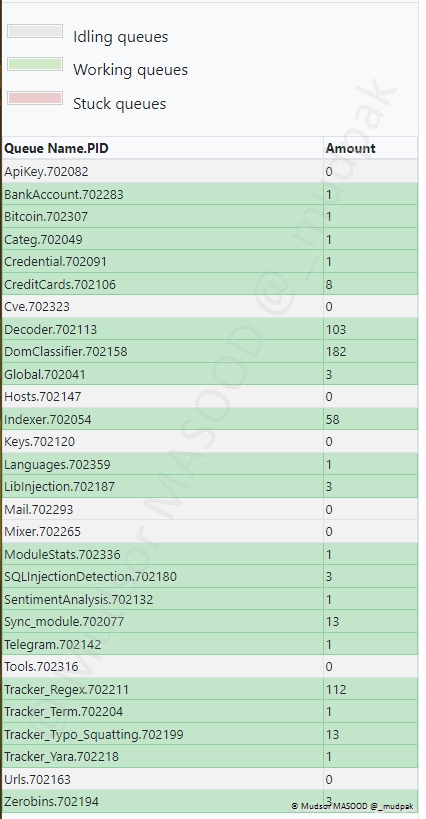
Cette section est dédiée aux files d’attentes et à leur état :
- Inactif
- En cours
- Bloqué
Nous aurons également des détails plus précis sur les types d’éléments en cours de traitement.
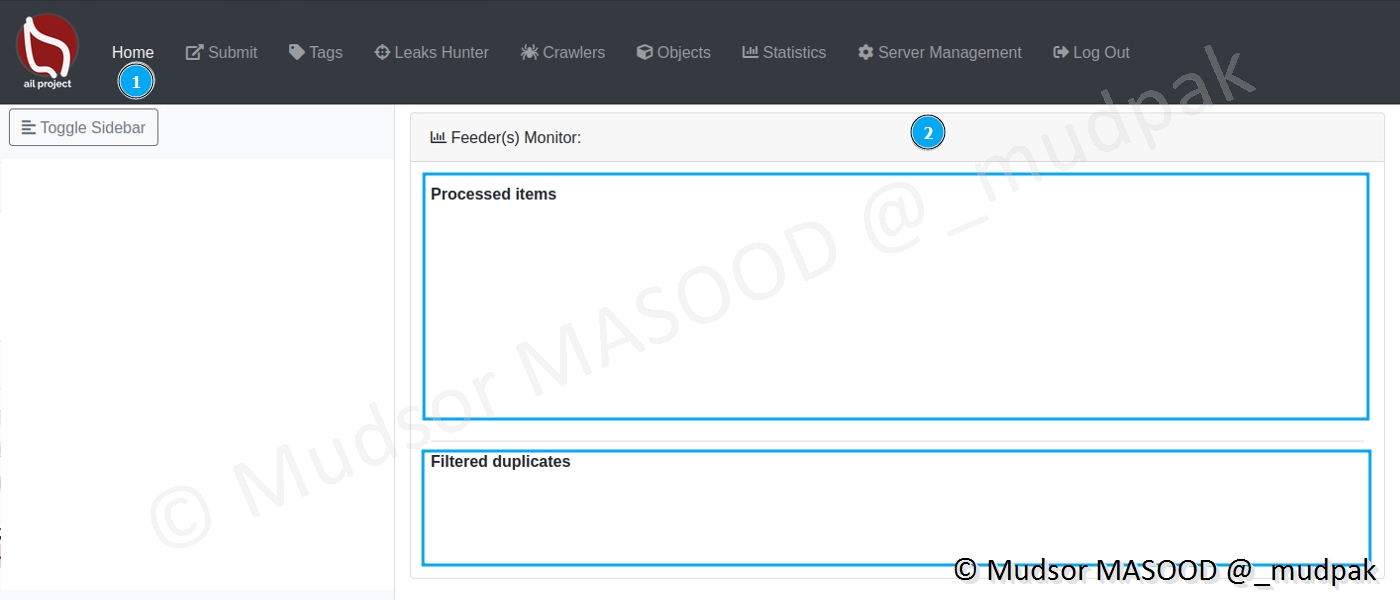
8.2.3 Feeder(s) Monitor
Cette section va afficher :
- Processed Items : un graphe sur les éléments traités
- Filtered duplicates : un graphe sur les doublons détectés et traités
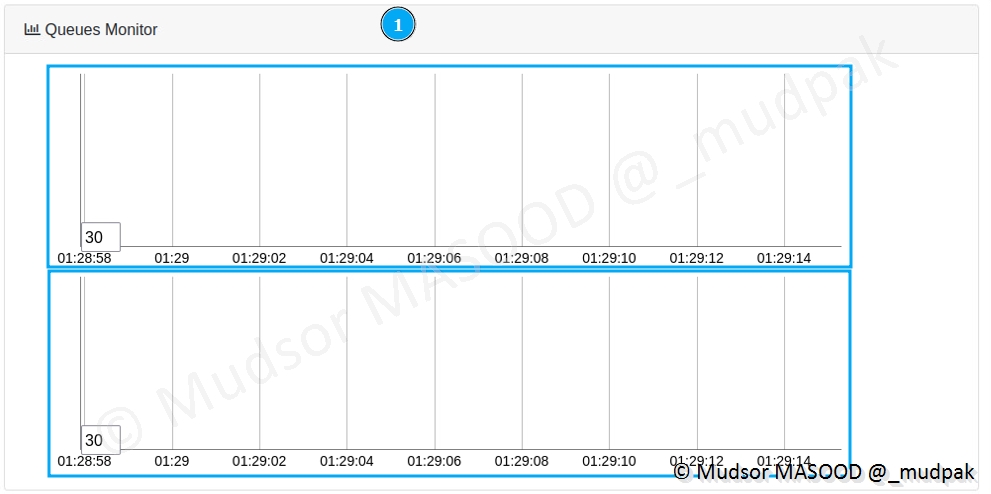
8.2.4 Queues Monitor
Cette section va afficher :
- 1er graphe (zone supérieure) : différents types d’éléments traités
- 2nd graphe (zone inférieure) : les catégories d’éléments traités
8.2.5 Logs
Cette section va afficher :
- 1 : les journaux d’événements
- 2 : les heures, minutes et secondes au format international (24h), le fuseau horaire utilisé sera local
- 3 : par quelles méthodes les données ont été retrouvées (script ? autre ?)
- 4 : quel est le niveau d’alerte (Info, Warning, Critical), il est également possible de filtrer les alertes via la partie située à droite du menu
- 5 : quelles sont les types de données trouvées ? (Clé API ? Email ? . . .)
- 6 : quelle est la source des données ? Avec le lien original pour récupérer le leak complet
- 7 : date au format international, à laquelle les informations ont été trouvées
- 8 : quel est le nom de l’archive où se trouvent les données
- 9 : combien d’éléments ont été trouvés ? (12 Emails, 1 Clé API . . .)
- 10 : il est possible de consulter les informations et ensuite effectuer différentes opérations (investiguer, envoyer vers MISP, télécharger. . . )

8.3 Submit
Cette section permet d’envoyer les données pour qu’elles soient analysées, ainsi si nous souhaitons analyser des données trouvées via d’autres sources il est tout à fait possible de les soumettre à AIL.
Il existe deux types de soumissions de données :
- Soumission de fichier
- Soumission de contenu texte
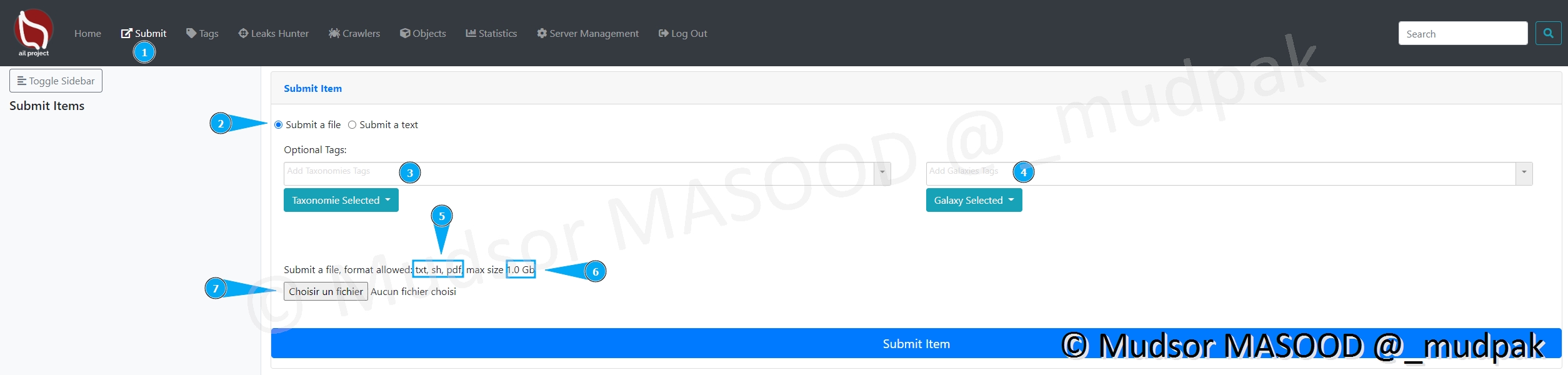
8.3.1 Submit a file
Voici les différentes sections de cette page :
- 1 : Page pour accéder à la section
- 2 : ici nous avons choisi le type de soumission « fichier)
- 3 : il est possible d’ajouter des tags en amont, un aperçu de la liste est visible plus bas
- 4 : pour ajouter un tag de Galaxy
- 5 : nous pouvons soumettre des fichiers mais ils doivent respecter les formats suivants
- txt : fichier texte
- sh : script bash
- pdf : document de type PDF
- 6 : il faut respecter une taille maximale, dans notre cas elle ne doit pas dépasser 1Go
- 7 : pour sélectionner un fichier un explorateur de fichiers s’ouvre
Voici un extrait des tags disponibles qui peuvent être appliqués :
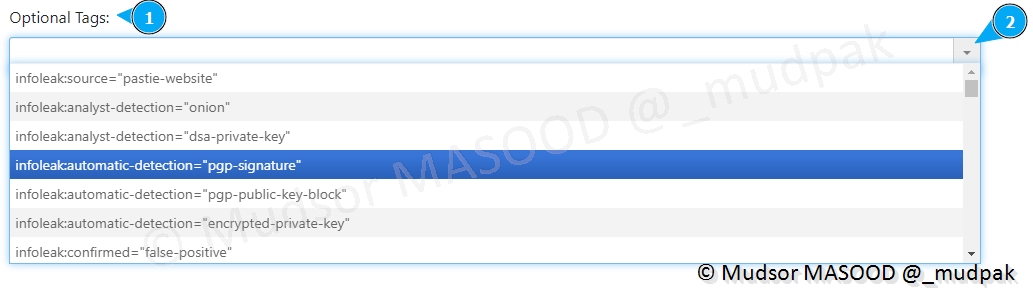
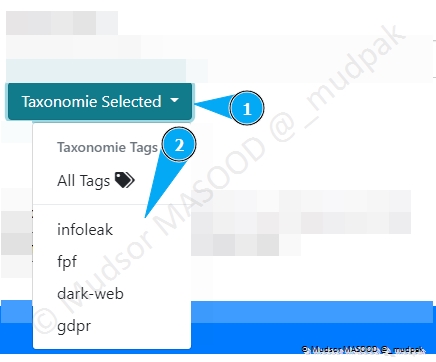
Pour ce qui est des tags de Taxonomie, il y a également une liste proposée :
Pour les Galaxy voici les choix proposés par défaut :
8.3.2 Submit a text
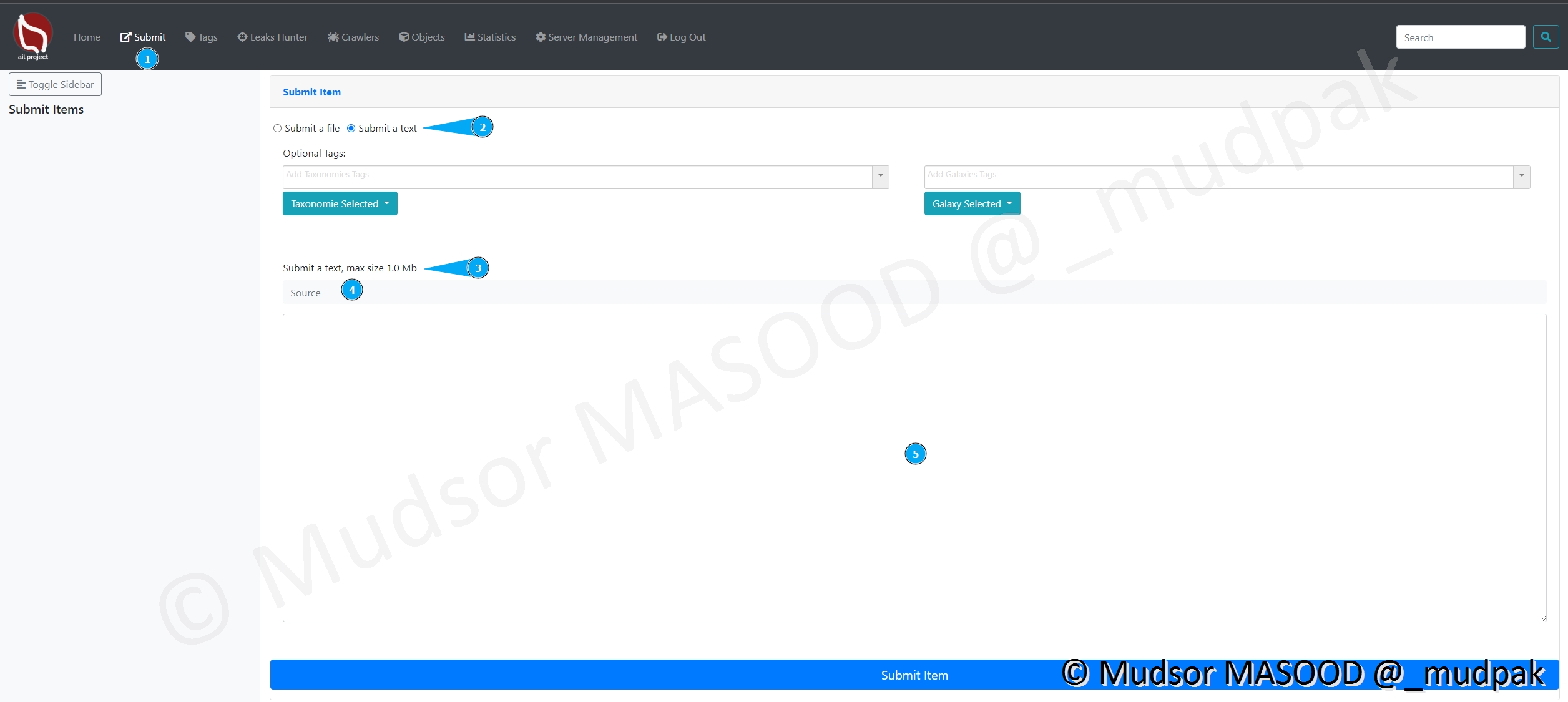
Pour soumettre un texte voici les différents éléments :
- 1 : le page pour accéder à la section
- 2 : il faut choisir le type « text »
- 3 : le fichier ne doit pas dépasser 1Mo
- 4 : ?
- 5 : la zone où il faut insérer le texte
8.4 Tags
Les données auront un tag de différentes manières :
- Tag automatique : le Framework classe et attribue un tag selon ses règles prédéfinies
- Tag ajouté manuellement : ajout manuel de tags
Voici les différentes sections de cette page :
- 1 : page pour accéder à la section
- 2 : Tags Search
- 3 : Tags Management
- 4 : Tags Export
- 5 : Quick Search
- 6 : Search Items by Tags
- 7 : Date de début de la recherche
- 8 : Date de fin de la recherche
- 9 : Sélectionner des Tags
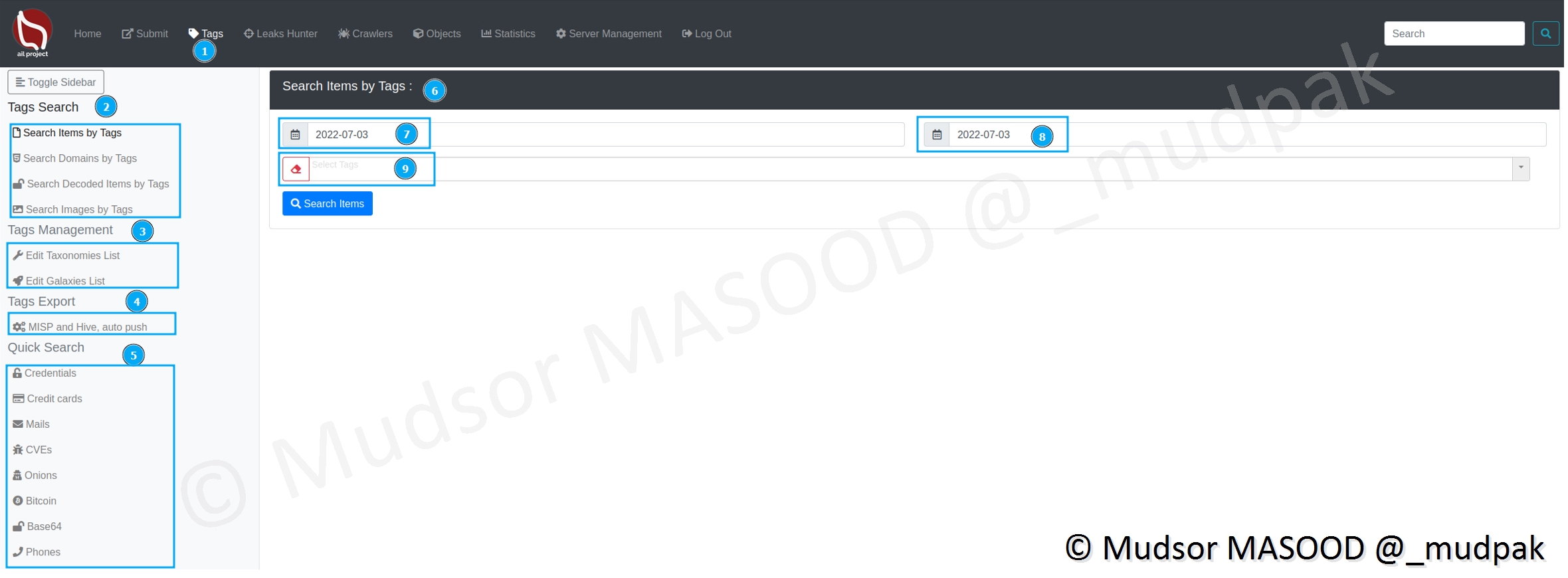
8.4.1 Tags Search
Il est possible rechercher les éléments suivants via un tag :
- Search Items by Tags : rechercher tous les éléments
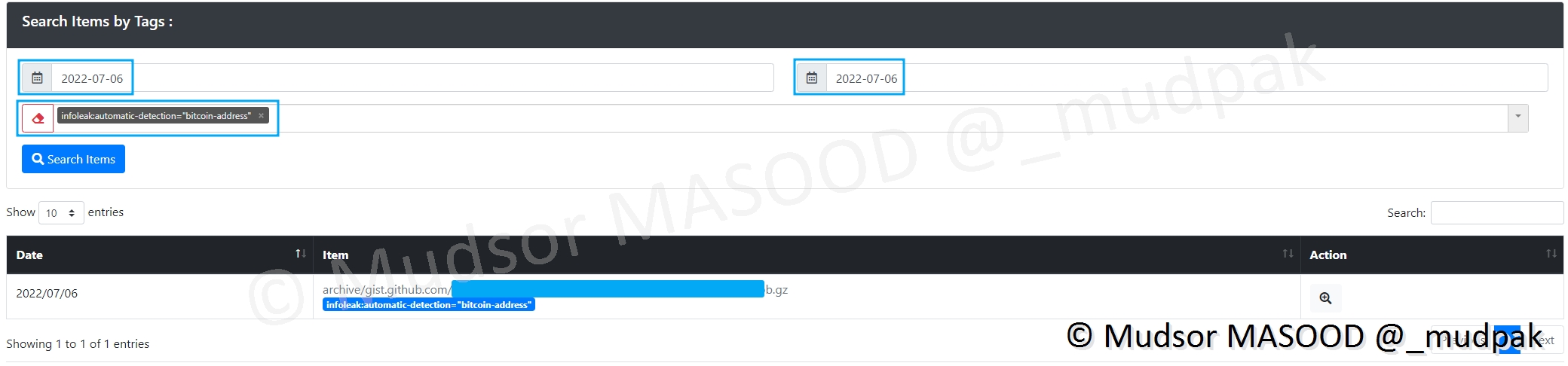
- Search Domains by Tags : recherche de noms de domaines
- Search Decoded Items by Tags : recherche d’éléments décodés
- Search Images by Tags : recherche d’images
Remarque
Pour ma part seulement le premier type de recherche « Search Items by Tags » a fonctionnée.
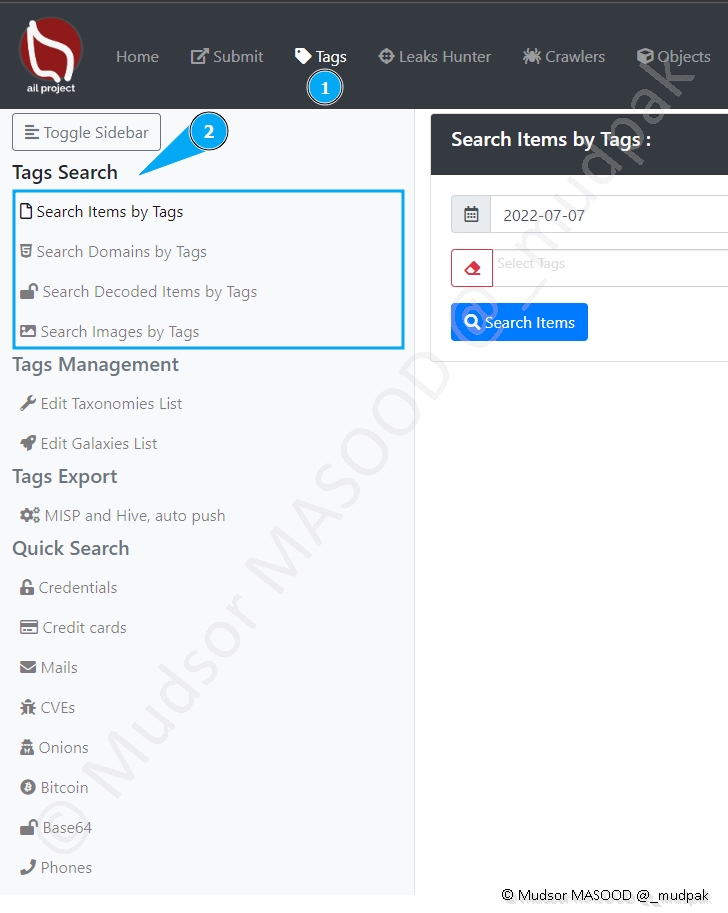
Pour effectuer une recherche il faut spécifier une date de début (à gauche) et une date de fin (à droite).
Un calendrier s’ouvre et vous pouvez sélectionner ces périodes en cliquer sur les deux périodes.
Vous pouvez appliquer des Tags pour que les résultats soient plus pertinents, voici un extrait des tags disponibles :

8.4.2 Tags Management
Cette section ne sera pas vue en détails dans cet article, néanmoins nous allons rapidement parcourir les différents menus de celle-ci.
Cliquer sur
- Tags
- Tags Management
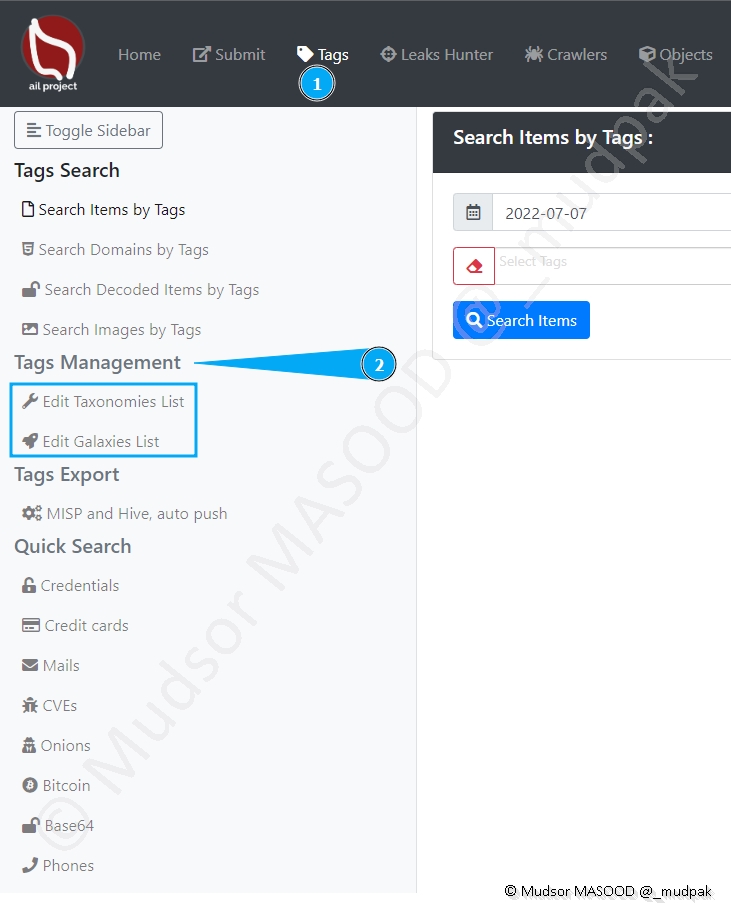
8.4.2.1 Edit Taxonomies List
Cliquer sur
- Tags
- Edit Taxonomies List
Voici les différents éléments affichés :
- 1) les noms
- 2) les descriptions
- 3) les versions
- 4) si les tags sont actifs ou non
- 5) les tags associés et leur nombre
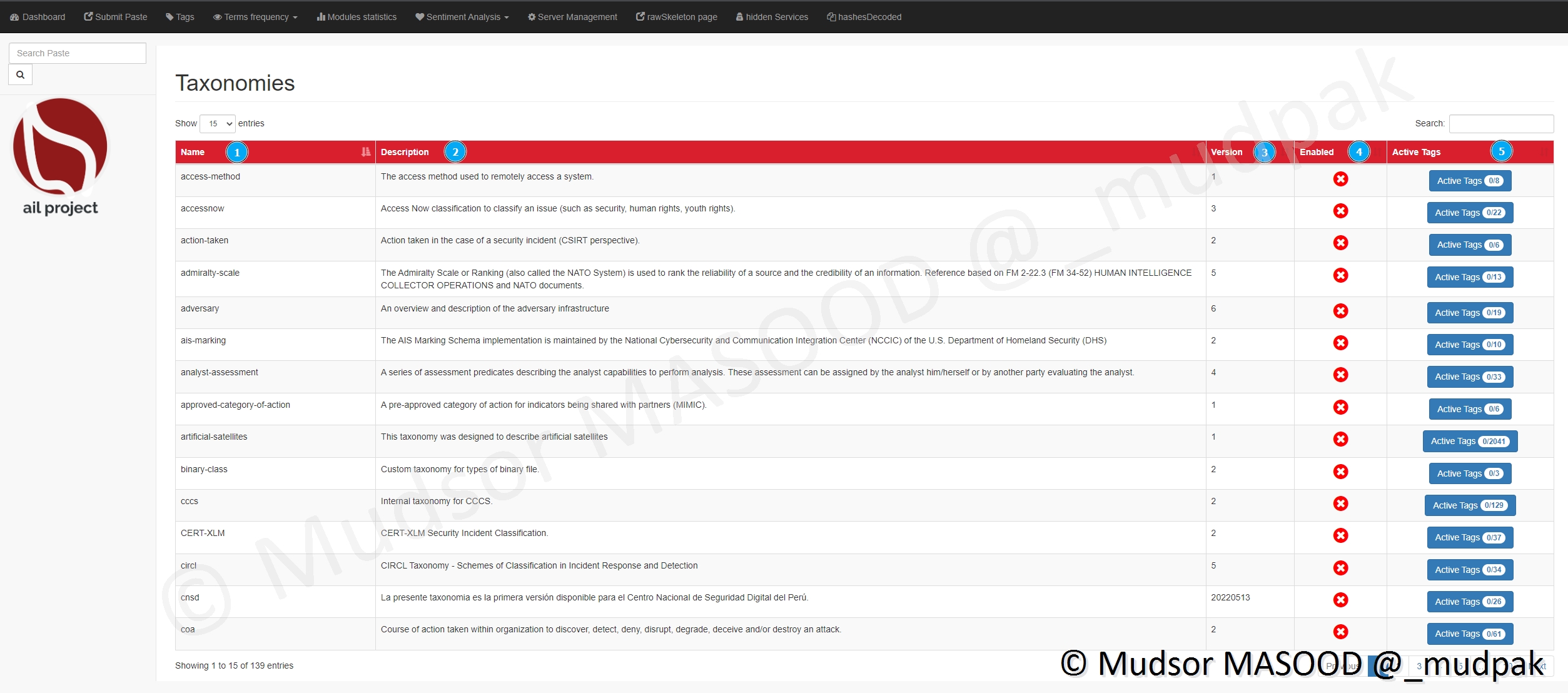
Si nous prenons l’exemple de la taxonomie « access-method », voici les informations que nous avons :
- 1) le nom de la taxonomie
- 2) les tags associés
- 3) les descriptions
- 4) si les tags sont actifs ou non
- 5) si nous souhaitons activer la taxonomie
8.4.2.2 Edit Galaxies List
Cliquer sur
- Tags
- Edit Galaxies List
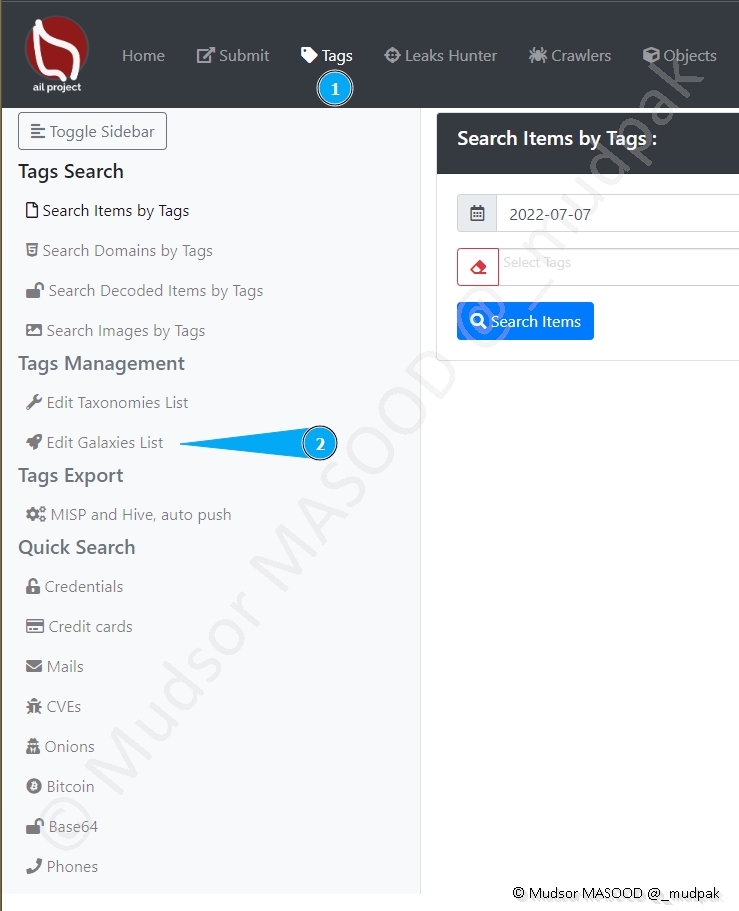
Voici les différentes informations affichées :
- 1) les noms
- 2) les descriptions
- 3) dans quels environnements elles sont utilisées
- 4) les versions
- 5) si elles sont actives ou non
- 6) le nombre de tags associés
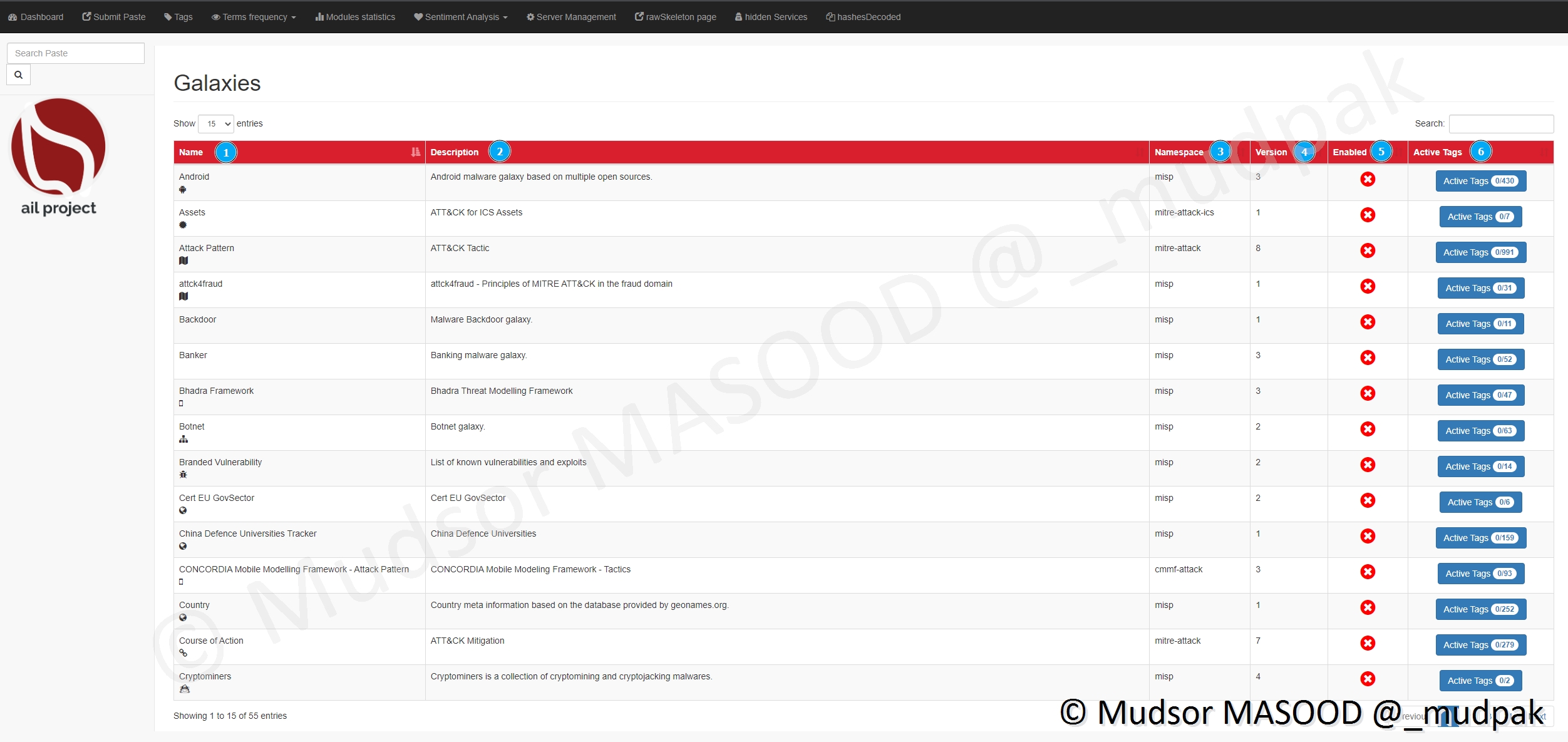
Si nous prenons l’exemple de la Galaxie « Android », voici les informations que nous obtenons :
- 2) les tags associés
- 3) les descriptions
- 4) si elles sont activées ou non
- 5) pour activer la Galaxie
8.4.3 Tags Export
Il est possible d’exporter les tags vers des instances telles que :
- MISP
- TheHive
Pour accéder au menu, cliquer sur :
- Tags
- Tags Export > MISP and Hive, auto push
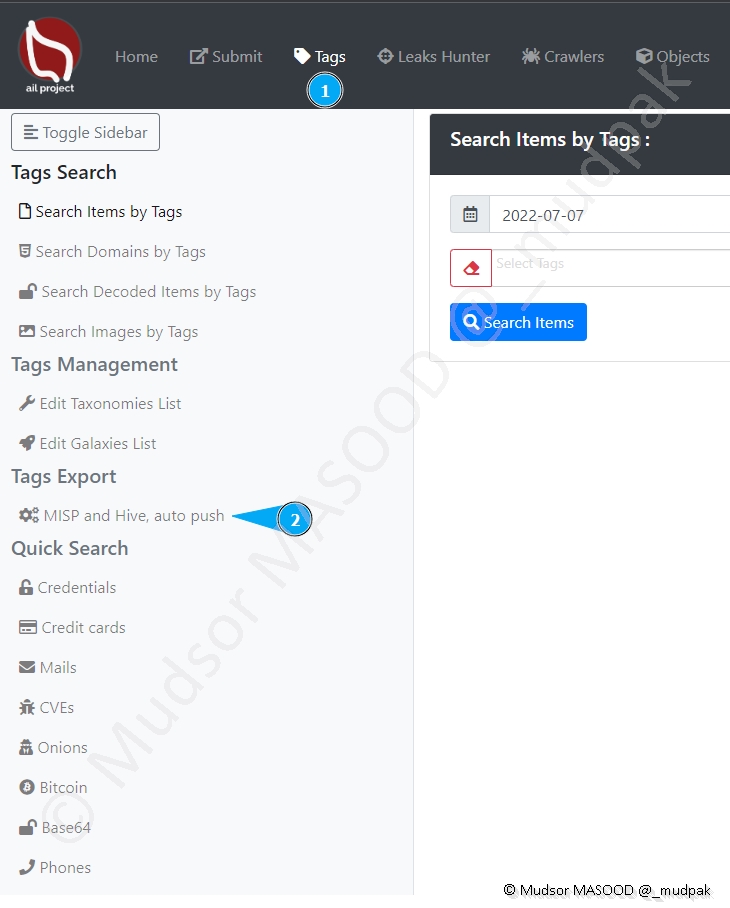
Nous pouvons observer différents éléments :
- 1 : un espace est dédié pour MISP
- 2 : un espace est dédié pour Hive
- 3 : le connecteur n’est pas connecteur à une instance MISP
- 4 : le connecteur n’est pas connecteur à une instance Hive
- 5 : il faut cocher une case pour activer le tag
- 6 : les détails du tag
- 7 : si des modifications ont été apportées il faut penser à mettre à jour les tags
- 8 : il est possible d’ajouter de nouveaux tags

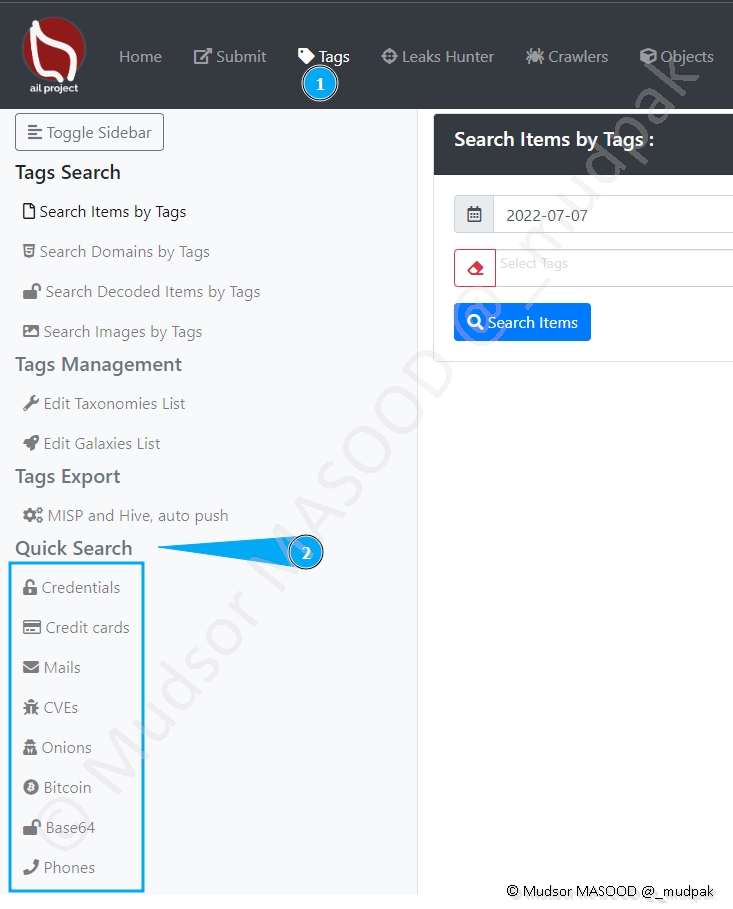
8.4.4 Quick Search
Il est possible d’effectuer une recherche rapide sur les différents types d’éléments, cliquer sur
- Tags
- Quick Search
Voici les différents types d’éléments qu’il est possible de trouver :
- Credentials : identfiants et mots de passe divers
- Credit cards : numéros de cartes bancaires
- Mails : adresses emails
- CVEs : références à des numéros de CVEs
- Onions : sites avec des extension « .onion » (=réseau TOR)
- Bitcoin : adresses de wallet ou transactions en bitcoin
- Base64 : éléments encodés en base64
- Phones : numéros de téléphones
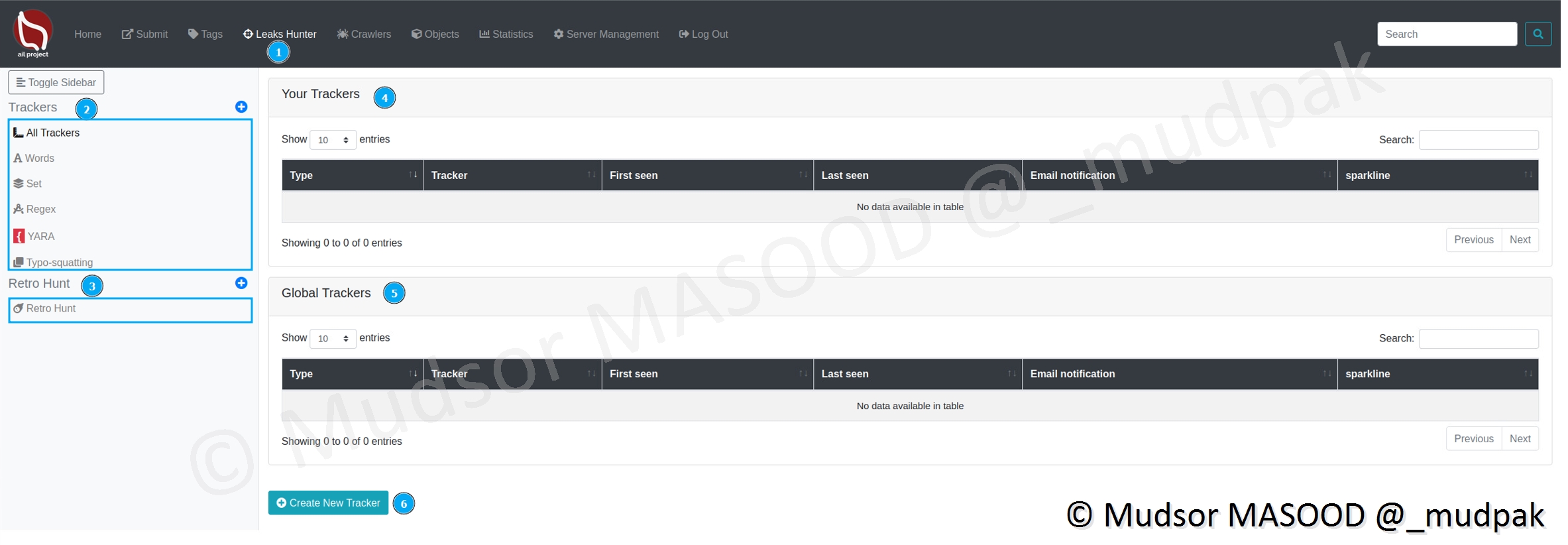
8.5 Leaks Hunter
Cette fonctionnalité permet de trouver des leaks correspondants à certains critères (mots, regex, règles YARA. . .).
Pour accéder à cette section, cliquer sur
- Leaks Hunter
Différents éléments sont affichés :
- 2 : All Trackers : différents types de trackers qu’il est possible de définir
- 3 : Retro Hunting : ?
- 4 : Your Trackers : les trackers qui sont créés par chaque utilisateur
- 5 : Global Trackers : tous types de trackers sont affichés ici
- 6 : Create New Tracker : il est possible de créer nos trackers, c’est ce que nous allons faire par la suite
8.5.1 Trackers
Cette section permet d’effectuer des recherches via différents critères :
- Words : recherche basée sur des mots prédéfinis
- Set : recherche basée sur un ensemble de mots prédéfinis
- Regex : recherche basée sur un expression régulière
- YARA : recherche basée sur une règle YARA
- Typo-squatting : (?)
Pour créer un nouveau tracker, cliquer sur le symbole « + » :
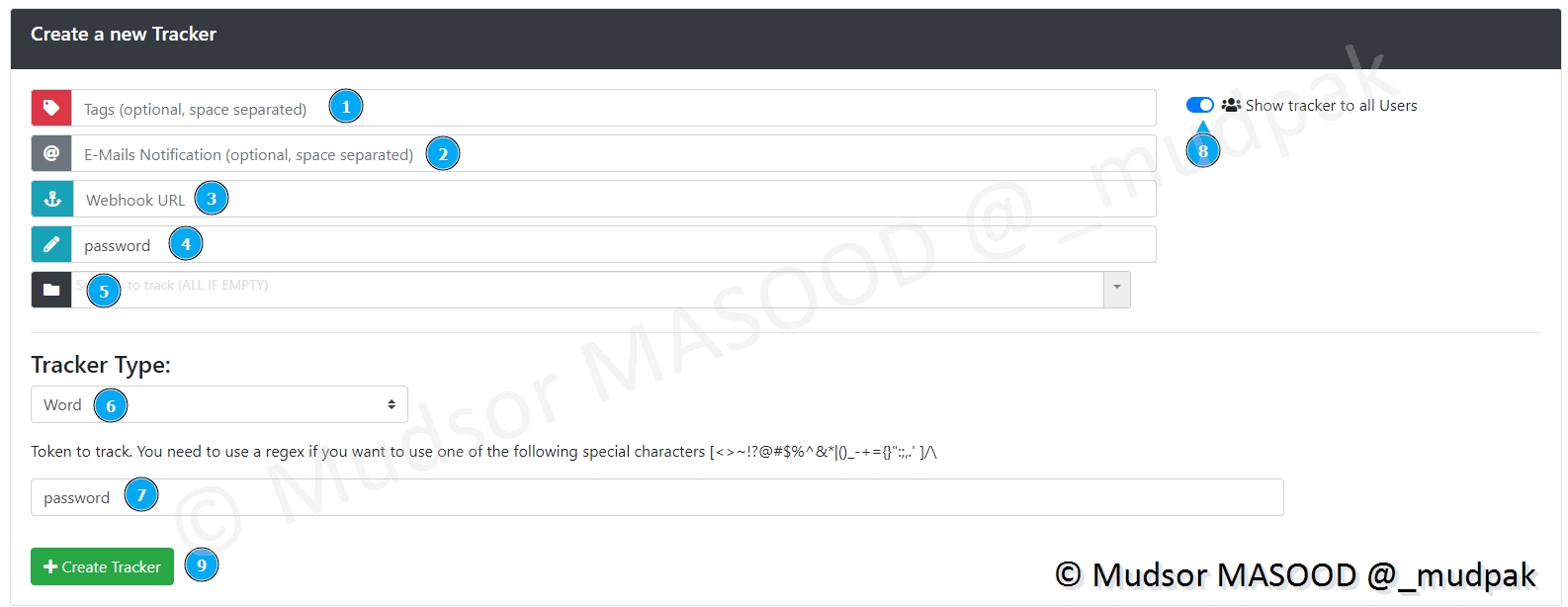
Il faut remplir un certain nombre de champs (ils ne sont pas tous obligatoires) :
- 1 : si vous souhaitez définir des tags
- 2 : si vous souhaitez être notifié par email lorsqu’un match va se produire avec ce tracker
- 3 : ?
- 4 : une description qui permet d’avoir des détails sur cette création
- 5 : ?
- 6 : le type de tracker que nous souhaitons définir, ici un simple mot
- 7 : la valeur du tracker, ici « password »
- 8 : est-ce que vous souhaitez rendre visible le tracker pour tous les utilisateurs de la plateforme ?
- 9 : pour valider la création du tracker
Voici un exemple avec un tracker de type « Regex » qui permet de trouver des clés API Google.
Remarque
Une liste de regex est disponible dans les sources de cet article ;).

8.5.2 Retro Hunt
Je n’ai pas eu le temps d’explorer cette section pour l’instant.
8.6 Crawlers
Cette section très intéressante permet comme son nom l’indique de crawler des sites internet qu’ils soient accessibles sur le
- Surface web
- Deep web
- Dark web
Les crawlers sont utilisés de différentes manières pour par exemple prendre des instantanés des sites web.
Pour accéder à la section, cliquer sur
- Crawlers

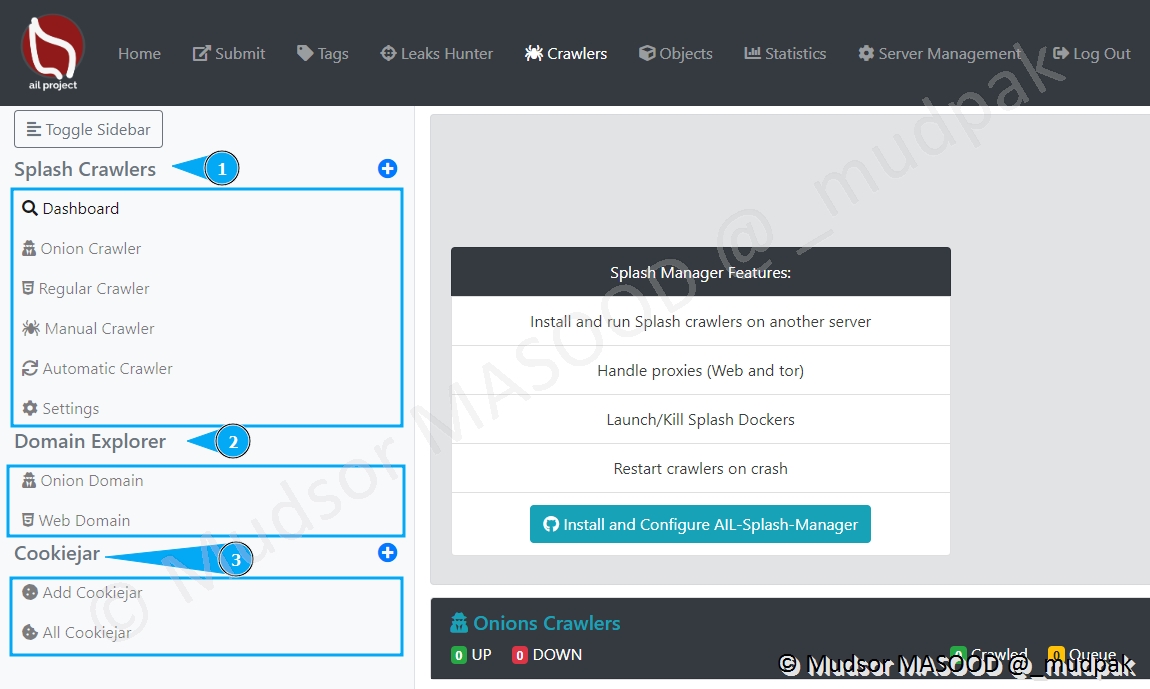
Voici les différents menus de cette section :
- 1 : les différents types de crawlers
- 2 : différents types d’explorateurs de domaines
- 3 : espace pour pré-enregistrer les cookies à utiliser par les crawlers
Nous pouvons observer que par défaut :
- 1 : le crawler est désactivé
- 2 : un lien est fourni pour télécharger et le mettre en place
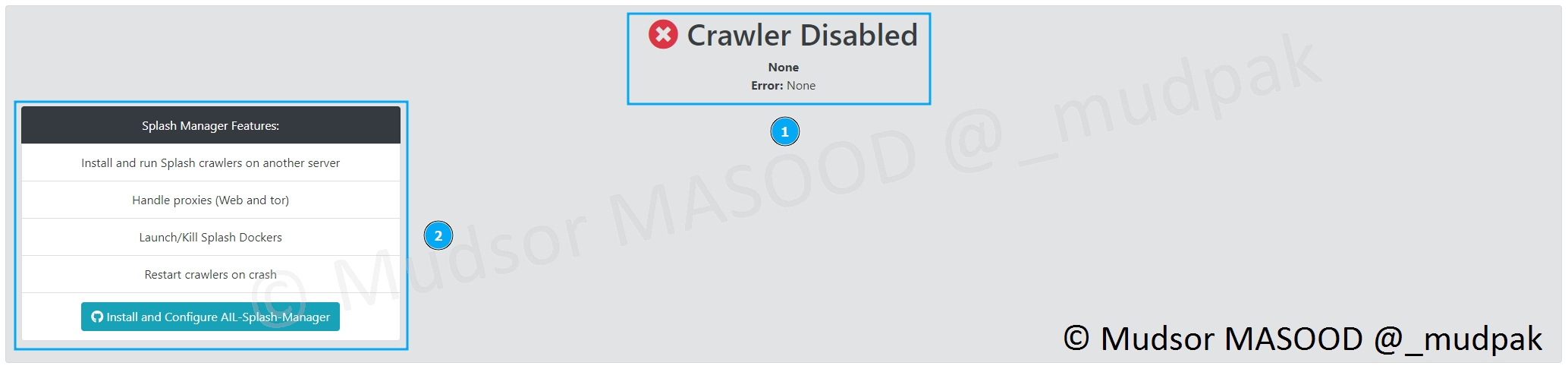
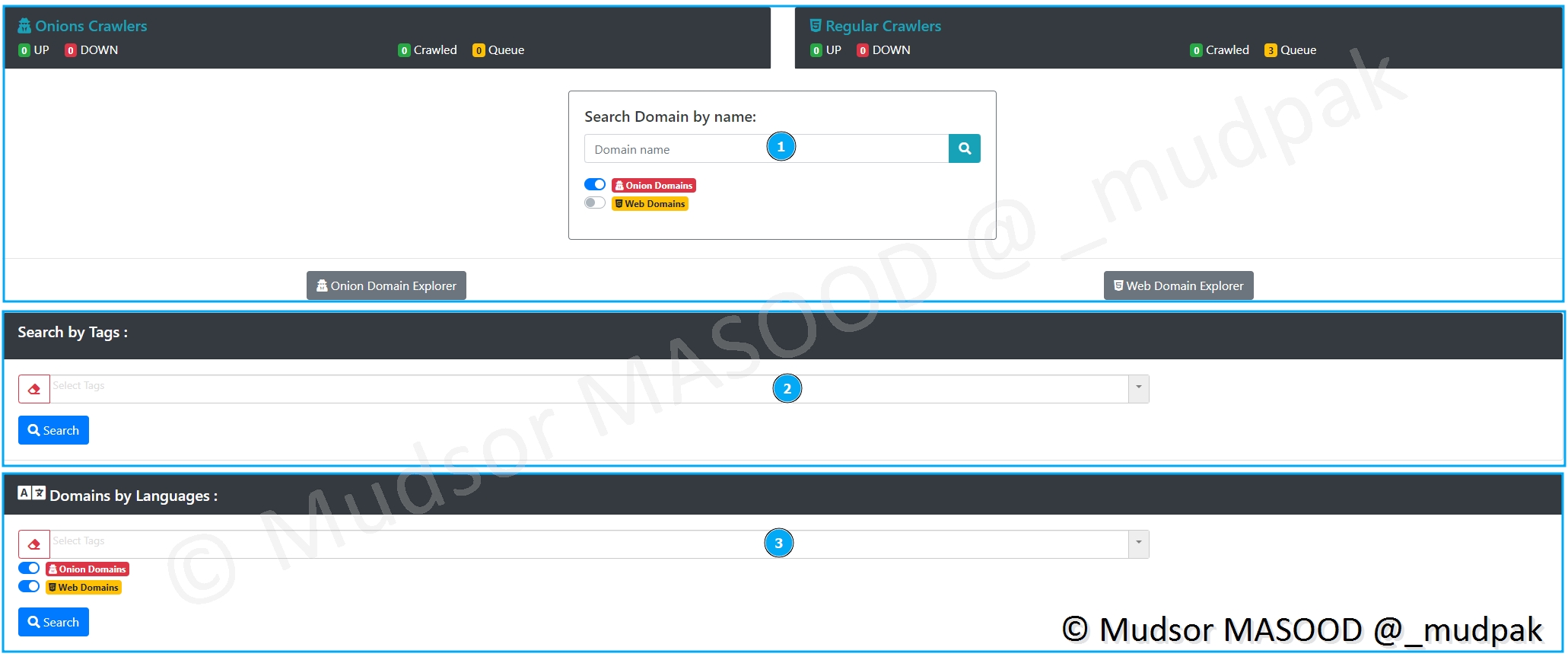
Le reste de la page se divise en trois grandes zones :
- 1 : l’état général des crawlers Onions et Regular
- 2 : la recherche par tags
- 3 : la recherche par langue
8.6.1 AIL Splash-Manager
Avant d’explorer les autres menus, nous allons mettre en place le crawler pour avoir des données à visualiser et mieux représenter les fonctionnalités.
Nous allons partir du principe que la plateforme est arrêtée, si ce n’est pas le cas saisir la commande suivante dans le dossier « ail-framework/bin » :
1 | |
8.6.1.1 GitHub
Le programme est disponible à l’adresse suivante :
1 | |

8.6.1.2 Récupération du script
Pour le récupérer, saisir la commande suivante :
1 | |
8.6.1.3 Installation
Nous allons nous rendre dans le répertoire crée lors de la phase précédente :
1 | |
Un certain nombre d’éléments sont présents dans le répertoire, l’élément principal qui nous intéresse dans le cas présent se nomme « install.sh » :
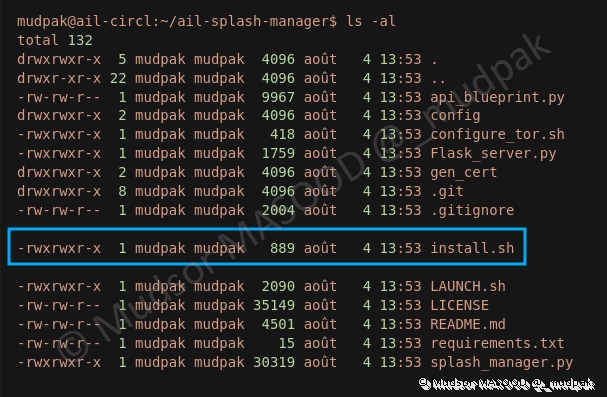
Pour initier l’installation, saisir la commande suivante :
1 | |

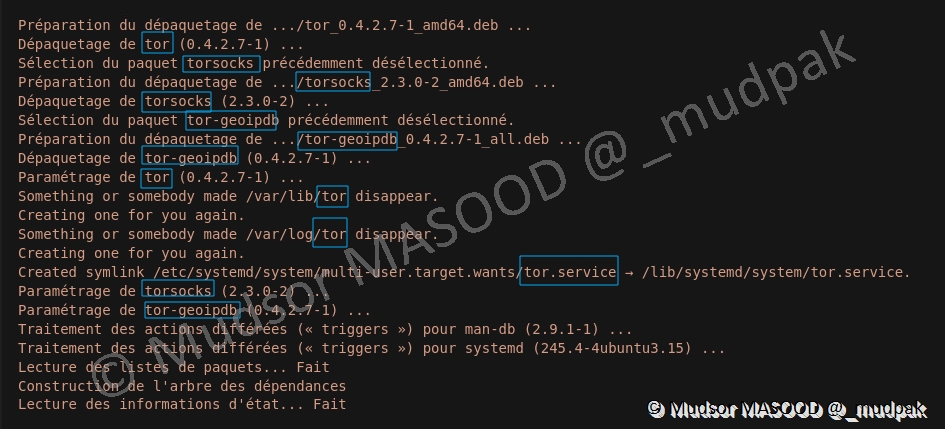
Ici nous pouvons observer que tor est installé ainsi que d’autres de ses modules :
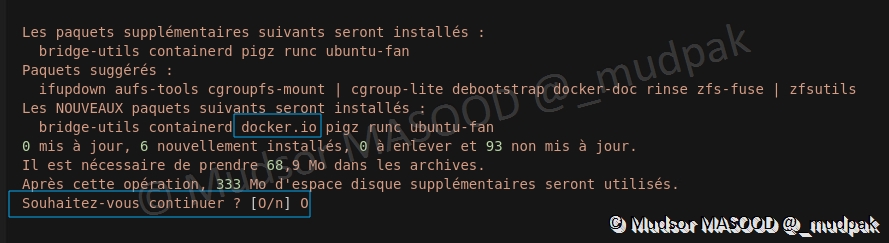
Il est intéressant de noter que « docker » est également installé, en effet des containers docker vont fonctionner et effectuer les opérations de crawling pour nous en passant par les relais/proxy :
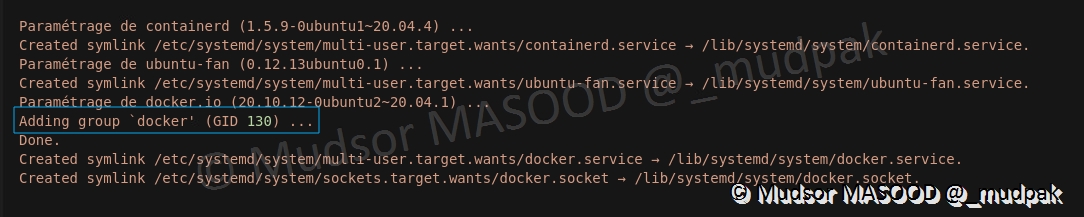
Ici nous pouvons observer le GID (GroupID) de docker :
Le container « scrapinghub/splash » dans sa version la plus récente est récupéré :

Des dépendances python sont installées :
L’étape finale permet de générer des certificats :
Nous pouvons voir que les certificats sont bien présents :
8.6.1.4 Lancement de AIL Splash-Manager
Pour le premier lancement je vous conseille de procéder en deux phases
- Lancer AIL Splash-Manager depuis son répertoire
- Lancer AIL Framework
En effet au premier lancement de AIL Splash-Manager, un fichier nommé « token_admin.txt » va être généré et il contient le token qu’il faudra renseigner dans l’interface web par la suite.
Pour lancer AIL Splash-Manager, saisir la commande suivante :
1 | |

8.6.1.5 Génération du Token
Nous pouvons observer qu’en plus des certificats précédemment générés, le fichier « token_admin.txt » a bien été créé.
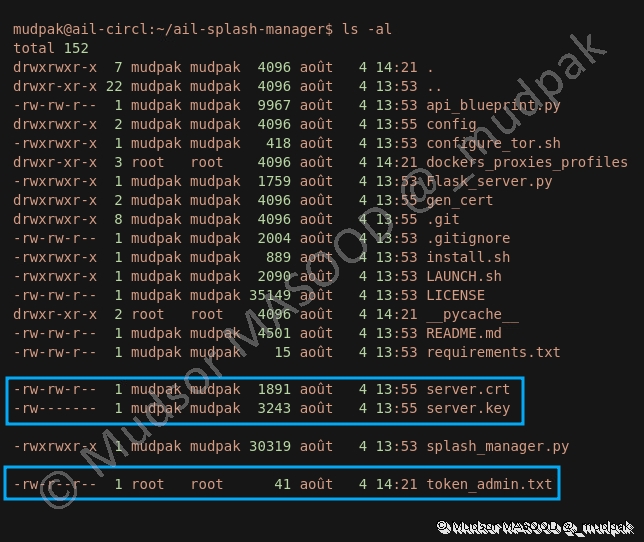
Voici un exemple de token qu’on peut obtenir :

8.6.1.6 Lancement de AIL
Pour lancer AIL ainsi, se rendre dans le répertoire « ail-framework/bin » et saisir la commande suivante :
1 | |
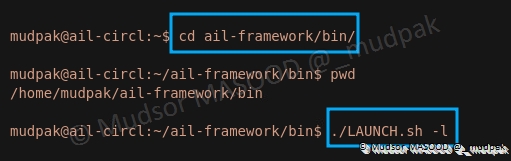
En plus des autres modules, le serveur Flask est lancé :
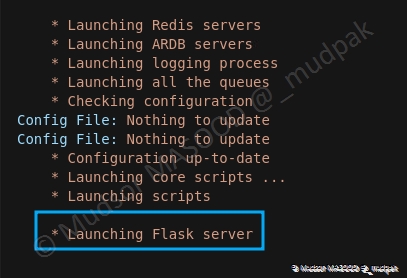
8.6.1.7 Vérification des containers
En parallèle nous pouvons aussi voir que les containers sont bien lancés.
A ce stade il nous reste deux étapes à effectuer avant de pouvoir utiliser les crawlers.

8.6.1.8 Splash Crawler Manager
Il faut configurer :
- L’adresse URL du Splash Manager
- La clé API à utiliser : le token précédemment généré
Cliquer sur
- Crawlers
- Settings
Remplir les champs suivants :
- Splash Manager URL
- Par "https://127.0.0.1:7001"
- API Key
- Par le token
Cliquer sur
- Edit
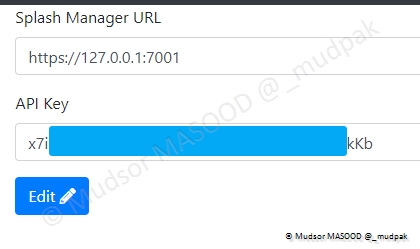
Si l’opération se déroule avec succès, vous pourrez observer « Connected » dans la zone supérieur droite de la fenêtre :
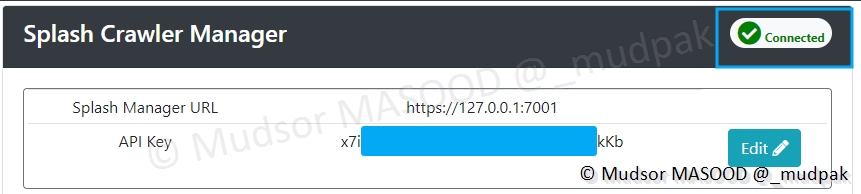
8.6.1.9 Number of Crawlers to Launch
Sur la même page cliquer sur
- Edit number of crawlers to launch
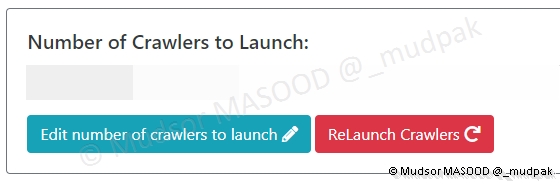
Saisir un chiffre, dans notre cas nous avons choisi d’avoir 5 launchers, cliquer à nouveau sur
- Edit

Une fois les modifications effectuées nous pouvons voir que le crawler ainsi que le proxy sont fonctionnels :
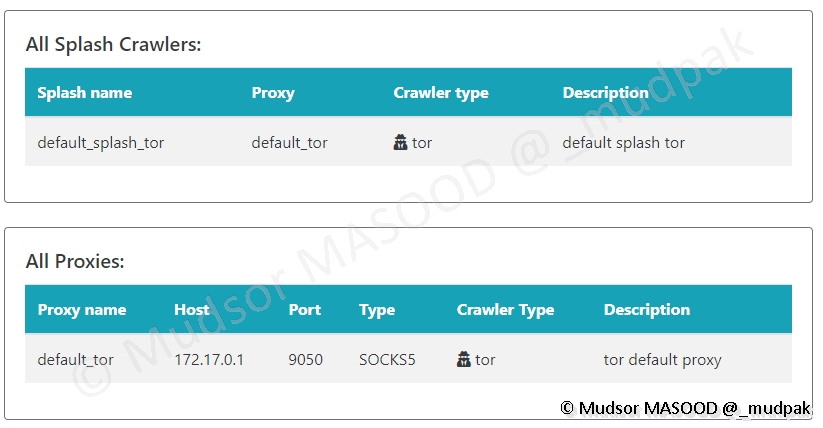
Il est également possible de lancer un test manuel et voici un exemple de résultat lorsque le crawler TOR est fonctionnel :

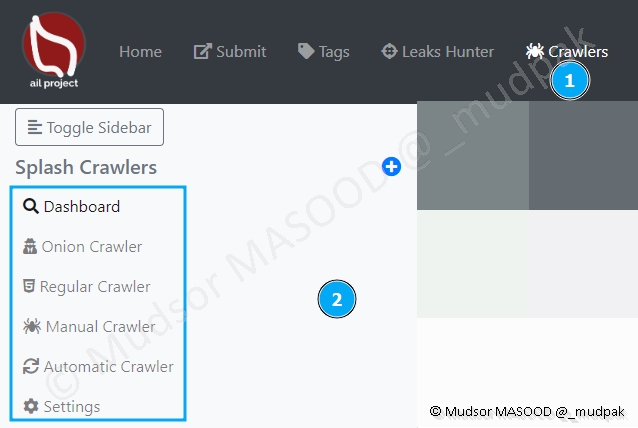
8.6.2 Splash Crawlers
Voici les différents éléments de cette partie :
- Dashboard : tableau de bord affichant les types de crawlers, l’état des sites (up, down, crawled, queue…)
- Onion Crawler
- Regular Crawler
- Manual Crawler
- Automatic Crawler
- Settings
8.6.2.1 Manual Crawler
Passons directement au Crawler manuel pour montrer l’exemple sur un site en .onion (réseau TOR).
Voici les différentes opérations à renseigner :
- 1 : l’adresse en « .onion » du site
- 2 : le type de crawler, ici tor
- 3 : type de crawling, ici manuel
- 4 : si nous souhaitons prendre une capture d’écran des pages du site
- 5 : (le nombre de pages ?)
- 6 : pour lancer le crawling

Sur le dashboard nous pouvons observer que l’opération est en cours :
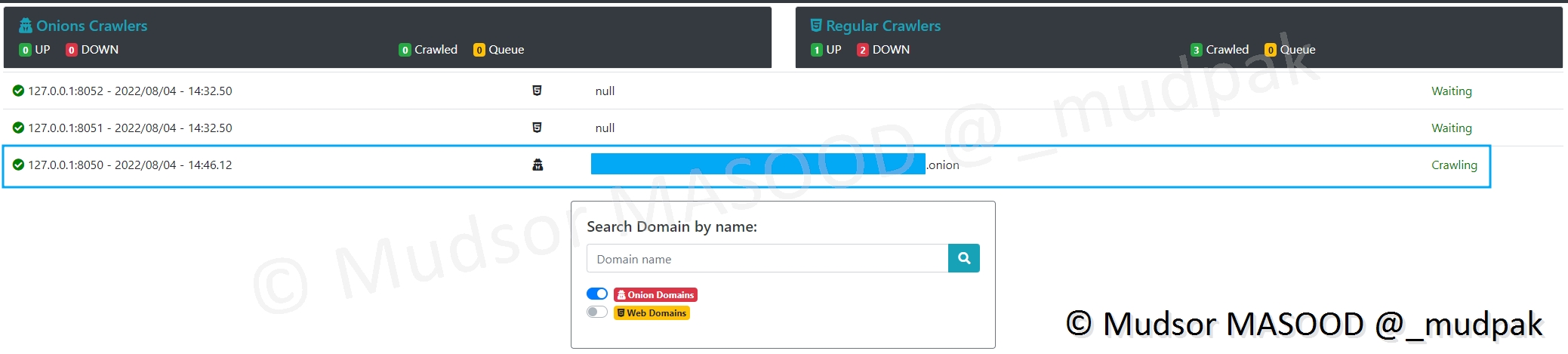
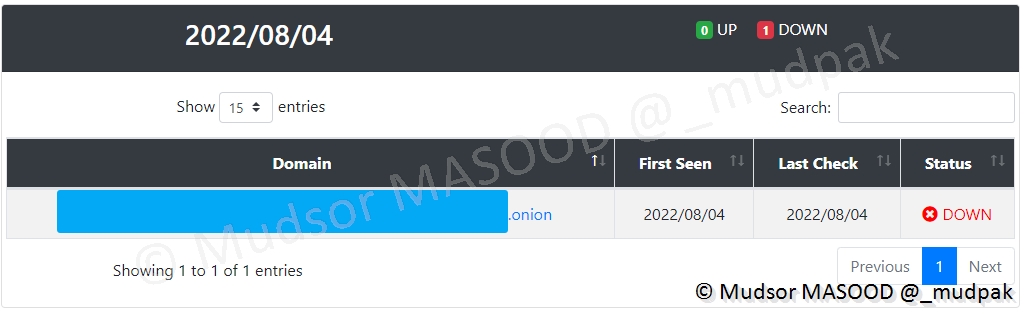
Il en résulte que le site en question n’est plus joignable :
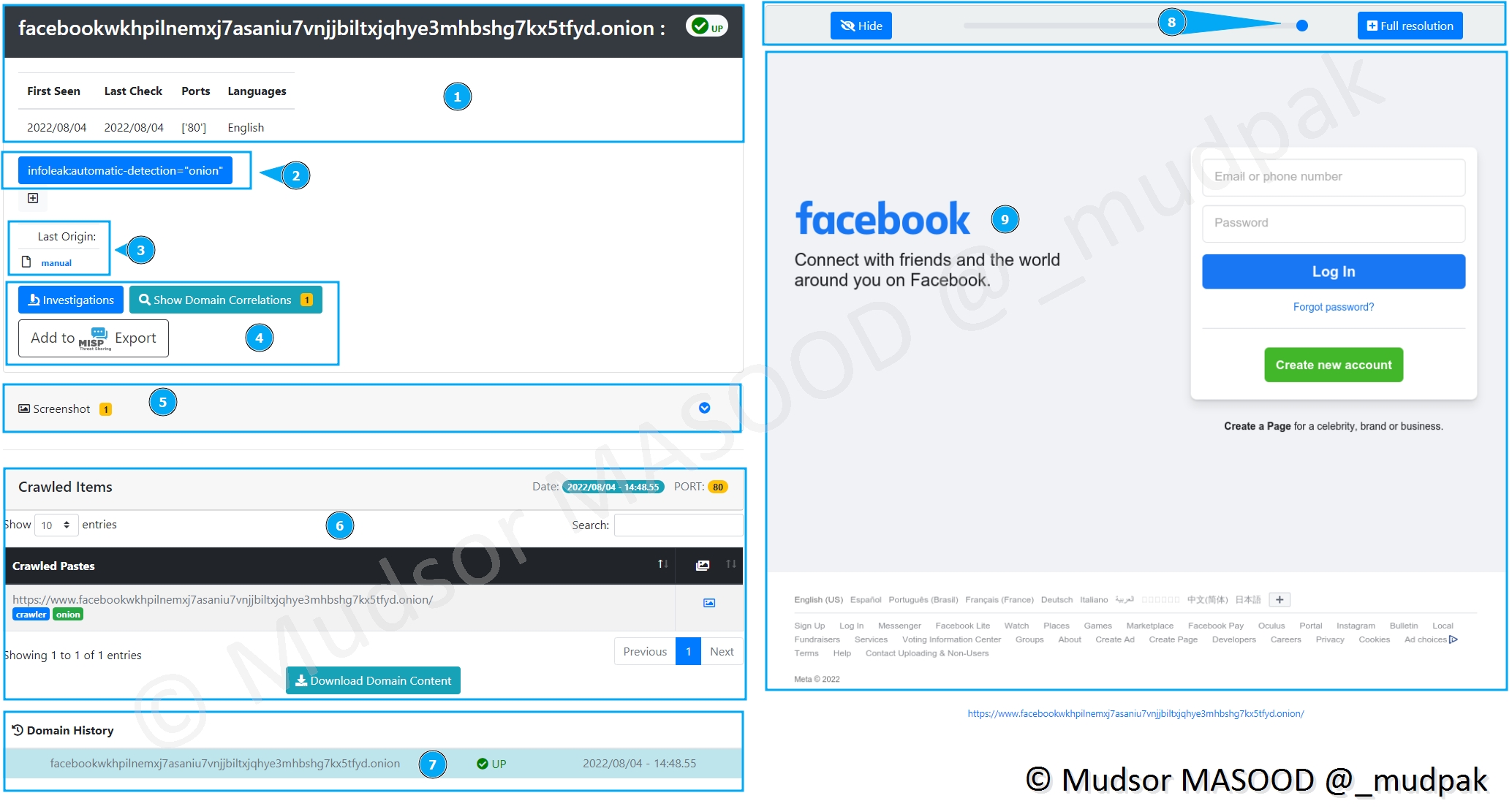
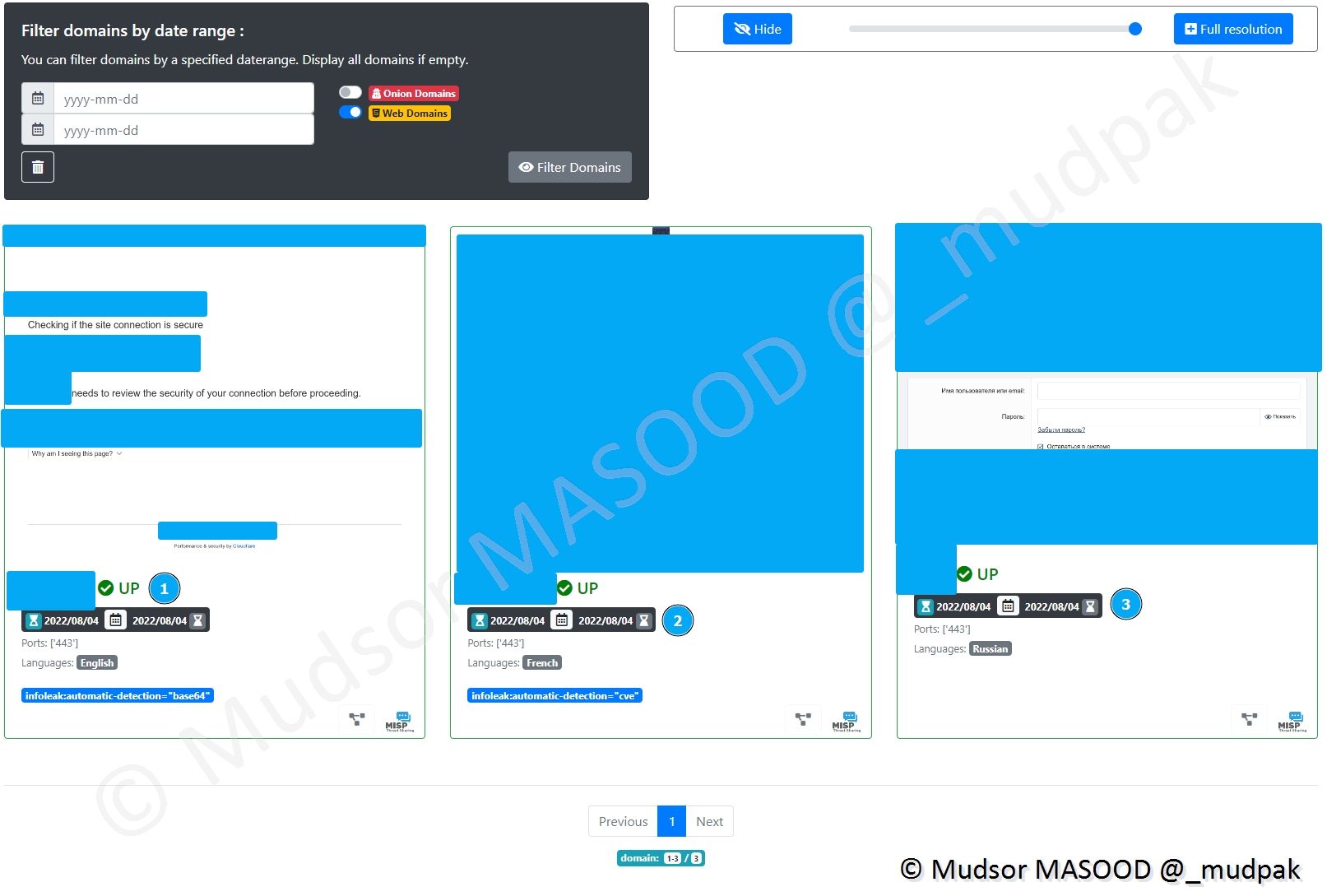
Ici nous avons effectué le même process mais cette fois pour l’adresse TOR de Facebook.
Voici les différentes informations que nous avons :
- 1 : les dates de première vérification et la dernière fois où le site à été crawlé, le port ainsi que la langue
- 2 : tag ajouté automatiquement par AIL
- 3 : le type de crawling qui a été appliqué
- 4 : les opérations de corrélation et investigations ou interconnexion dans le MISP
- 5 : un screenshot a été pris
- 6 : pages crawlés avec un screenshot associé à droite
- 7 : s’il y a eu des vérifications dans le passé un historique permet de faire le suivi
- 8 : via un curseur il est possible de flouter l’aperçu des captures ou simplement ajuster le niveau selon le contexte
- 9 : capture de la page qui a été crawlée
8.6.2.2 Automatic
Très semblable au crawler manuel, le crawler automatique comme son nom l’indique permet d’effectuer cette opération à des intervalles régulières.
Nous pouvons observer que le temps doit être exprimé en secondes entre chaque opération :

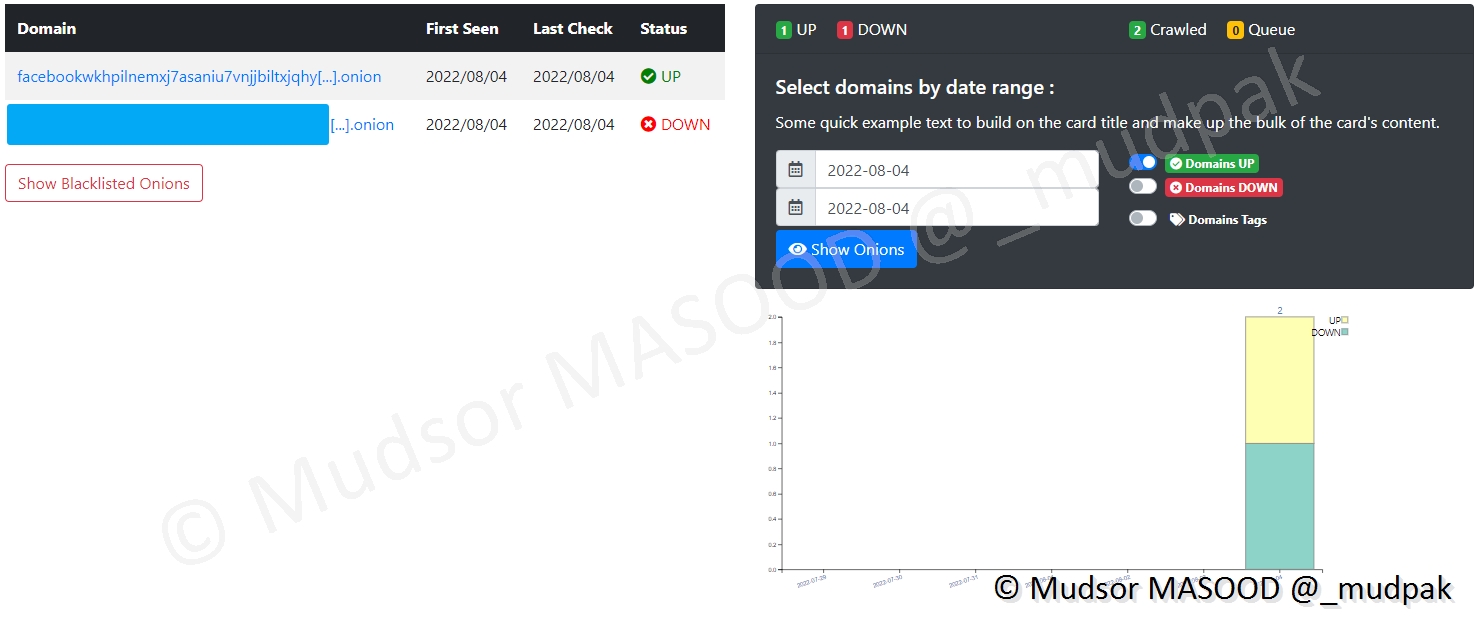
8.6.2.3 Onion Crawler
Cette partie est réservée aux sites en .onion :
8.6.2.4 Regular Crawler
Cette partie est réservée aux sites "classiques" (surface et deep web) :
8.6.3 Domain Explorer
8.6.3.1 Onion Domain
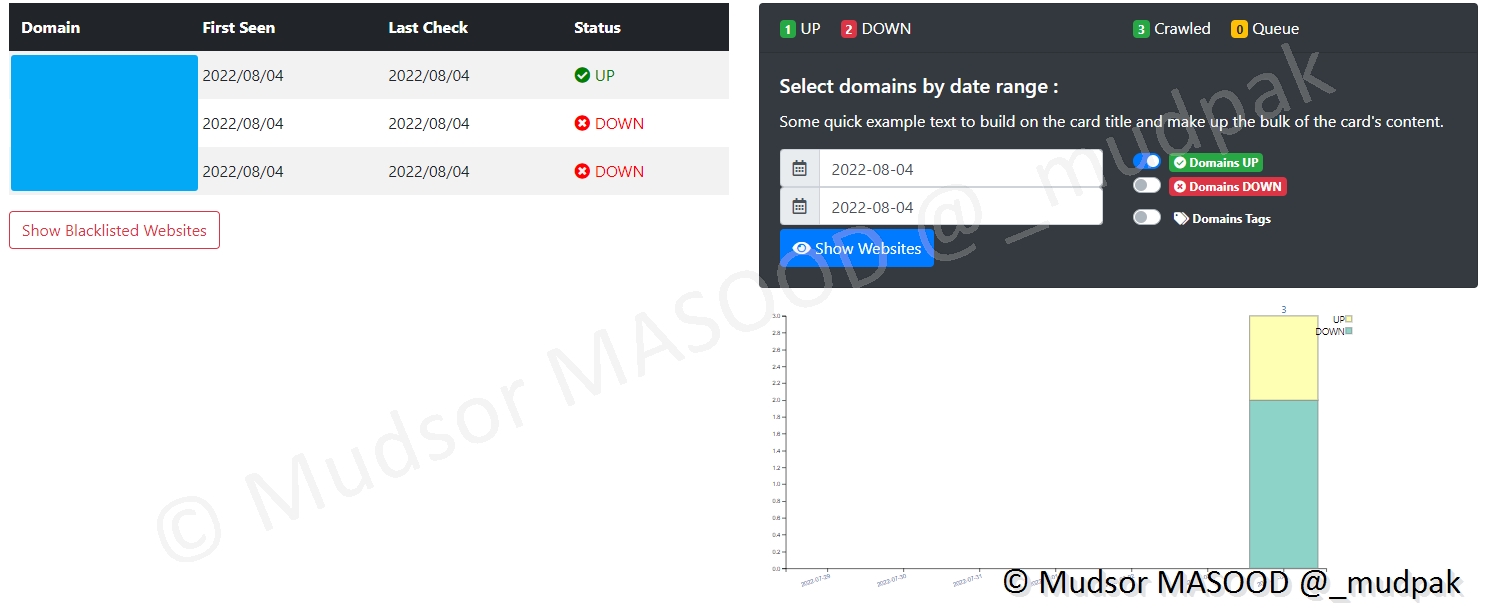
Voici un exemple de résultat que nous pouvons obtenir pour un site du réseau TOR, il est possible d'effectuer une capture d'écran en plus ou moins bonne qualité selon notre préférence.
Cela peut paraitre illogique de réduire la qualité ou flouter le contenu d'une capture mais selon le type de site qui est surveillé il est nécessaire d'appliquer ce type de filtre.
8.6.3.2 Web Domain
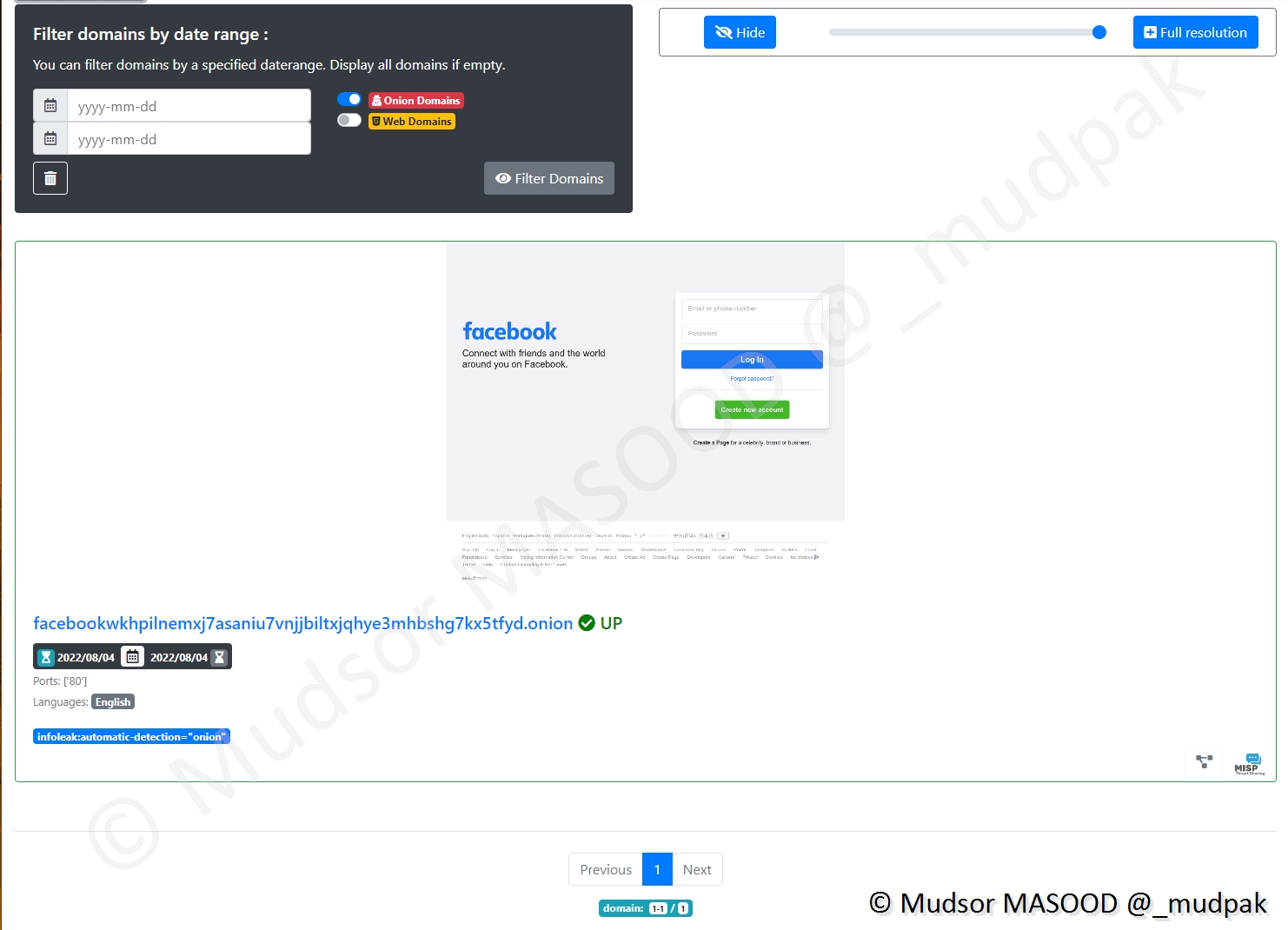
Similaire au crawler précédent, ici nous pouvons observer trois cas :
- 1 : site avec protection Cloudflare et ayant détecté que c’est un crawler qui visite le site donc une vérification est demandée
- 2 : site crawlé sans difficultés
- 3 : site où il faut se connecter pour consulter le contenu
Pour éviter les problèmes de cas 1 et 3 l’utilisation de la fonctionnalité « Cookiejar » sera très utile.
8.6.4 Cookiejar
Cette section permet de préenregistrer les cookies pour que les crawlers puissent les utiliser sur les sites.
Cliquer sur
- Crawlers
- Cookiejar
8.6.4.1 All Cookiejar
A cet endroit vont s’afficher les cookies :
- Your Cookiejar : les cookies que vous aurez préféfinis
- Global Cookijar : les cookies de tous les utilisateurs
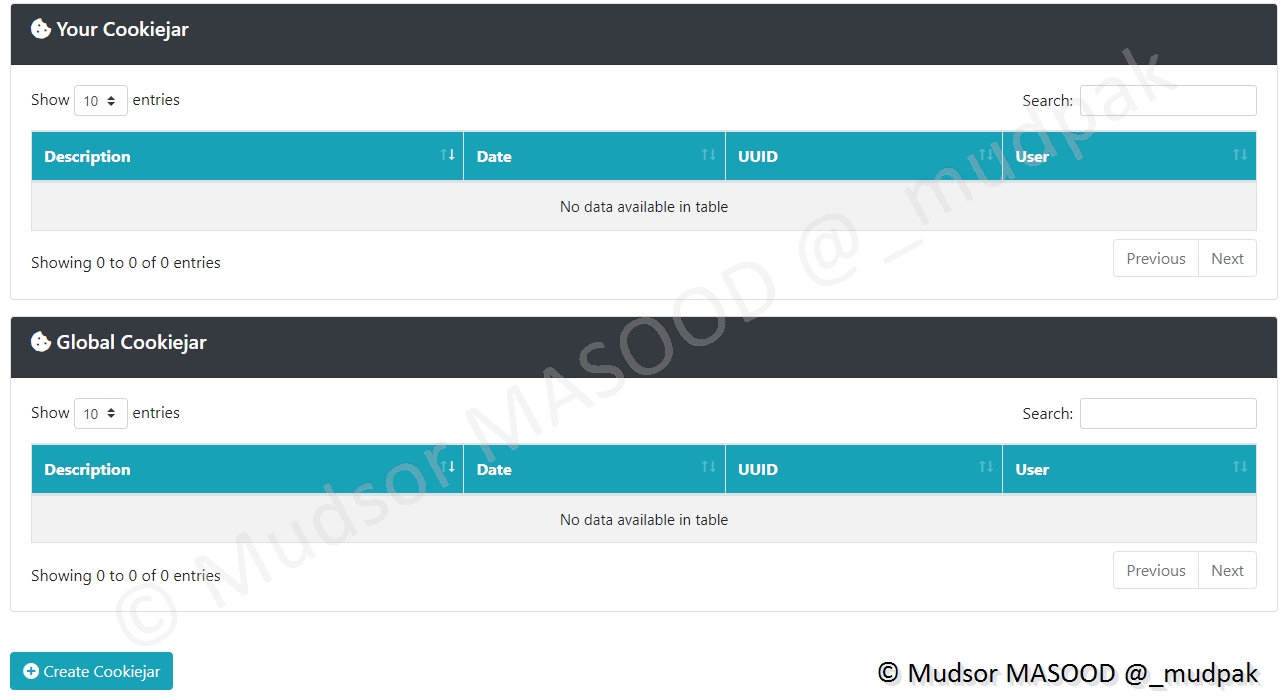
8.6.4.2 Add Cookiejar
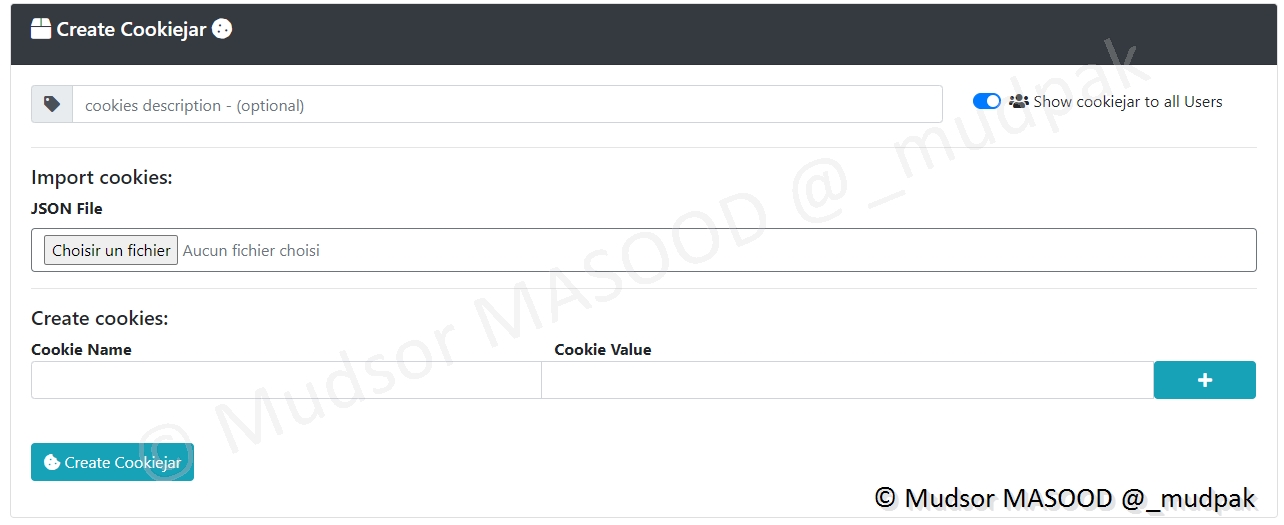
Pour ajouter un Cookie, il faut renseigner les éléments suivants :
- Show cookiejar to all Users : si vous souhaitez partager le cookie avec les autres comptes
- Import cookies JSON File : si vous souhaitez importer les cookies depuis un fichier JSON
- Cookie Name : le nom du cookie
- Cookie Value : la valeur du cookie
Cliquer sur
- Create Cookiejar
8.7 rawSkeleton page
C’est une mode vide qui est consultable en cliquant sur
- Statistics
- rawSkeleton page
8.8 hidden Services
Cette page redirige vers la section « Crawlers ».
8.9 Server Management
Cette section permet comme son nom l’indique de gérer le serveur.

8.9.1 Diagnostic
Pour avoir des informations générales, cliquer sur
- Server Management
- Diagnostic
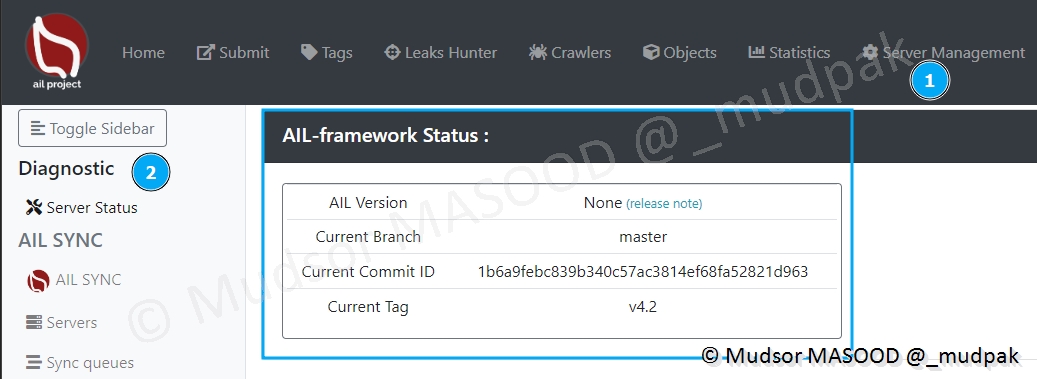
Les informations suivantes sont affichées :
- AIL Version
- Current Branche : la branche github qui a été utilisée
- Current Commit ID : l’identifiant du commit
- Current Tag : le tag de la version de la plateforme
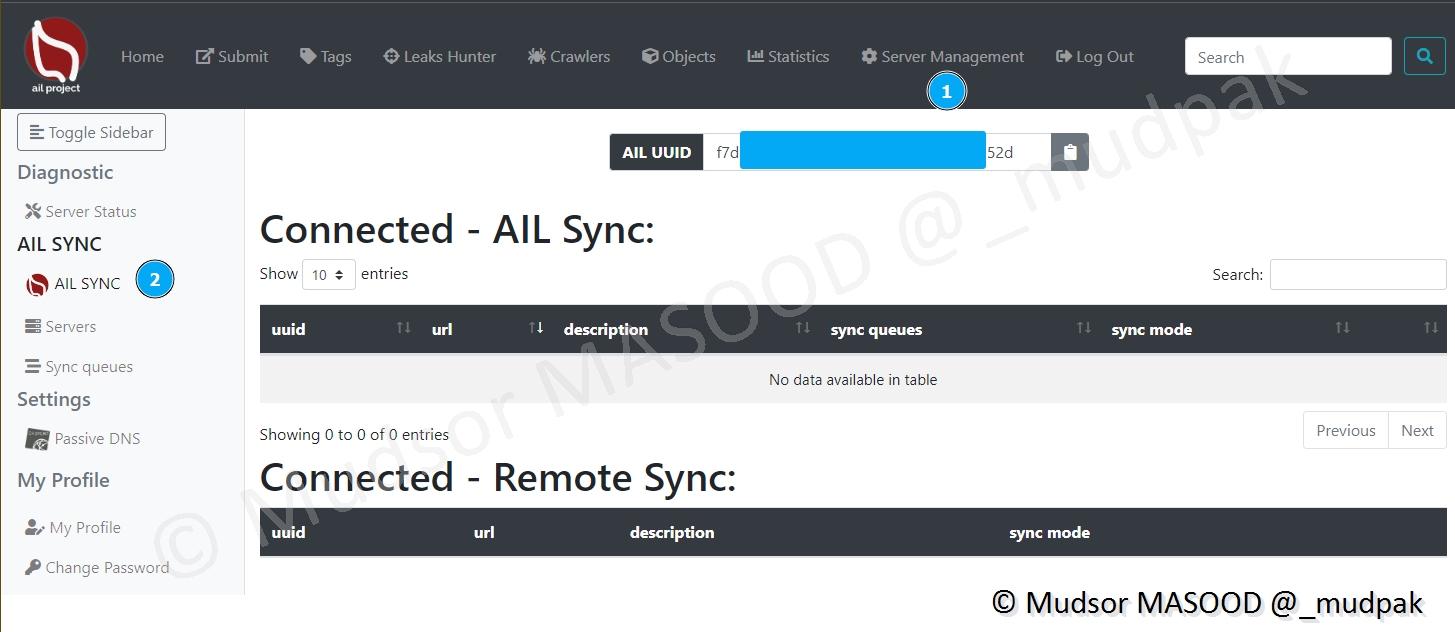
8.9.2 AIL Sync
Il est possible d’interconnecter des plateformes AIL, de la même manière que le MISP.
Cliquer sur
- Server Management
- AIL SYNC
Nous pouvons voir que notre plateforme dispose d’un UUID, cet identifiant permet de l’identifier de manière unique.
8.9.3 Settings
Pour configurer la partie DNS Passive, cliquer sur
- Server Management
- Passive DNS
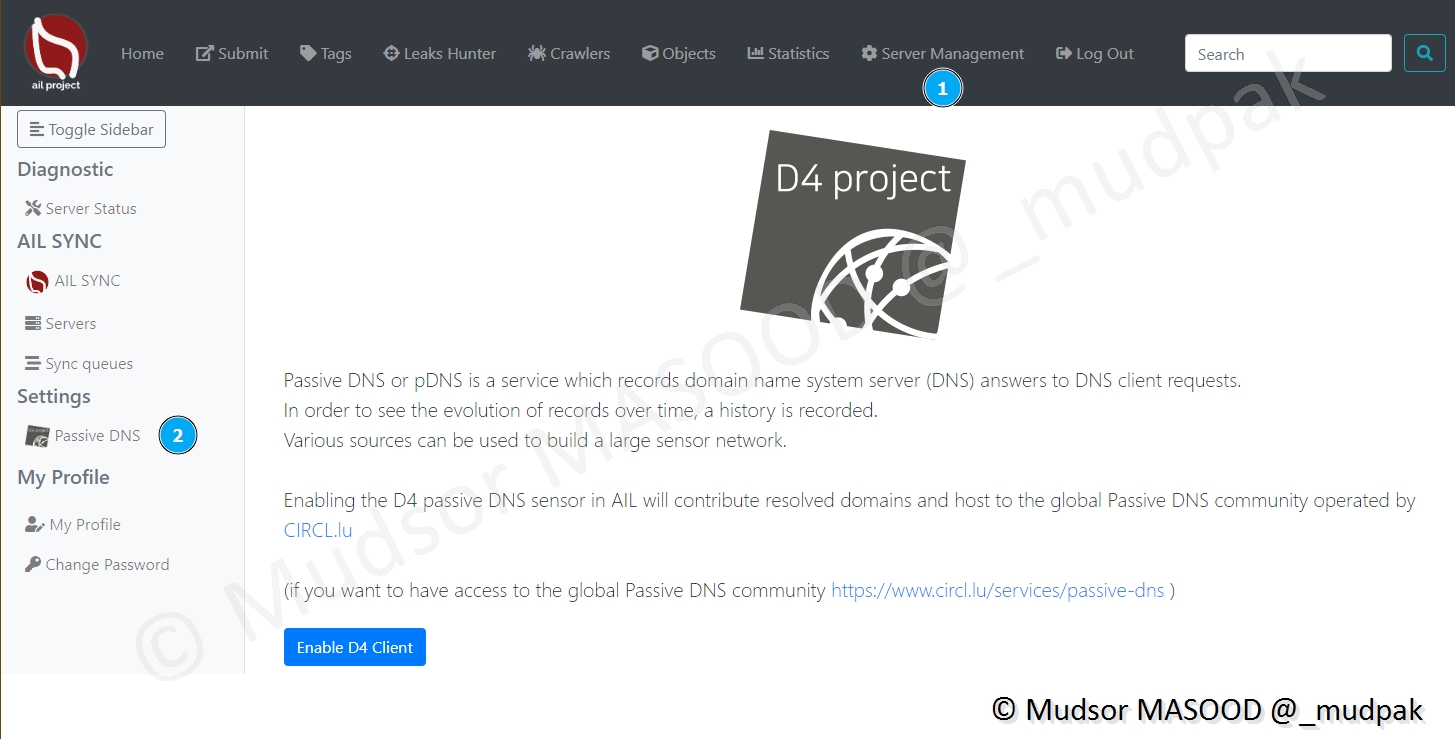
8.9.4 My Profile
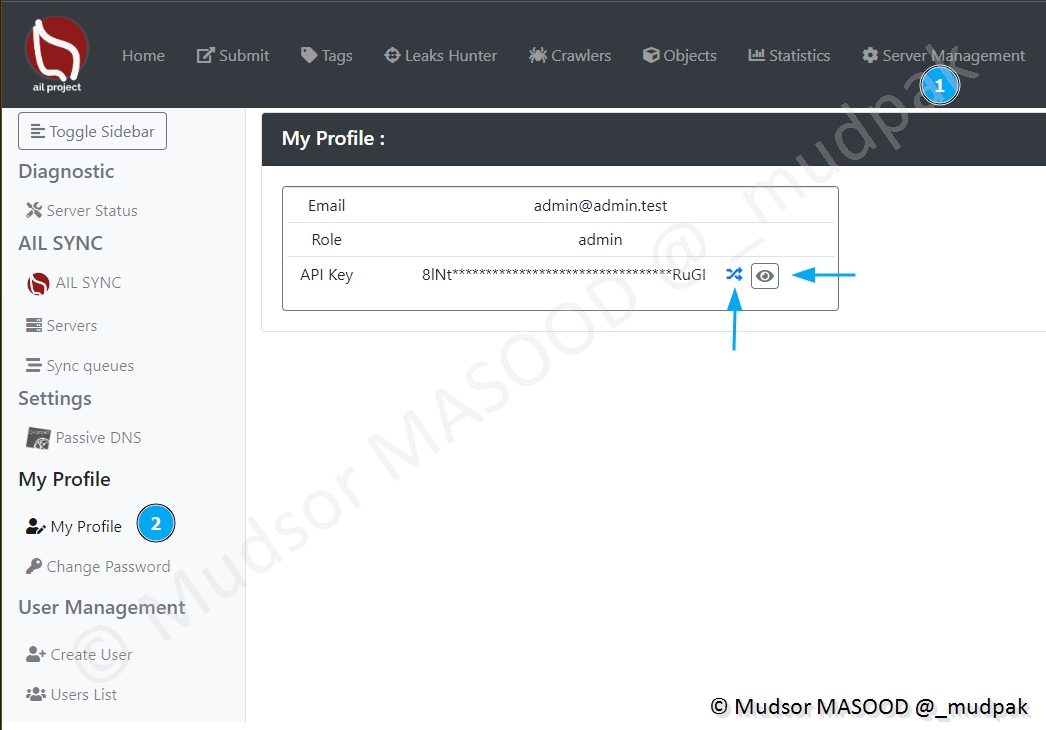
Pour gérer votre compte, cliquer sur
- Server Management
- My Profile
Nous pouvons voir les éléments suivants :
- Email : l’adresse email utilisée par le compte admin par défaut
- Rôle : le rôle du compte
- API Key : la clé API
- Il est possible de générer une nouvelle clé en cliquant sur les doubles flèches
- Pour afficher la clé cliquer sur le symbole représentant un oeil
8.9.5 User Management
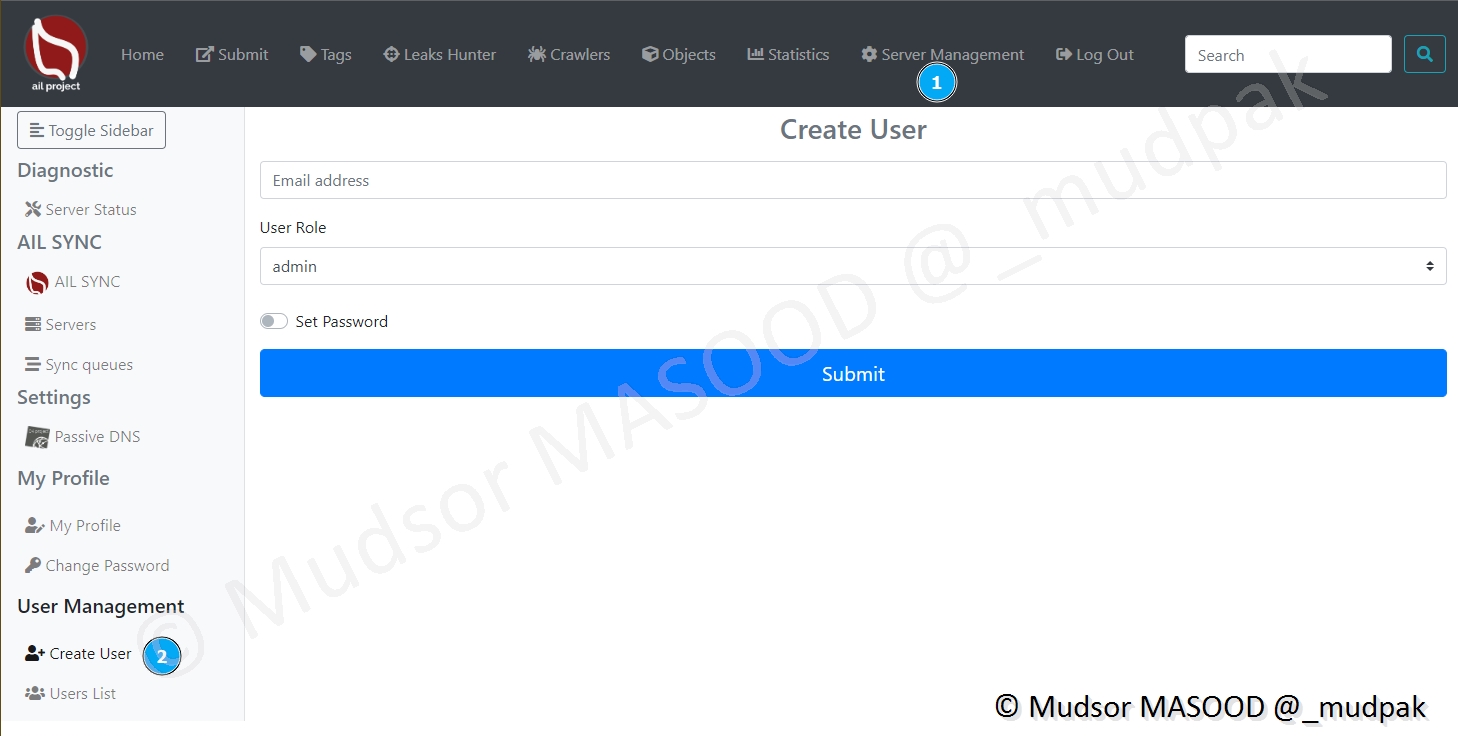
Pour des raisons de sécurité et d’utilisation il peut être nécessaire de créer des comptes utilisateur, cliquer sur
- Server Management
- Create User
Remplir les champs suivants :
- Email address : adress email du compte utilisateur
- User Rôle : le rôle à attribuer au compte
Parmi les différents rôles que nous pouvons attribuer aux comptes voici la liste complète :

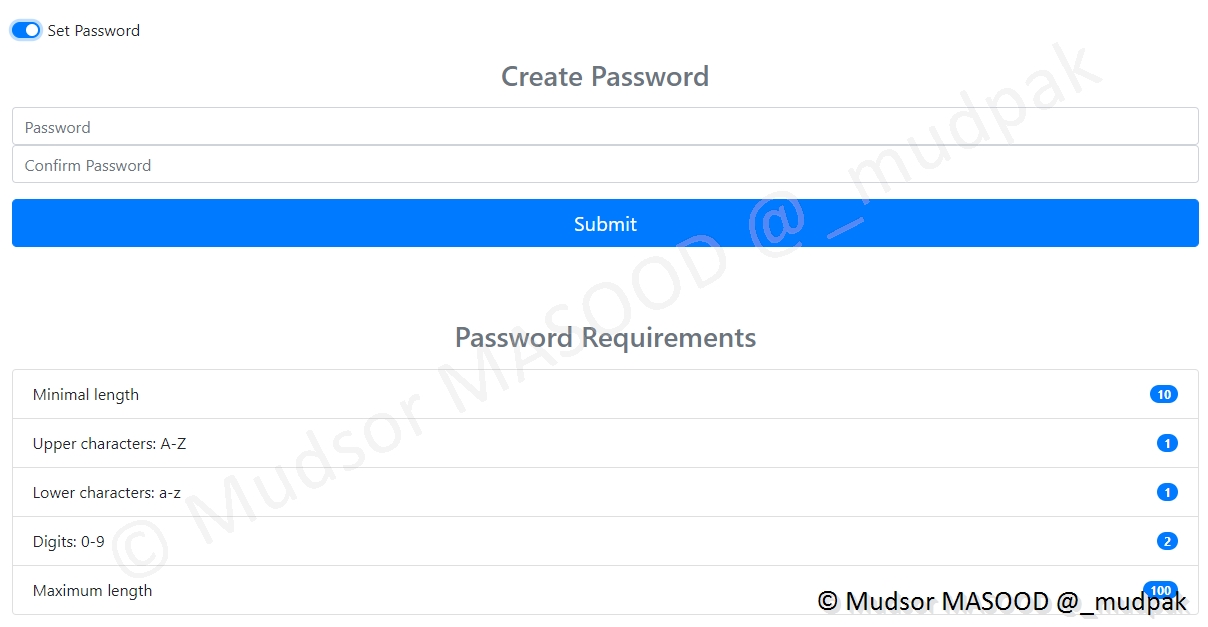
Si nous cochons la case « Set Password » il est possible de prédéfinir un mot de passe mais il doit respecter les exigences de sécurité :
Si nous ne prédéfinissons pas de mot de passe, un mot de passe aléatoire sera attribué au compte, pour l’afficher il faudra cliquer sur
- Hide

Voici un exemple après la création d’un compte de type « Analyst », nous pouvons constater qu’une clé API est également crée de manière automatique :

8.10 Log Out
Pour se déconnecter de la plateforme il faut cliquer sur
- Log Out

9. Soumission de données
A cet instant il y a trois manières pour envoyer des données dans l’instance :
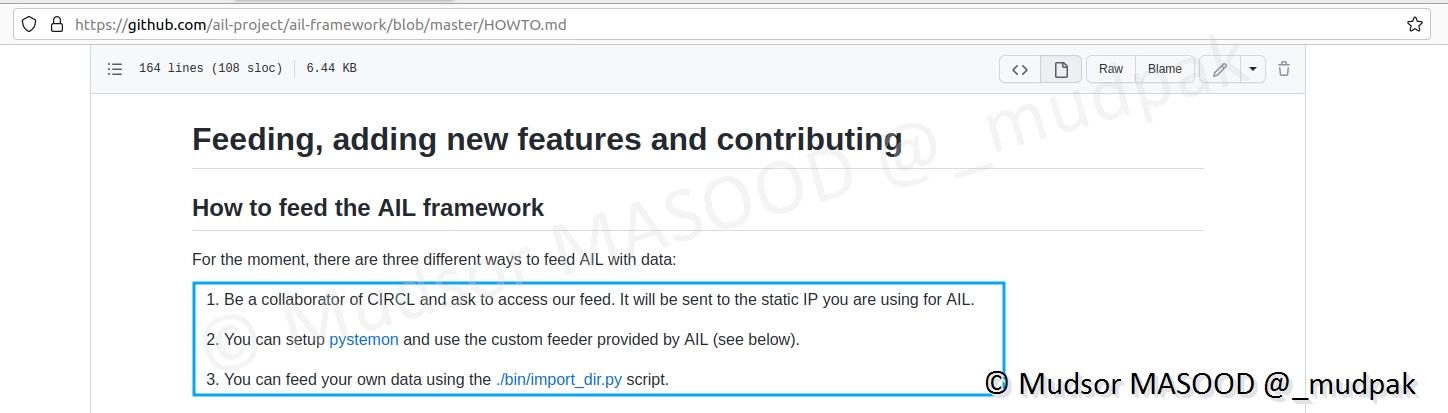
Remarque
Il existe différents types de feeder (Twitter, Telegram, PDF. . . ) mais nous n’allons en voir que certains.
9.1 Via les Feeds CIRCL
Nous n’allons pas appliquer cette méthode, à la place nous allons utiliser les méthodes suivantes :
- Via Pystemon
- Via soumission manuelle (pas via le script « ./bin/import_dir.py ») mais via l’interface web
9.2 Via Pystemon
Bien que le but principal de la plateforme soit d’analyser des données soumises manuellement, il est possible de les récolter via des espaces publics, nous allons voir comment installer, configurer et réceptionner des données depuis des sites.
9.2.1 Mise en place
Si vous avez précédemment lancé la plateforme, nous allons à nouveau l’arrêter le temps de mettre en place le feeder pystemon.
9.2.1.1 GitHub
Le script est disponible à l’adresse suivante :
1 | |
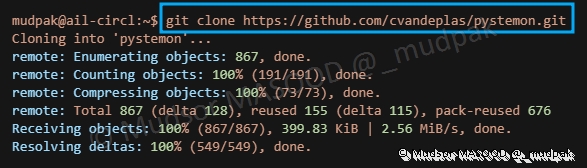
9.2.1.2 Récupération du script
Saisir la commande suivante :
1 | |
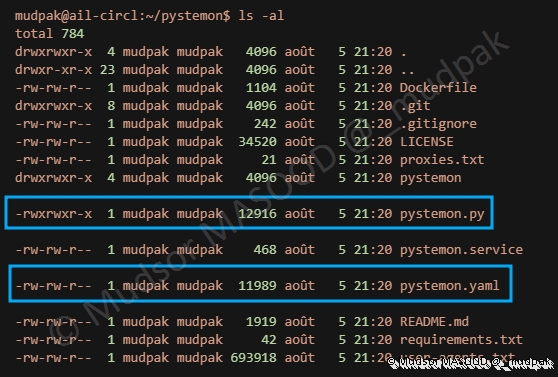
Se rendre dans le dossier crée lors de la récupération du script :

Plusieurs éléments sont présents dans le dossier, nous allons nous intéresser à deux d’entre deux :
- pystemon.py : le script pour lancer le programme
- pystemon.yaml : le fichier de configuration que nous allons modifier
9.2.1.3 Modification du fichier de configuration « pystemon.yaml »
Saisir la commande suivante pour modifier le fichier :

Si vous souhaitez garder une copie locale des leaks qui ont générées une alerte, ou plus globalement sauvegarder les données qui ont été trouvées il faut passer les directives suivantes en « yes » :
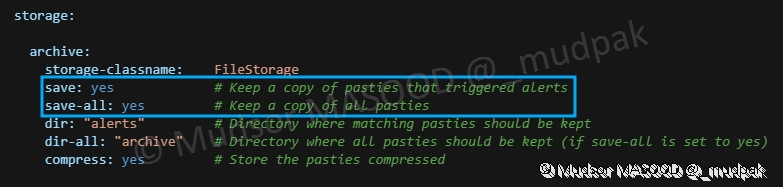
Il est également possible de modifier le nombre de threads alloués pour chaque site, dans notre cas nous avons alloué 2 :
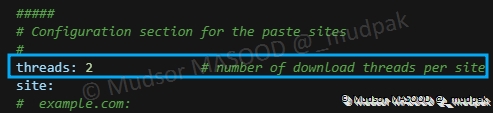
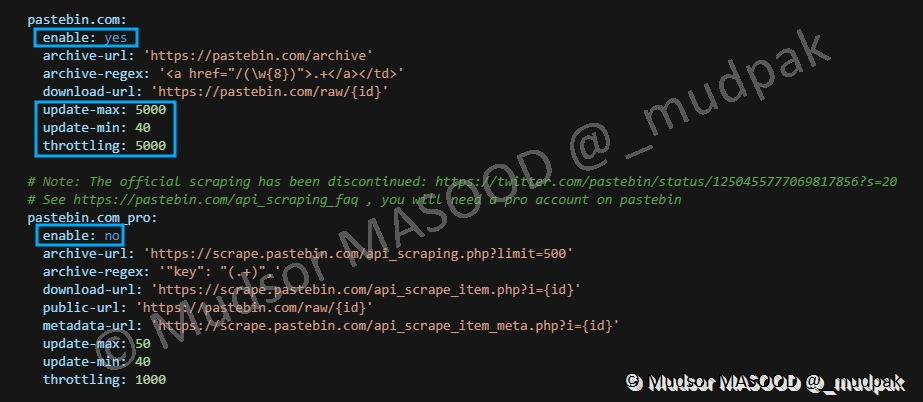
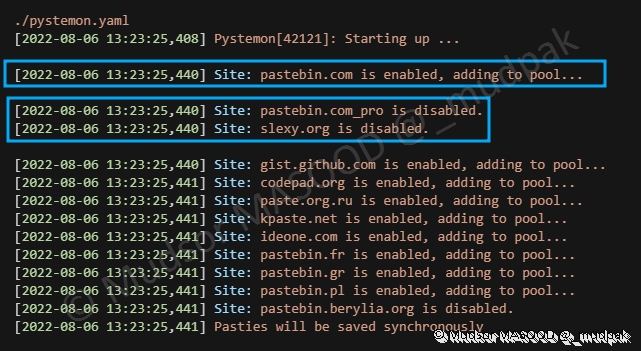
Un certain nombre de sites servent de source pour les données, il est possible d’activer la réception des données en modifiant la directive « enable » à « yes » comme c’est le cas pour « pastebin[.]com »
Quelques paramètres très importants sont à définir pour ne pas surcharger les sites de requêtes :
- update-max : temps maximum en secondes avant de vérifier s’il y a de nouvelles données à télécharger
- update-min : temps minimal en seconds avant de vérifier s’il y a des données à télécharger, une durée aléatoire entre le paramètre « update-max » et « update-min » sera en réalité utilisée pour télécharger les données
- throttling : temps en millisecondes qu’il faut attendre avant de télécharger de nouvelles données
Tous les sites sont par défaut désactivés, comme c’est le cas pour « pastebin[.]com_pro
Remarque
Je vous conseille de mettre des périodes assez étendues pour ne pas trop solliciter les différents sites au risque de vous faire blacklister et donc ne plus avoir accès aux données.
D’autres sites sont listés mais ne sont plus fonctionnels :
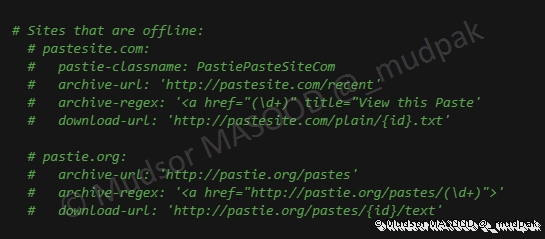
Une TODO list est également renseignée, à voir donc avec l’évolution de l’outil pour connaitre leur intégration :
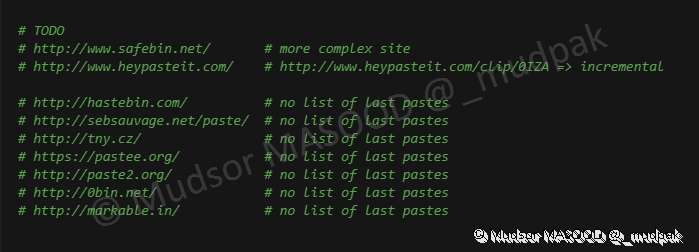
Une dernière section dédiée aux proxies et aux user-agents est présente, les fichiers cités se trouvent dans le répertoire de « pystemon ».
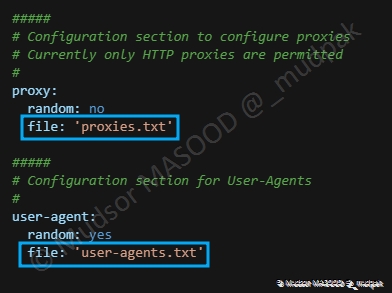
Voici le contenu du fichier « proxies.txt » :
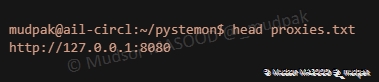
Voici un extrait du fichier « user-agents.txt » :
9.2.1.4 Activation du virtualenv
Se rendre dans le dossier « ail-framework » et saisir la commande suivante :
1 | |

9.2.1.5 Installation des dépendances
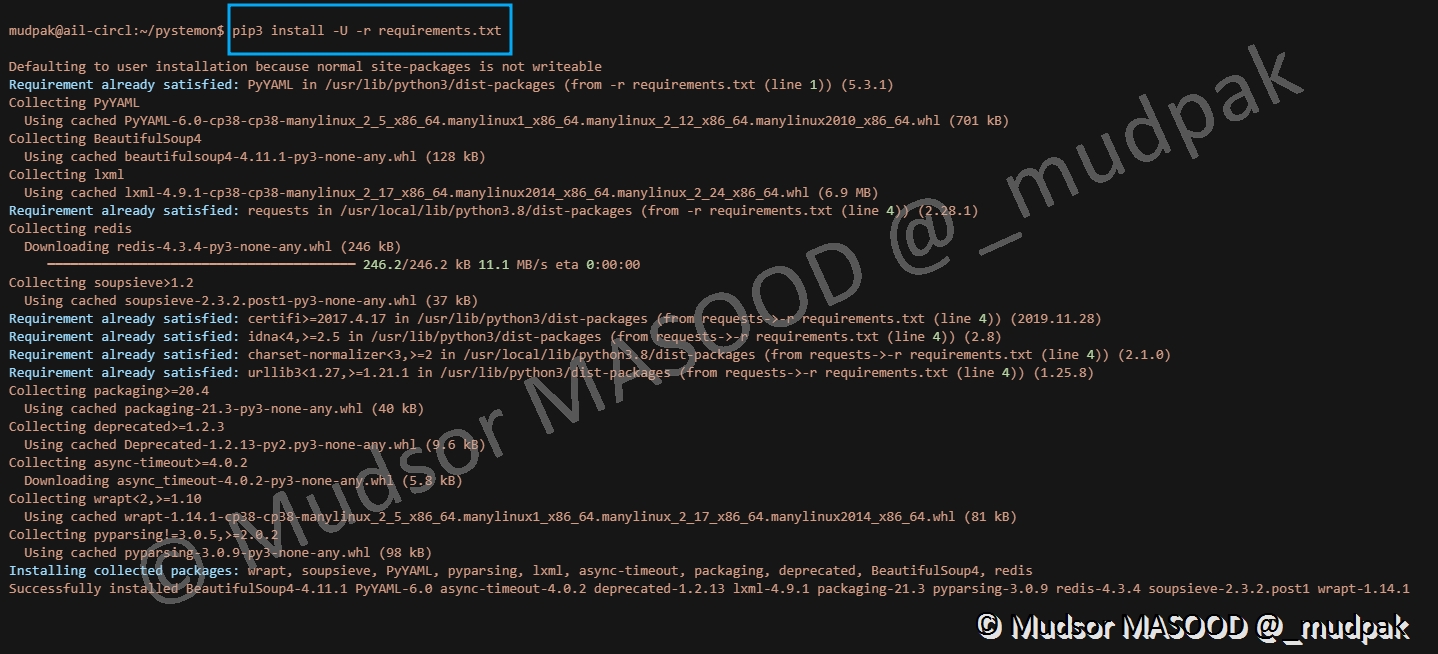
Revenir à nouveau dans le dossier de pystemon et saisir la commande suivante :
1 | |
Certains paquets sont déjà présentes et les paquets manquants s’installent :
9.2.1.6 Modification du fichier de configuration « core.cfg »
Revenir dans le dossier de AIL Framework, et modifier la directive « pystemonpath » suivante se trouvant dans le fichier de configuration suivant :
1 | |
Ici il faut modifier le chemin par celui du répertoire où se trouve pystemon, dans notre cas il se trouve dans le répertoire utilisateur :

9.2.1.7 Lancement de AIL
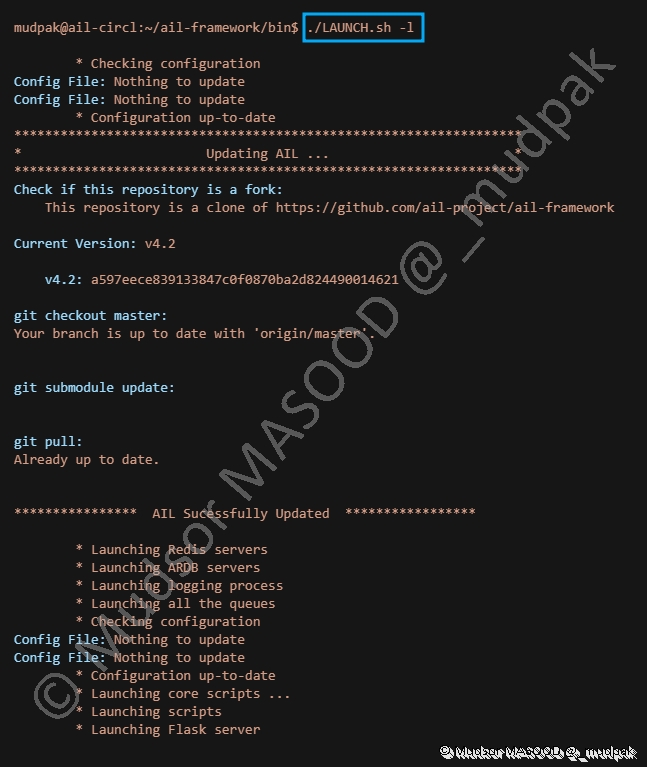
Maintenant que les installations et changements sont effectués nous pouvons lancer à nouveau notre plateforme, pour cela saisir la commande ci-dessous dans le dossier « ail-framework/bin/ » :
1 | |
9.2.1.8 Lancement du feeder pystemon
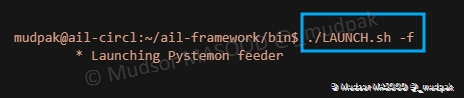
Pour démarrer le feeder pystemon, saisir la commande suivante :
1 | |
Nous pouvons observer que le feeder se lance.
9.2.1.9 Vérification du lancement
Pour être certain que le feeder ait bien démarré, nous pouvons retourner dans le dossier de pystemon et saisir la commande suivante pour afficher les statistiques de fonctionnement :
1 | |

Nous pouvons observer que certains sites sont activés et d’autres non comme vu précédemment dans le fichier « pystemon.yaml » :
Ici nous avons un message qui nous informe sur la prochaine vérification qui sera faite sur le site :

Une fois que le feeder a visité les sites que nous avons activés, il nous affiche le nombre de « pastes » qu’il va télécharger :
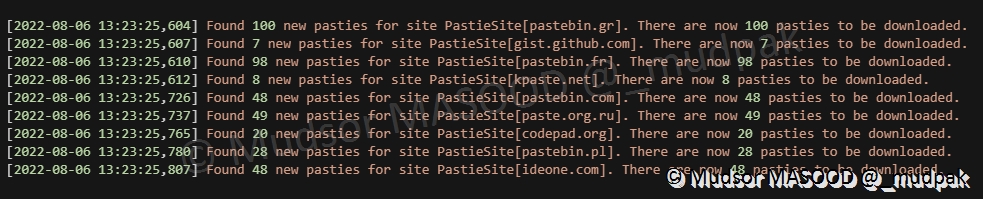
Maintenant que nous avons installé, configuré et vérifié que le feeder fonctionne bien, nous allons passer à l’interface web pour avoir un visuel sur ces données et les différents traitements possibles.
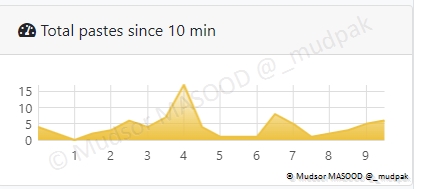
9.2.2 Home
Dans la section « Home » nous avons différents graphes, celui-ci représente le nombre de téléchargements sur les 10 dernières minutes :
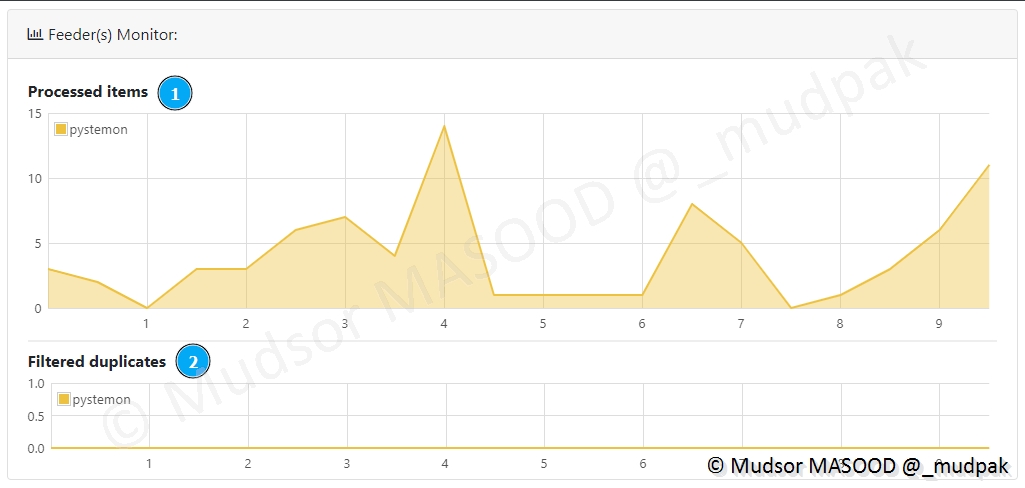
Le Feeder Monitor nous informe sur les éléments suivants :
- 1) que nous utilisons un feeder pystemon et le nombre d’éléments qui ont été traités
- 2) s’il y a eu des duplicatas de données
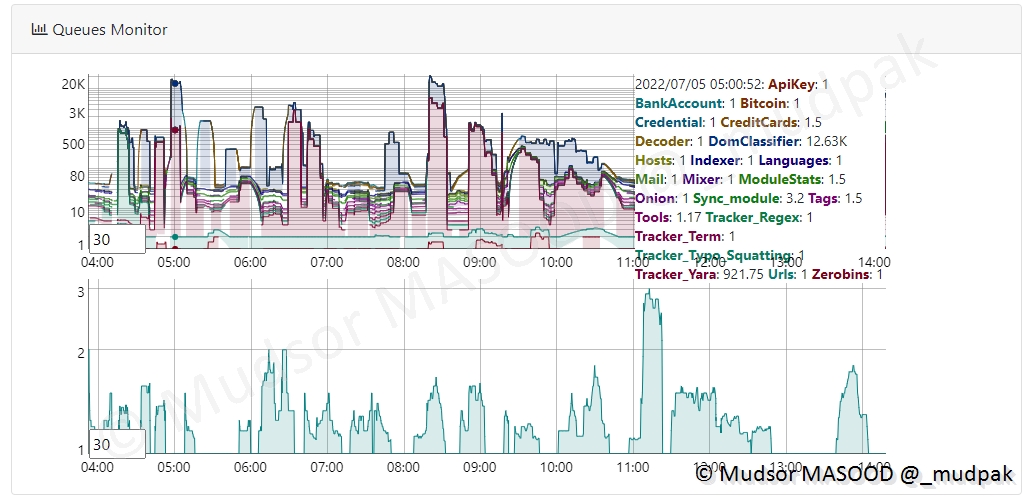
Le graphe « Queues Minitor » est peut afficher beaucoup de données comme c’est le cas ici, parmi les pastes récupérés, se trouvent des éléments de différentes natures :
- Clé API
- Comptes bancaires
- Cartes bancaires
- Adresses Email
- Liens TOR
- Règle YARA
- . . .
Plus bas sur la même page s’affichent en temps réel les « Logs » et nous pouvons voir les différentes informations :
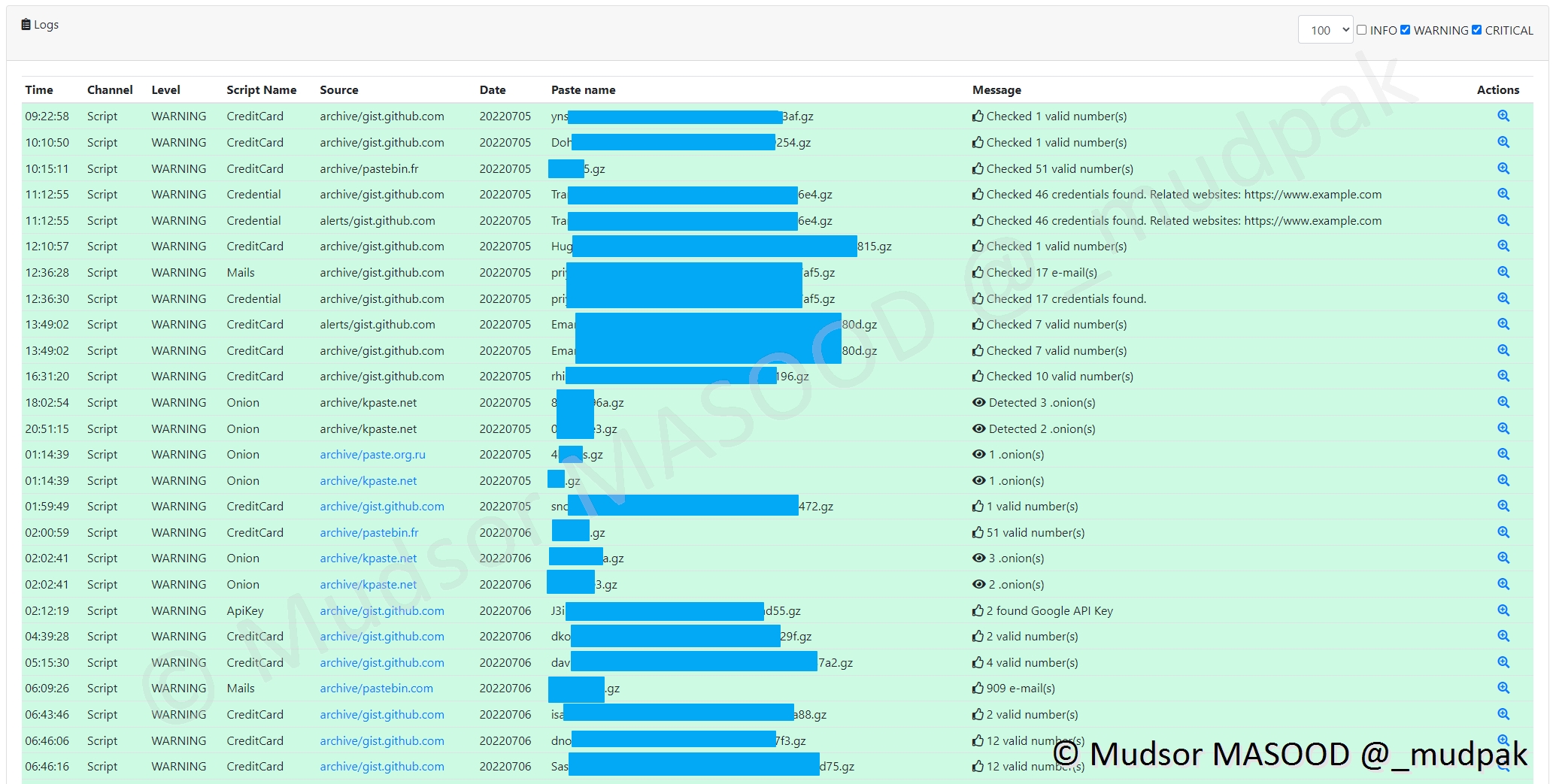
Si vous souhaitez voir plus d’éléments vous pouvez modifier le nombre d’éléments à afficher et cocher la case « INFO » :
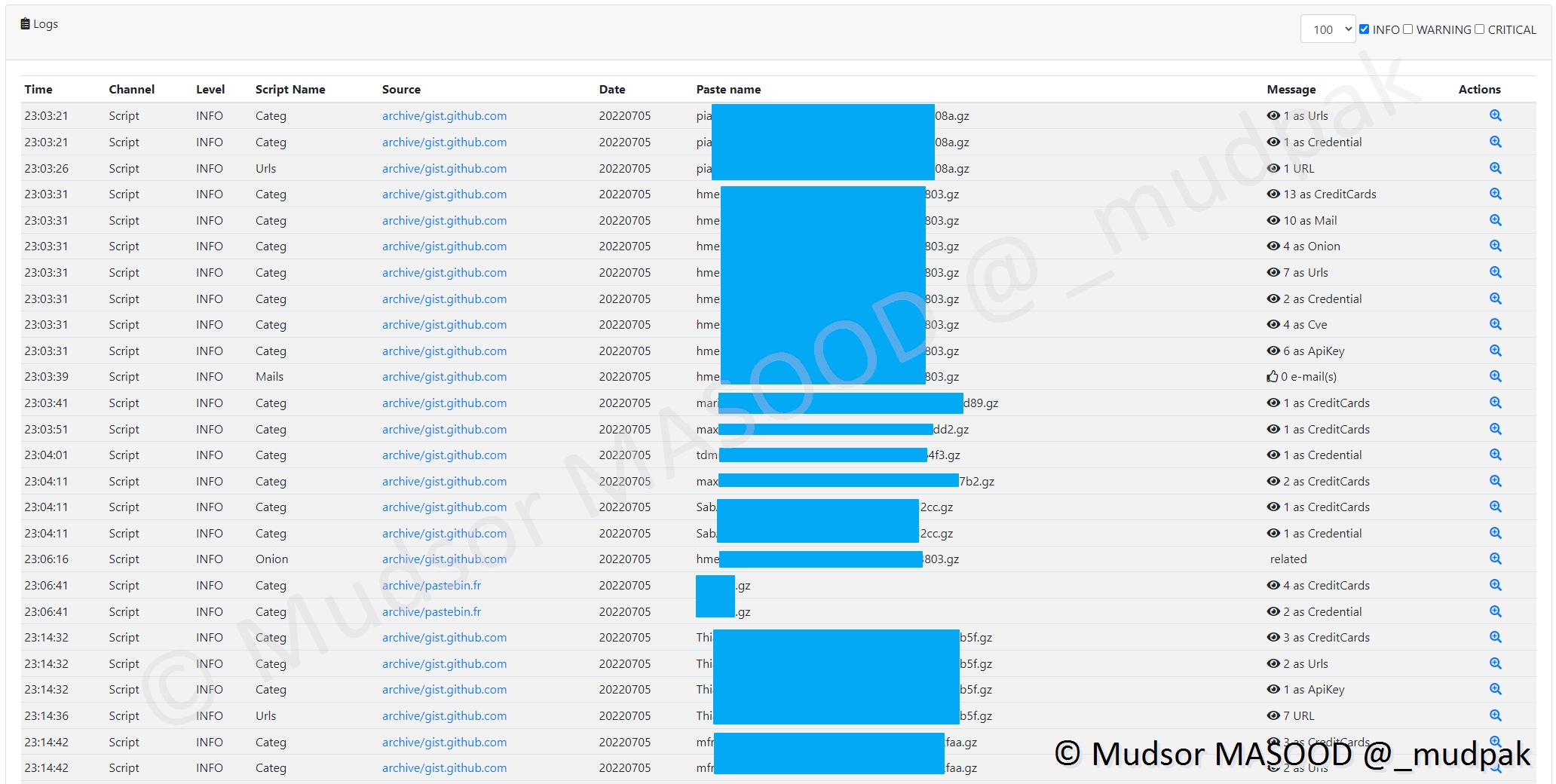
En parallèle de la récupération des données, nous avons un détail sur les types d’éléments listés dans un tableau dans la section gauche de la fenêtre :
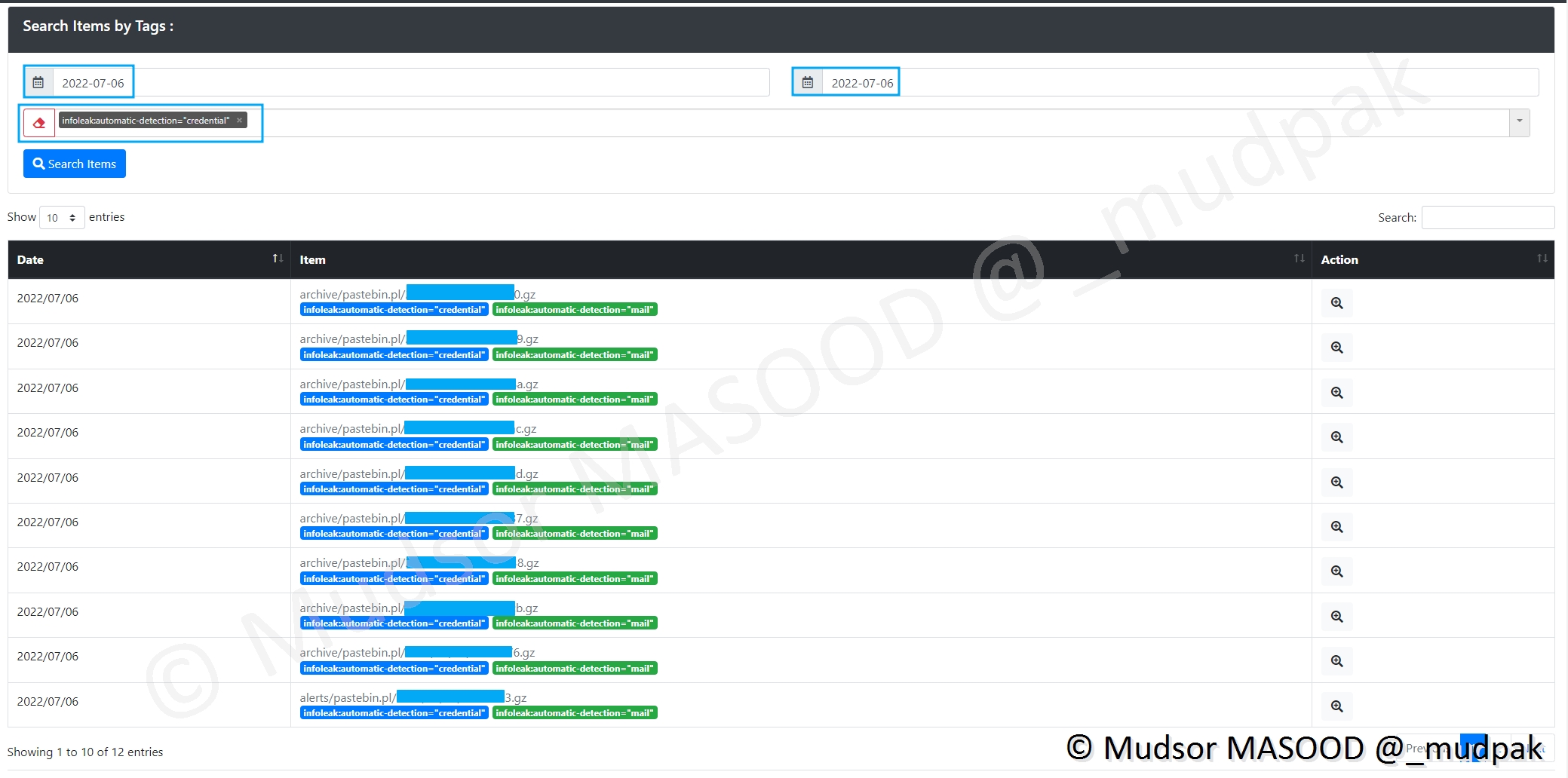
9.2.3 Tags
Les données récupérées se voient attribuer un ou plusieurs tags.
9.2.3.1 Credentials
Ci-dessous nous pouvons observer des données qui contiennent à la fois des identifiants et à la fois des adresses emails :
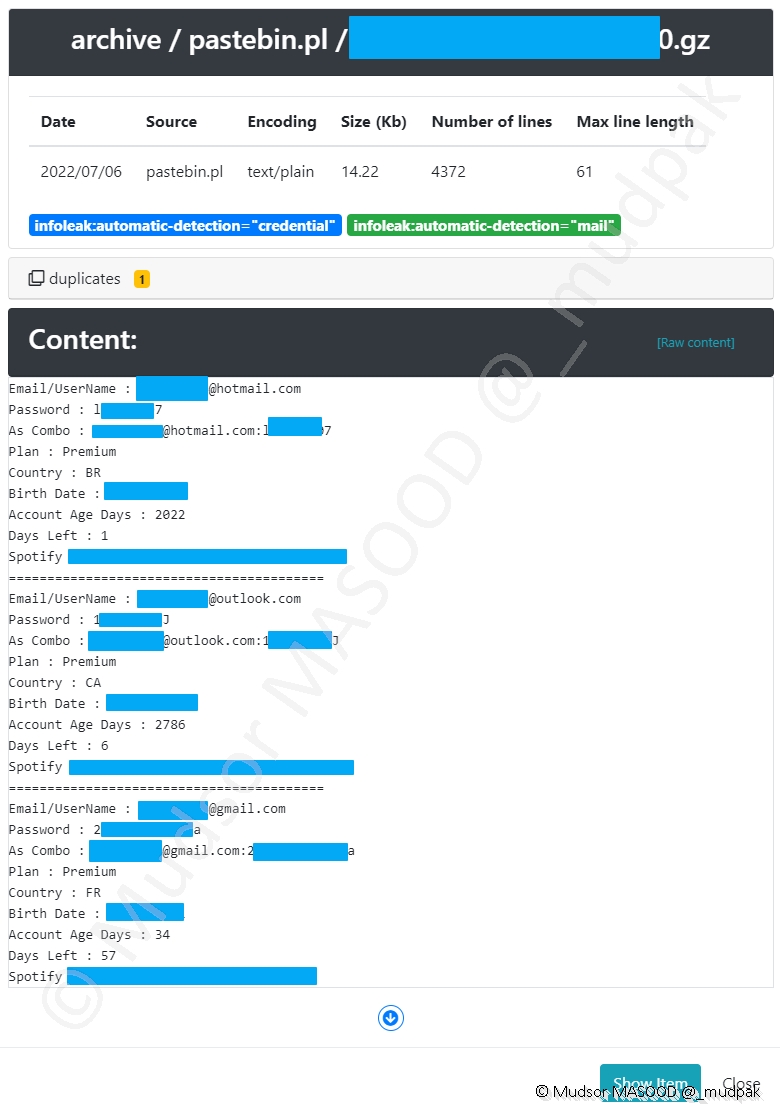
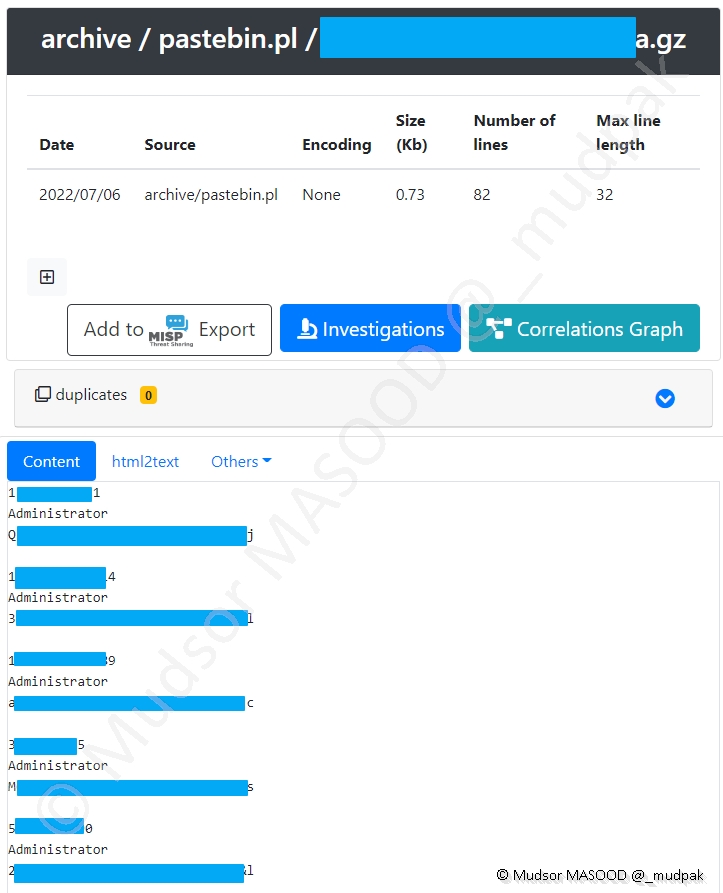
Prenons l’exemple d’une archive qui est apparue sur la plateforme car elle correspond à nos critères de recherches définis précédemment.
L’archive a été récupérée d’un paste sur Pastebin Poland.
Nous avons les informations suivantes sur celle-ci :
- Date : date à laquelle notre plateforme a récupéré l’élément
- Source : depuis quel site il a été récupéré
- Encoding : quel est le format de données
- Size : taille en kb
- Number of lines : nombre de lignes
- Max line length : la taille de la ligne la plus longue
Plus bas dans la section « Content : » nous pouvons observer un extrait du contenu disponible et voir les éléments suivants en clair :
- Email / Username : identifiant ou adresse email
- Password : mot de passe
En corrélation des autres éléments disponible nous pouvons déduire qu’il s’agit des comptes Spotify ainsi que les dates de fin des abonnements.
9.2.3.2 Credit cards
Voici des potentiels exemples de numéro de cartes bancaires qui ont été détectés par l’outil.
Après vérification il s’avère que ce sont de faux-positifs, à priori la plateforme confond des coordonnées GPS avec les numéros de cartes bancaires.
9.2.3.3 Mails
Comme vu précédemment il est possible de trouver des adresses email.
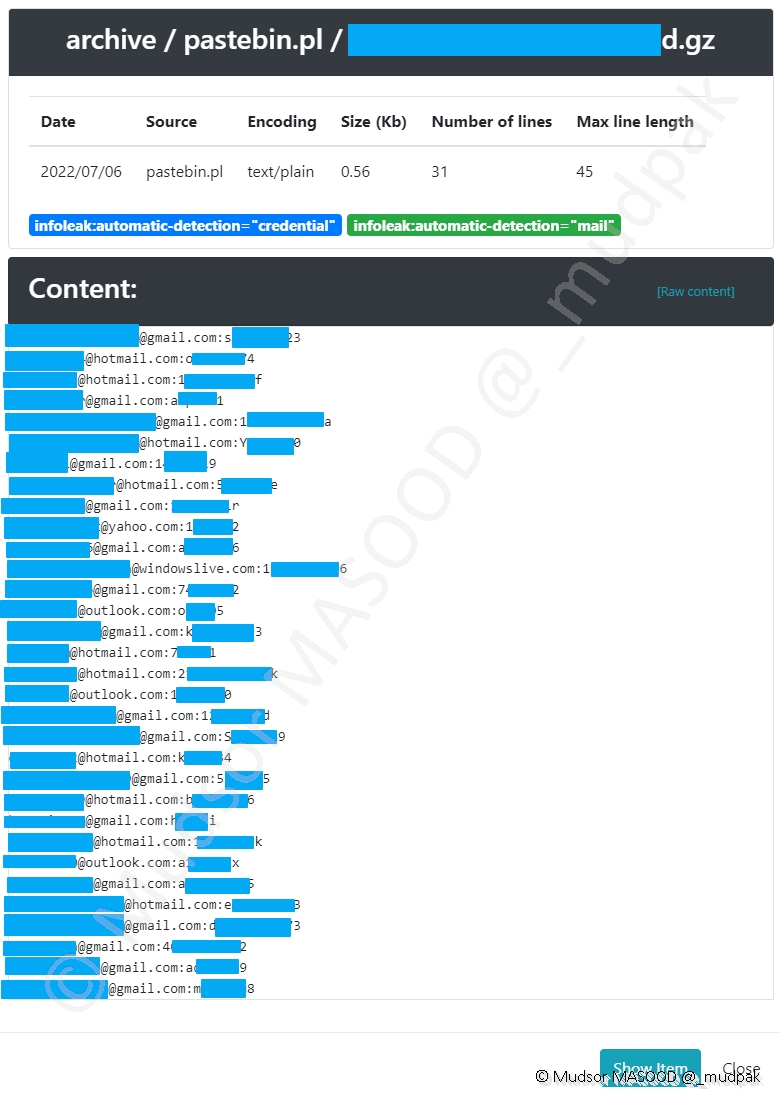
Si nous regardons de plus prêt un autre paste, ici il s’agit simplement des ID et MDP de connexion aux différentes messageries Email :
- Gmail
- Hotmail
- Outlook
Remarque
Au vu de la longueur et complexité (usages uniquement de chiffres et de lettres) des mots de passe nous pouvons suggérer qu’ils ont été trouvés via des opérations de brute-force.
9.2.3.4 CVEs
Voici un exemple de détection de CVE (Common Vulnerabilities and Exposures).
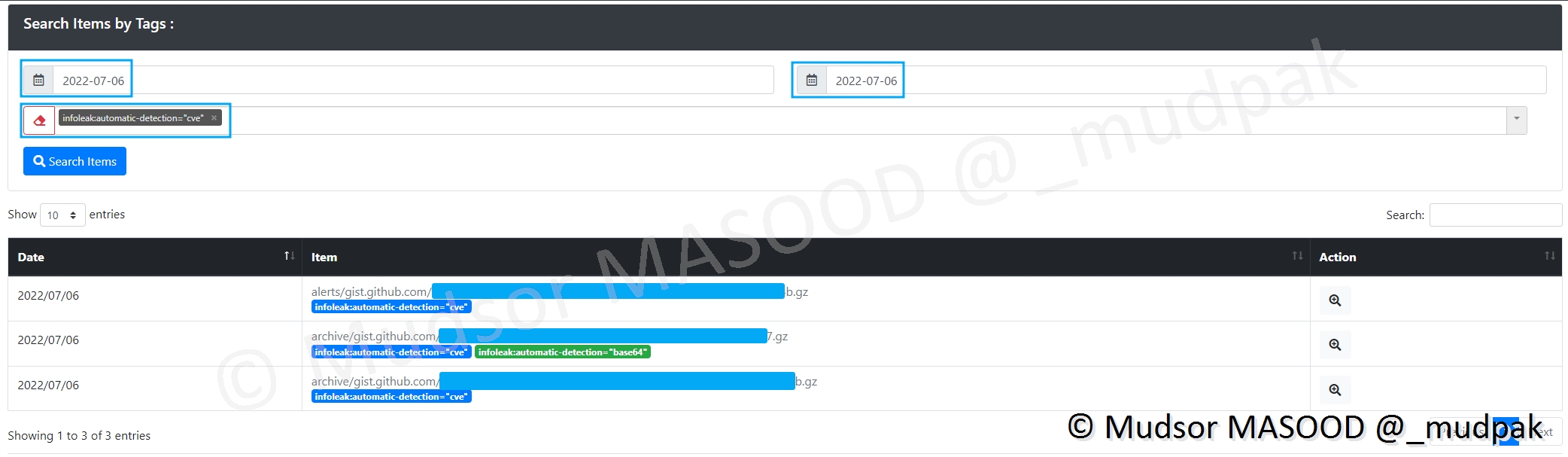
Si nous regardons de plus prêt un des leak, il est bien question d’une CVE, mais dans le contexte de l’utilisation dans un CTF.
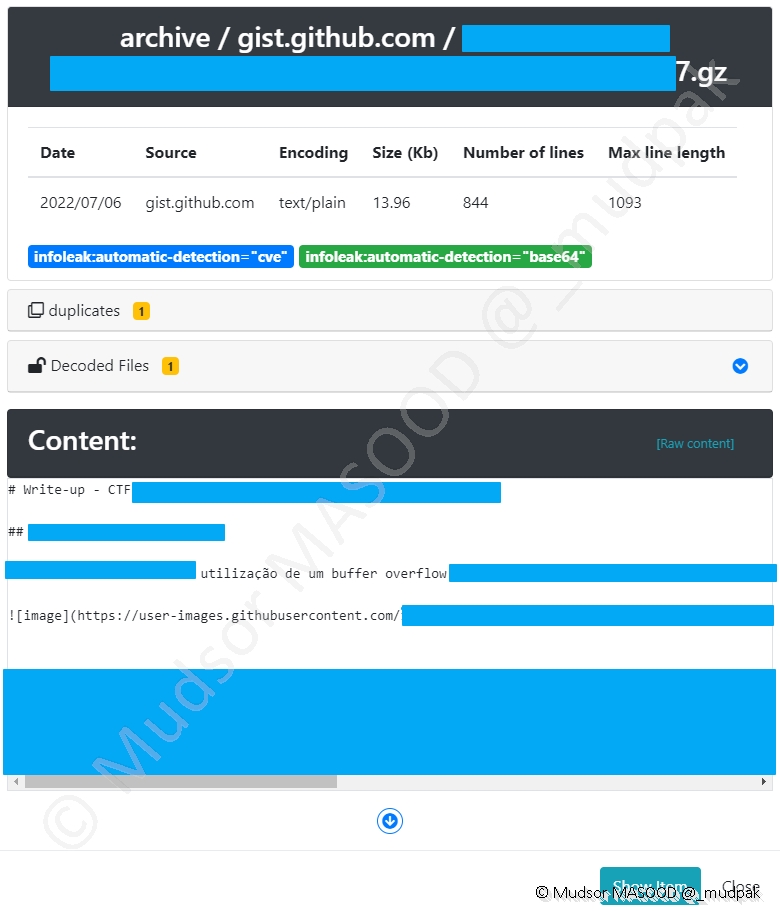
Si nous continuons à regarder le leak en question, ici il s’agit du writeup détaillé :
Et l’utilisateur a également indiqué les flags :

9.2.3.5 Onions
Ici des exemples de leaks évoquant des liens TOR.
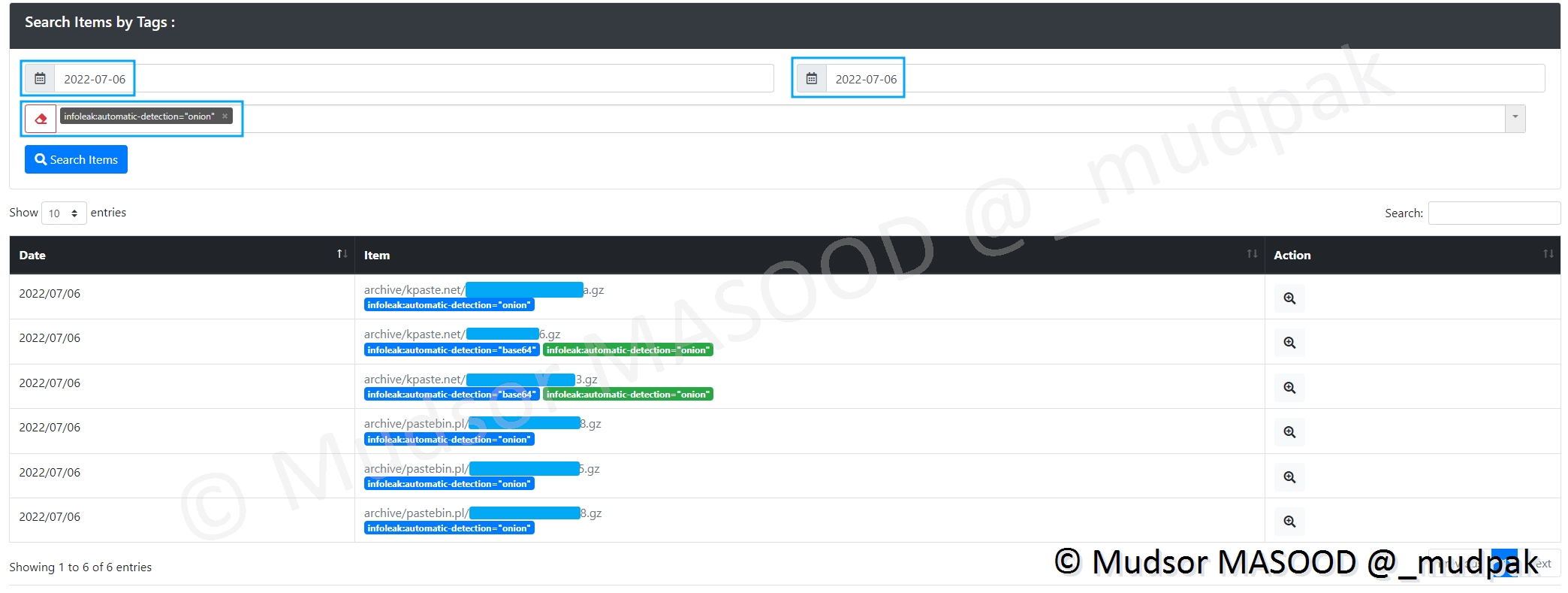
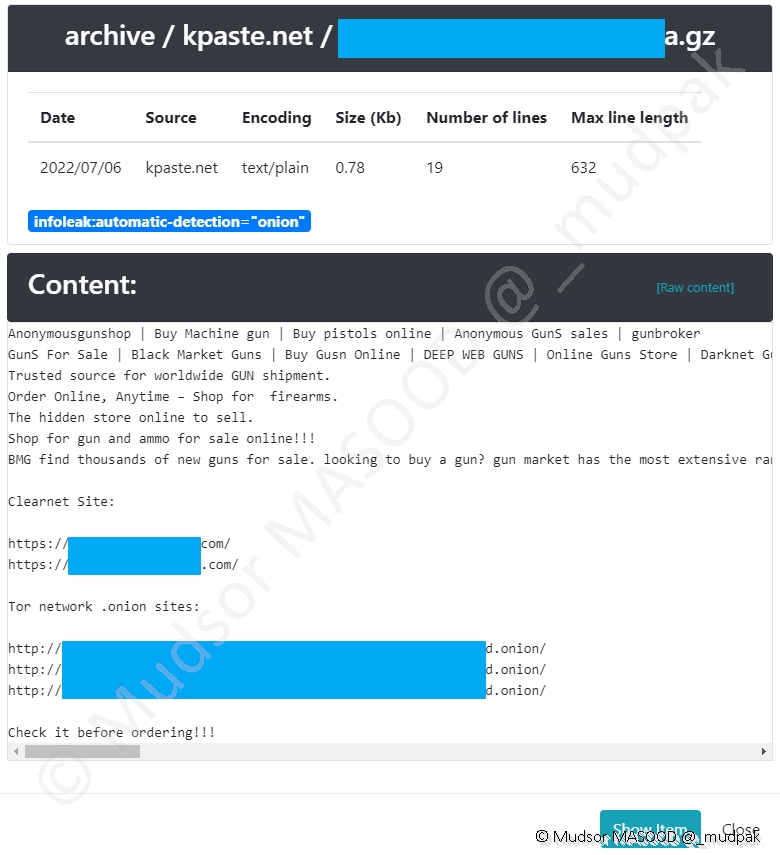
Si nous prenons l’exemple d’une archive provenant de la plateforme Kpaste[.]net, nous avons ici un cas d’un site de ventes d’armes :
9.2.3.6 Bitcoin
Voici un exemple d’élément contenant des éléments en lien avec du bitcoin.
Dans le cas présent, nous avons dans un email du chantage où un paiement en bitcoin est demandé à une adresse :

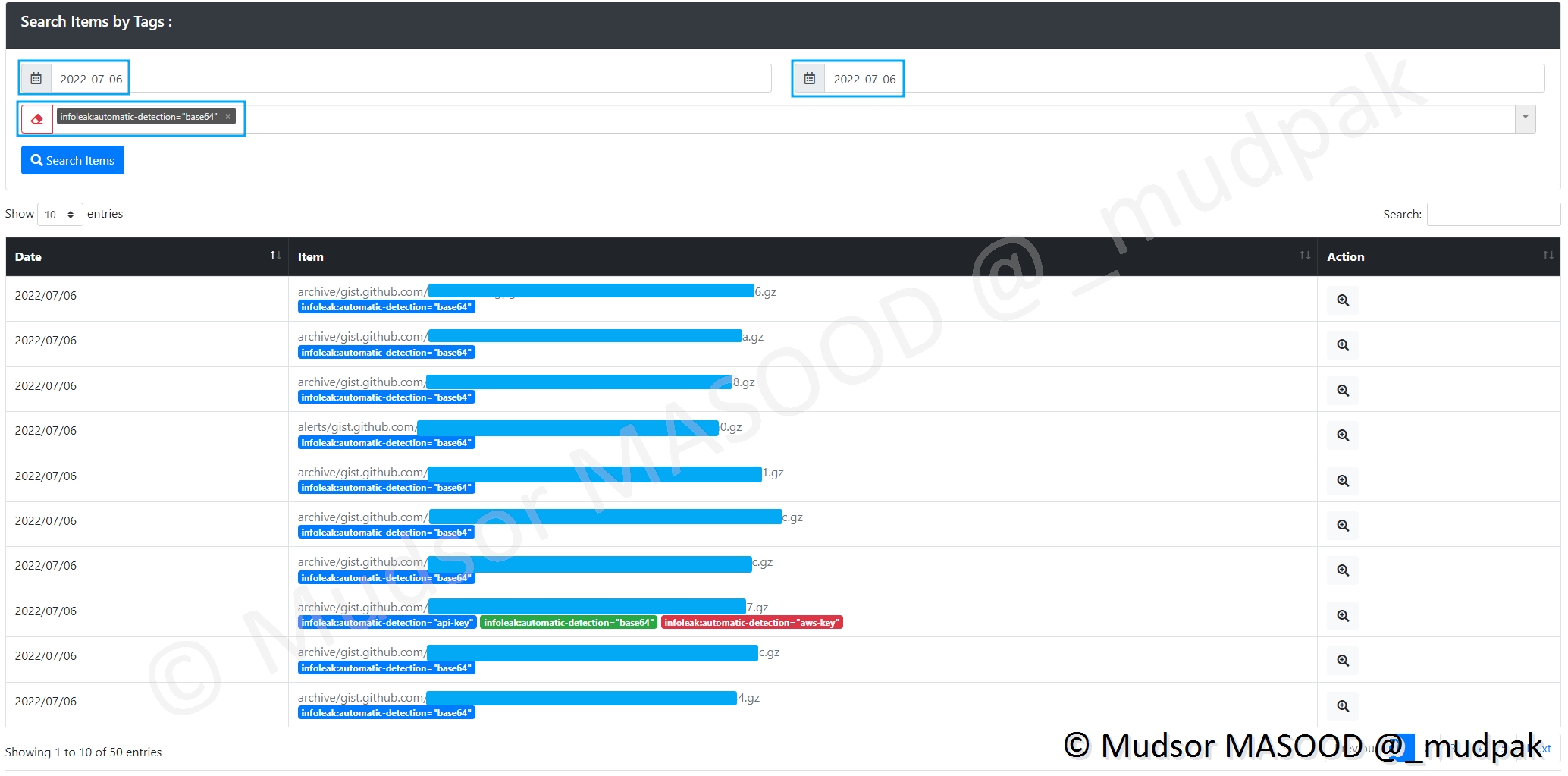
9.2.3.7 Base64
Si des éléments encodés en base64 sont trouvés, ils se trouvent dans cette section.
Dans le cas présent nous avons à priori un fichier de journaux AWS :
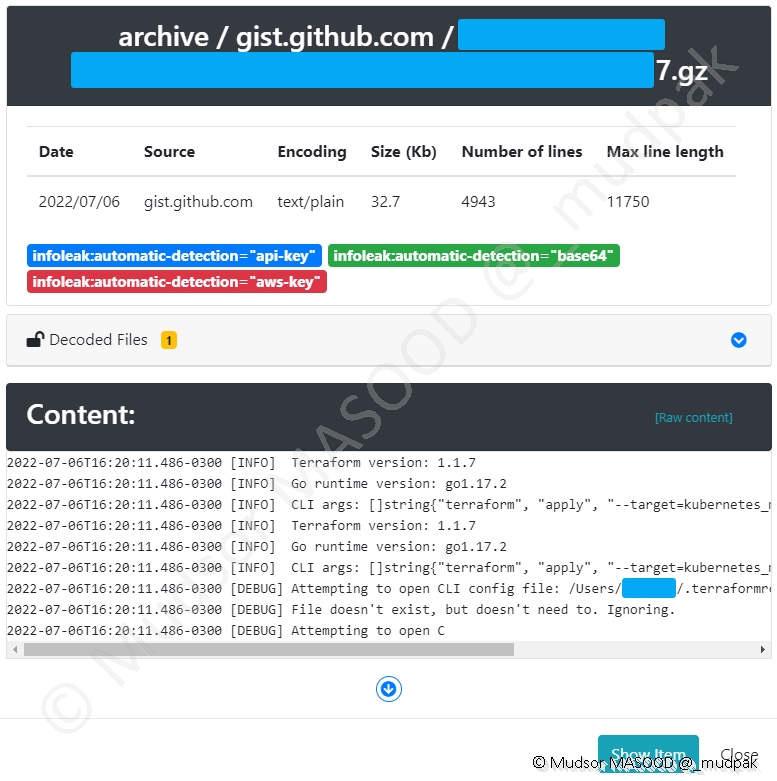
Si vous allons voir en détails le contenu, de nombreuses informations confidentielles sont présentes :
- 1) l’adresse complète dès l’instance
- 2) les identifiants et informations sur les instances
- 3) informations sur l’infrastructure (configuration des VPC, appartenant aux clusters. . .)
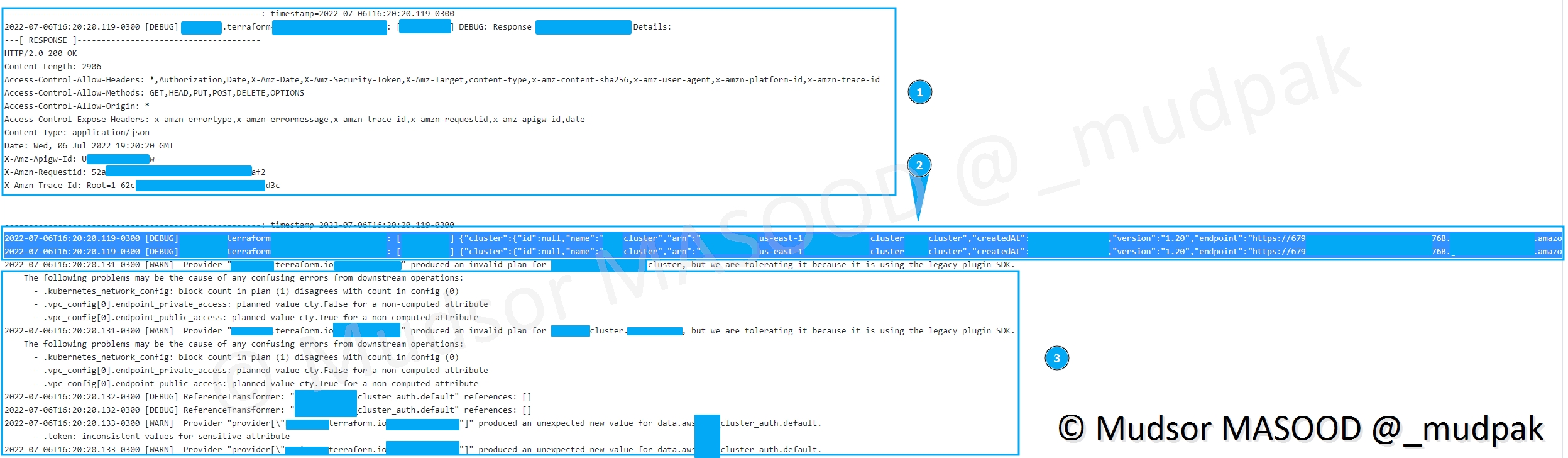
Et ici nous avons des clés utilisant l’encodage base64 :

Si nous allons dans CyberChef pour afficher en clair le contenu nous pouvons observer le résultat et voir qu’il s’agit des certificats X.509 :
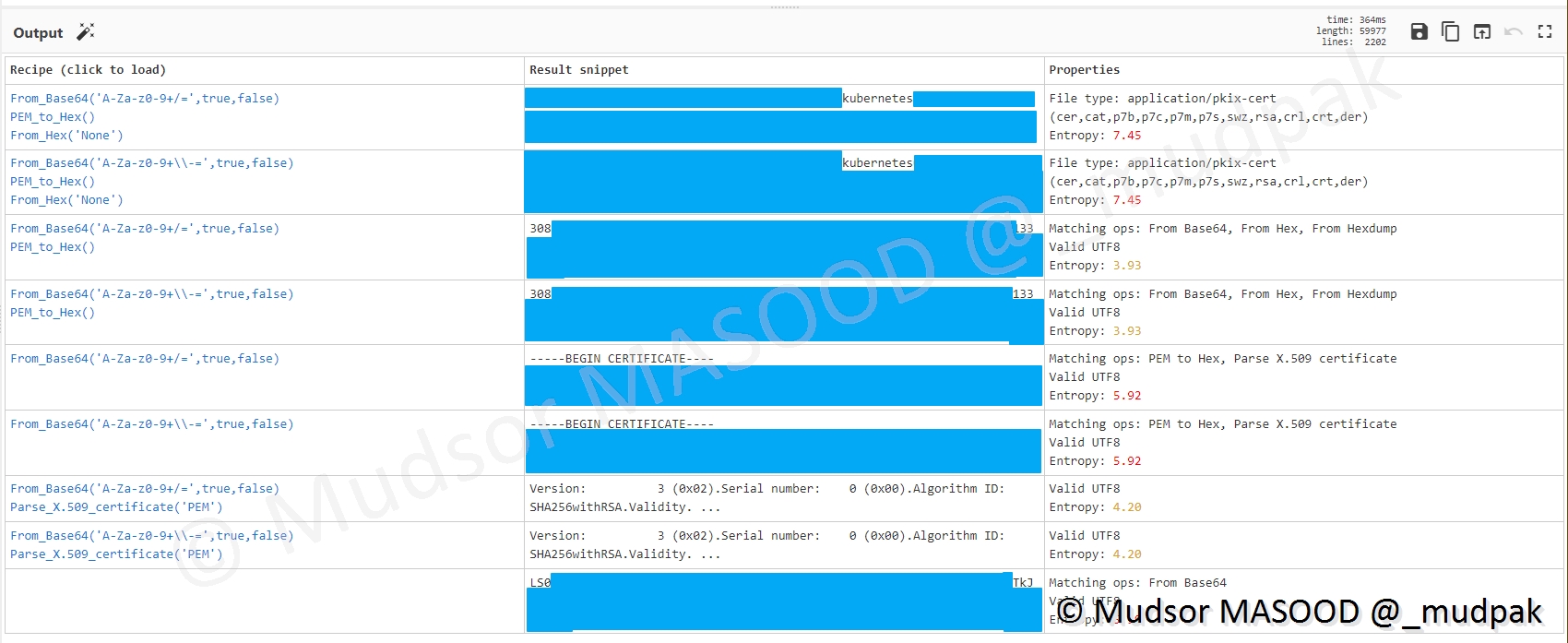
Avec tous ces éléments il est facile pour un attaquant de se connecter aux infrastructures cloud et effectuer des opérations malveillantes.
9.2.3.8 Phones
Pour l’instant il n’y a pas eu d’éléments dans ce menu, car je n’ai pas laissé l’infrastructure allumée pendant une longue période.
9.2.4 Leaks Hunter
Dans les chapitres précédents nous avions prédéfinis des mots clés, regex et dictionnaires de mots allons voir s’il y a eu des résultats.

9.2.4.1 Words
Pour voir les mots qui ont été trouvés, cliquer sur
- Leaks Hunter
- Words
Les mots ci-dessous semblent avoir été trouvés :
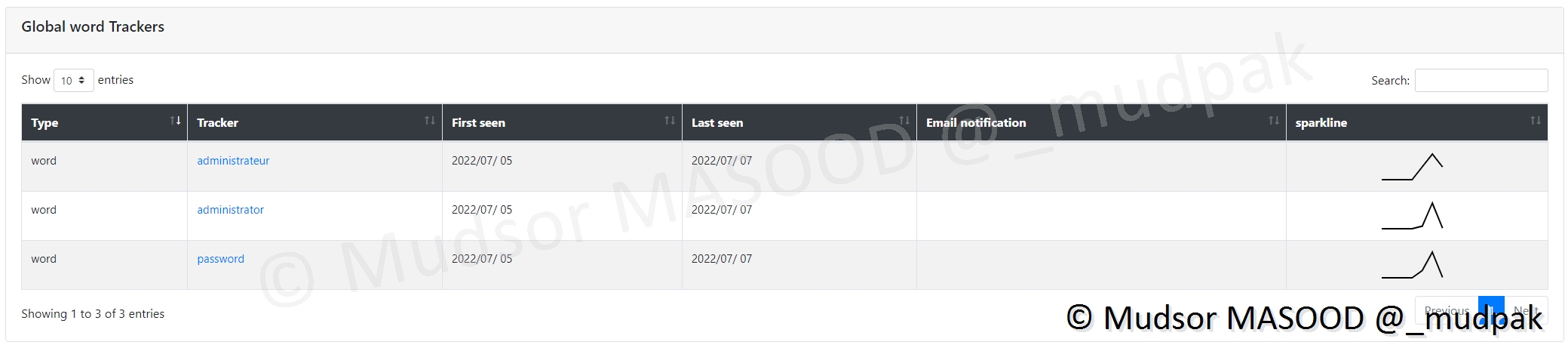
Si nous prenons l’exemple du mot « administrator » nous pouvons observer les éléments suivants :
- 1) un UUID est lié à cette requête ainsi il n’y a pas de doublons
- 2) quel type de recherche est faite ? un mot ? un regex. . .
- 3) créateur de la requête ?
- 4) date de création de la requête
- 5) qui peut accéder à cette requête
- 6) l’utilisateur qui a créé cette recherche
- 7) la première fois que le mot a été trouvé
- 8) la dernière fois que le mot a été trouvé
- 9) tags à ajouter
- 10) email à prévenir en cas d’occurrence
- 11) un graphe
- 12) depuis quelles sources il a eu une occurrence
- 13) dates auxquelles il a eu une occurrence
- 14) date de début de recherche
- 15) date de fin de recherche
- 16) si nous souhaitons apporter des modifications
- 17) si nous souhaitons supprimer cette recherche d’occurrences
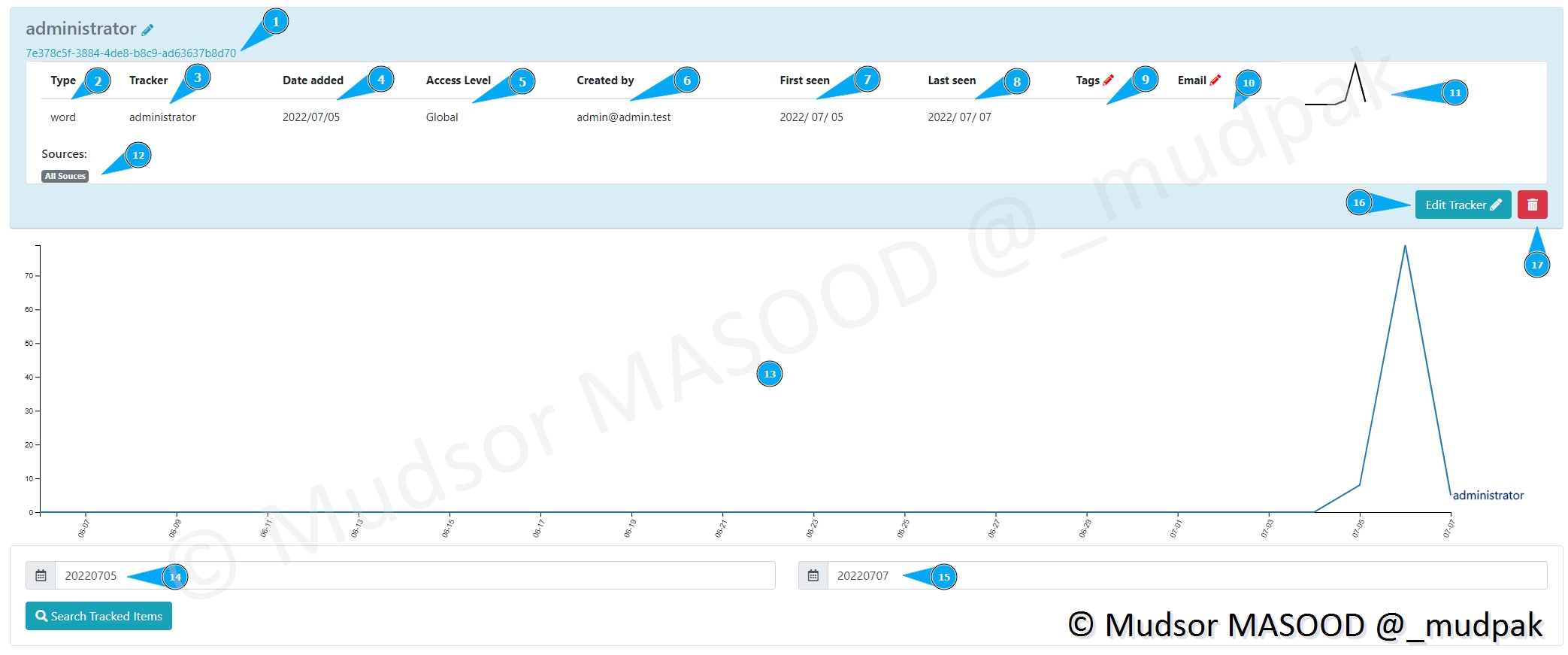
De la même manière que les précédents résultats, si nous regardons de plus prêt nous pouvons observer les éléments suivants dans l’ordre
- Adresses IP publiques des serveurs
- Comptes utilisateurs
- Mots de passe associé aux comptes utilisateurs
Un attaquant qui a entre les mains ces trois informations n’a quasiment rien à faire pour prendre le contrôle des machines.
9.2.4.2 Set
Pour afficher les occurrences des groupes de mots, cliquer sur
- Leaks Hunter
- Set
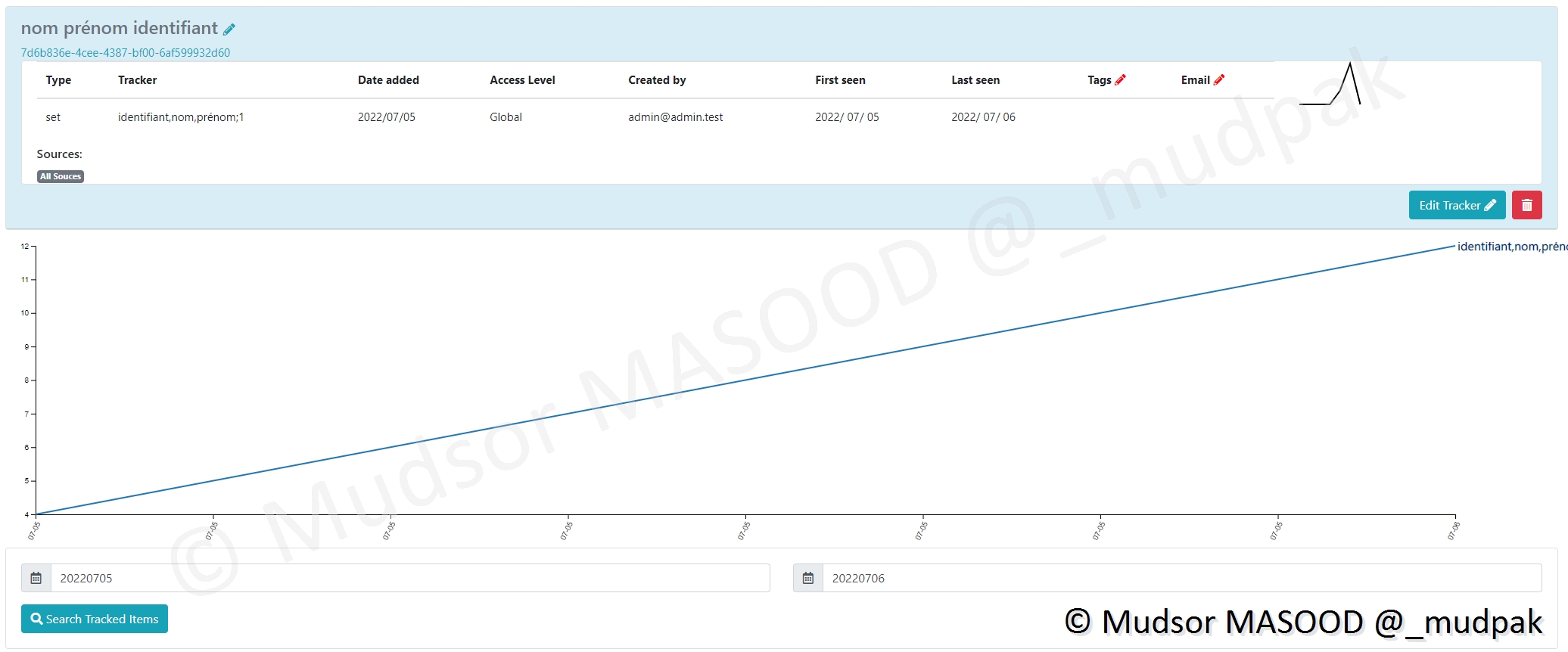
Prenons l’exemple du second set nommé « nom prénom identifiant » :

Ici nous pouvons observer que la première occurrence date du 5 Juillet 2022 :
9.2.4.3 Regex
L’utilisation des mots ou groupes de mots est certes pratique mais ne permet pas d’avoir des résultats très pertinents ou précis, dans ces cas là l’usage des regex deviens indispensable.
Pour voir les résultats, cliquer sur
- Leaks Hunter
- Regex
Ici nous avions prédéfinis un certain nombre de regex, certaines ont eu des occurrences (de la première à la 7éme) d’autres non (de la 8éme à 10éme).
Remarque
Tout dépend de la durée de fonctionnement de votre plateforme, plus elle est active longtemps plus il y a des probabilités que des occurrences apparaissent.
Voyons en détails les différentes Regex qui ont été définis :
- 1) Generic API Key/ Generic Secret
- 2) Firebase URL
- 3) SSH (EC) private key
- 4) Google API Key
- 5) AWS API Key
- 6) Generic Secret
- 7) SSH (DSA) private key
- 8) Square OAuth Secret
- 9) Heroku API Key
- 10) MailChimp API Key
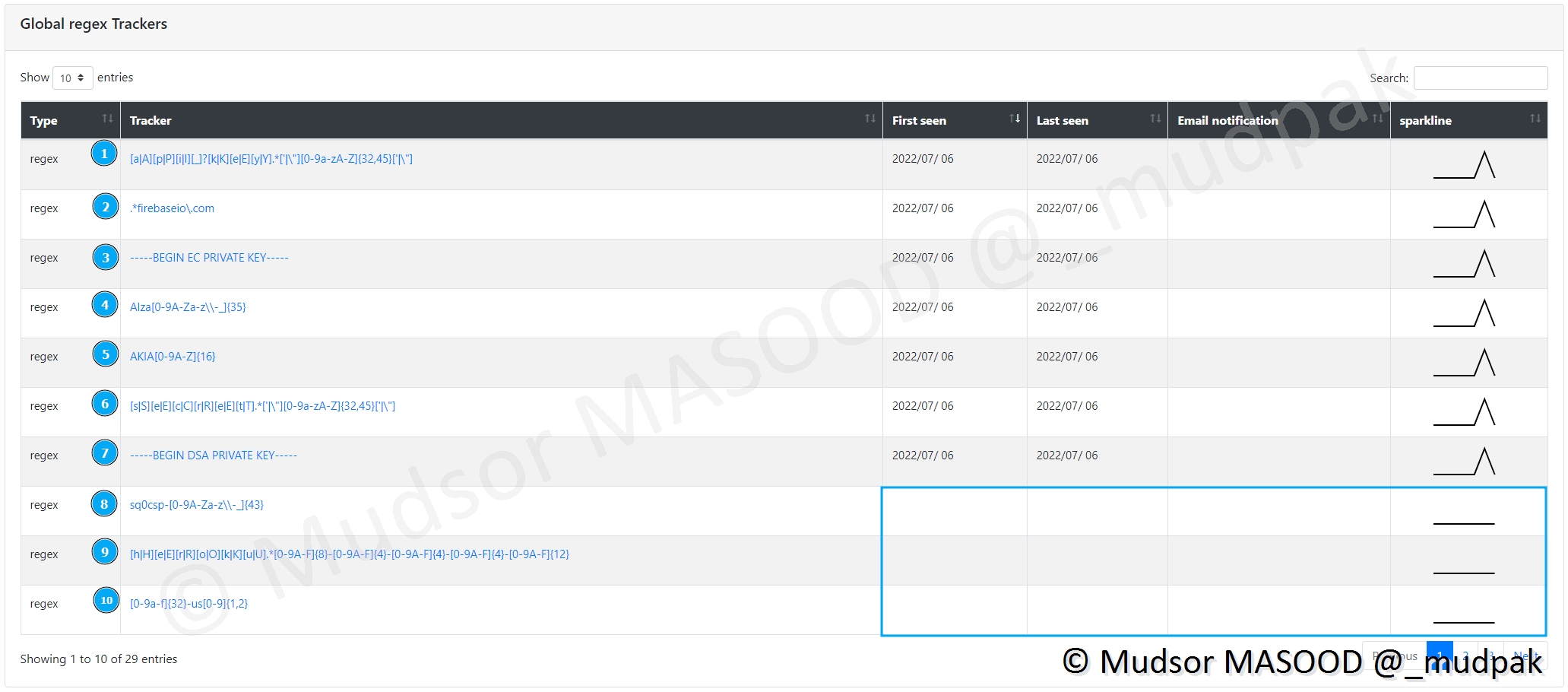
Prenons l’exemple de l’occurrence d’une clé privée SSH :
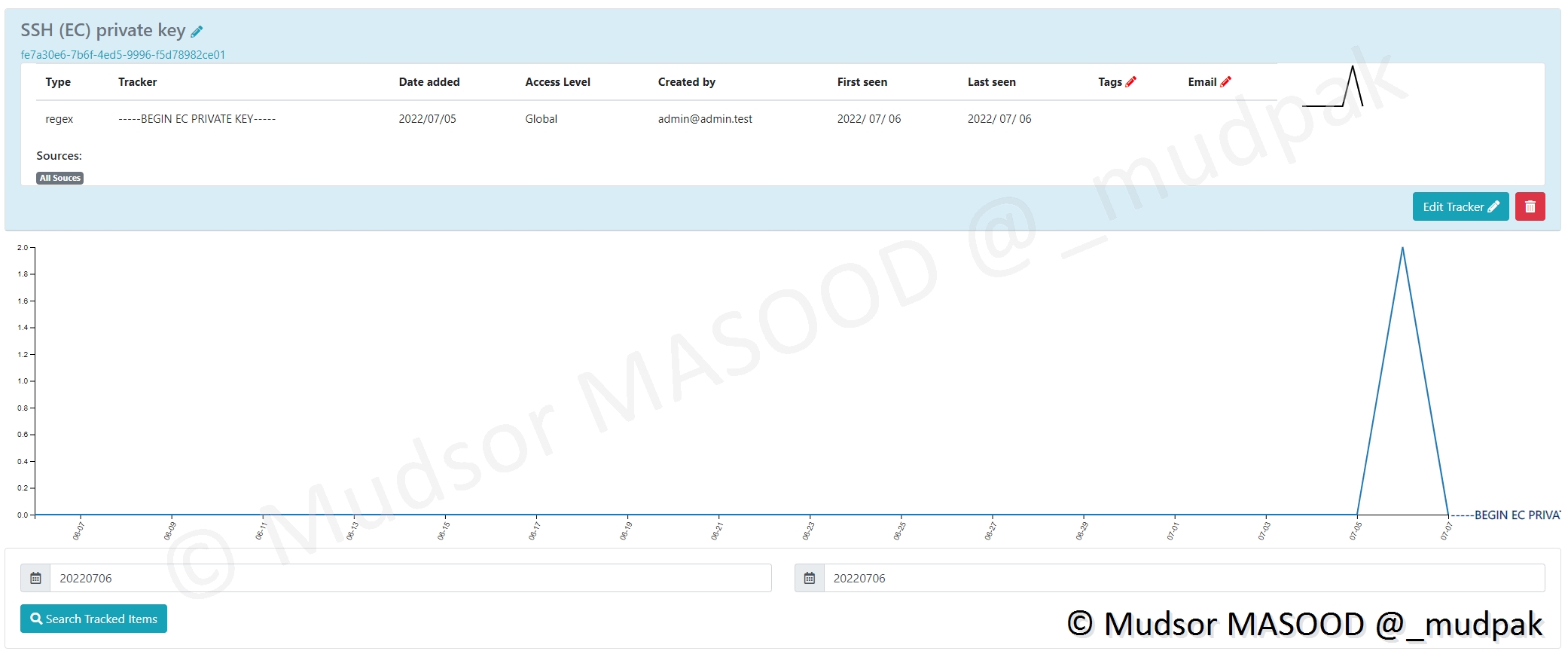
Au niveau des tags nous voyons qu’elle a bien été classée :
- certificate : puisqu’il s’agit d’un certificat
- ec-private-key : puisqu’il s’agit d’une clé privée
- dsa-private-key : le fichier contient potentiellement en plus de la clé privée EC, une clée privée DSA

Si nous regardons plus en détails le contenu du fichier, ici nous pouvons voir les informations de la clé privée EC :

Et ici nous pouvons observer la partie de la clé publique EC :

Et ici nous avons la clé privée DSA :

9.2.5 Objects
Voyons maintenant la partie « Objects ».

9.2.5.1 Decoded
Pour voir les éléments encodés qui ont été trouvés, cliquer sur
- Objects
- Decoded
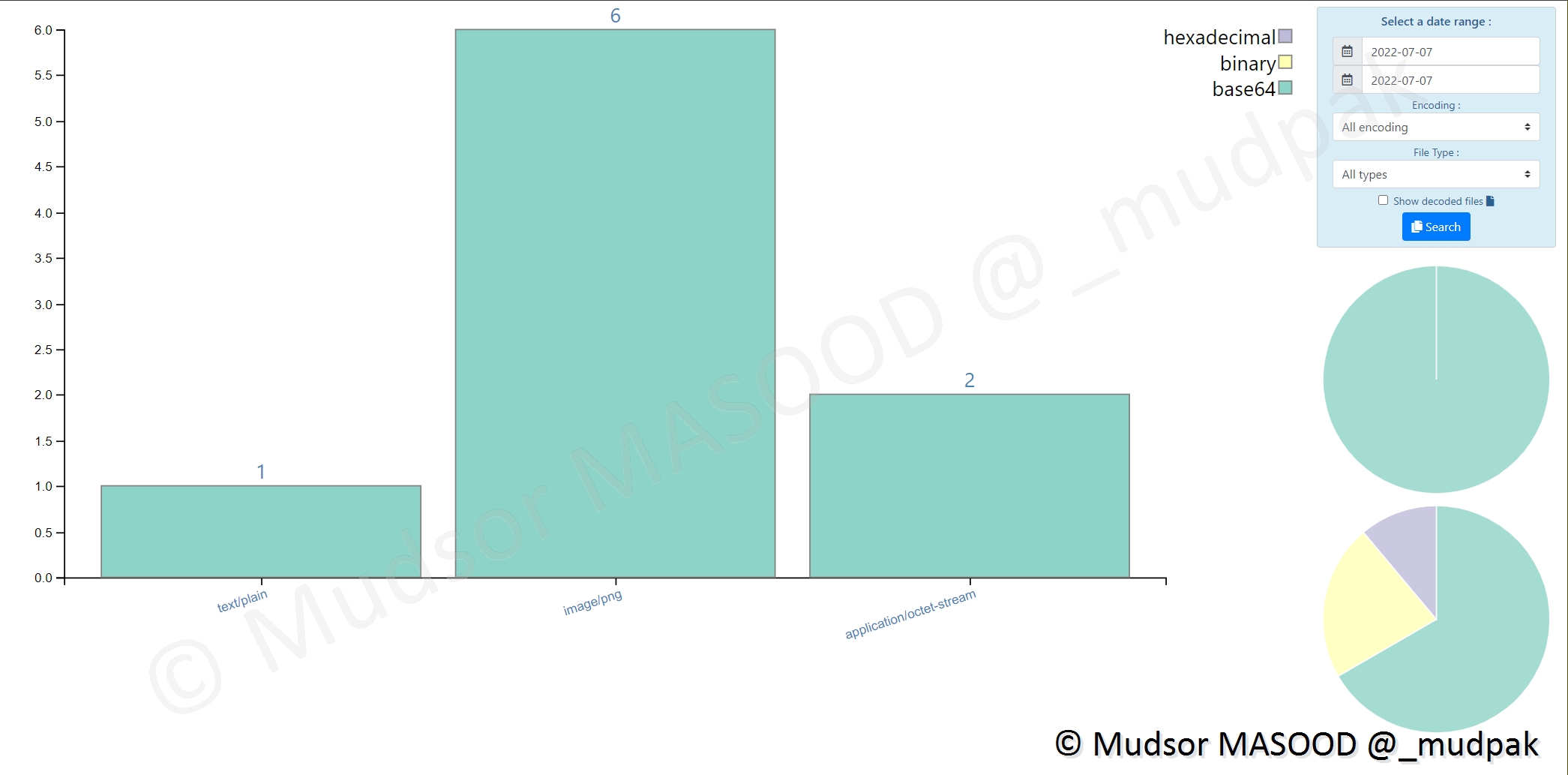
Ici nous pouvons voir qu’il y a eu différents types d’éléments qui ont été trouvés :
- text/plain
- image/png
- application/octet-stream
Remarque
Pour les afficher, il faut penser à cliquer sur « Show decoded files ».
9.2.5.2 PGP Dumps
Pour afficher les éléments PGP, cliquer sur
- Objects
- PGP Dumps
Dans notre cas il n’y a pas eu ce type d’éléments :
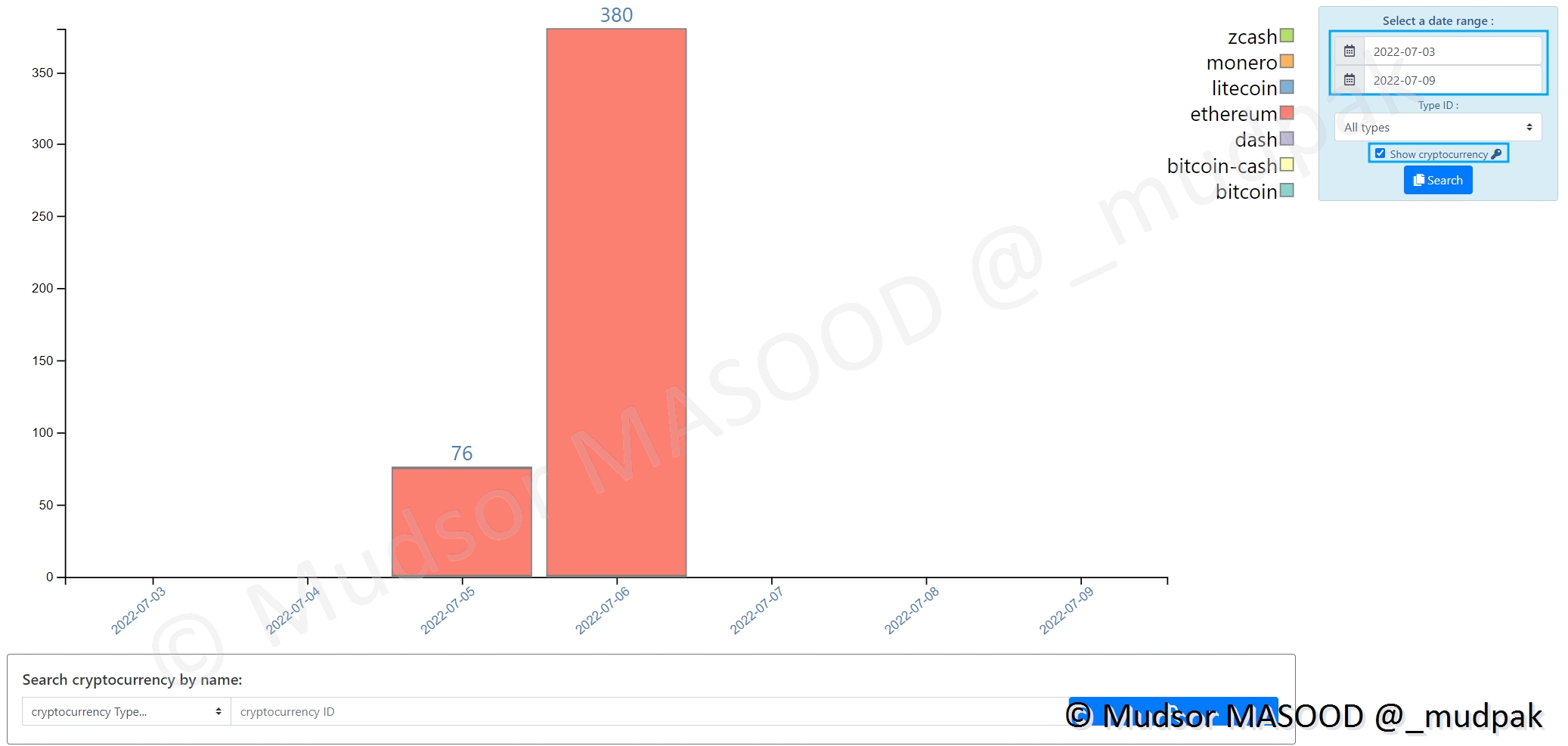
9.2.5.3 Cryptocurrency
Pour voir les éléments en lien avec les cryptomonnaies, cliquer sur
- Objects
- Cryptocurrency

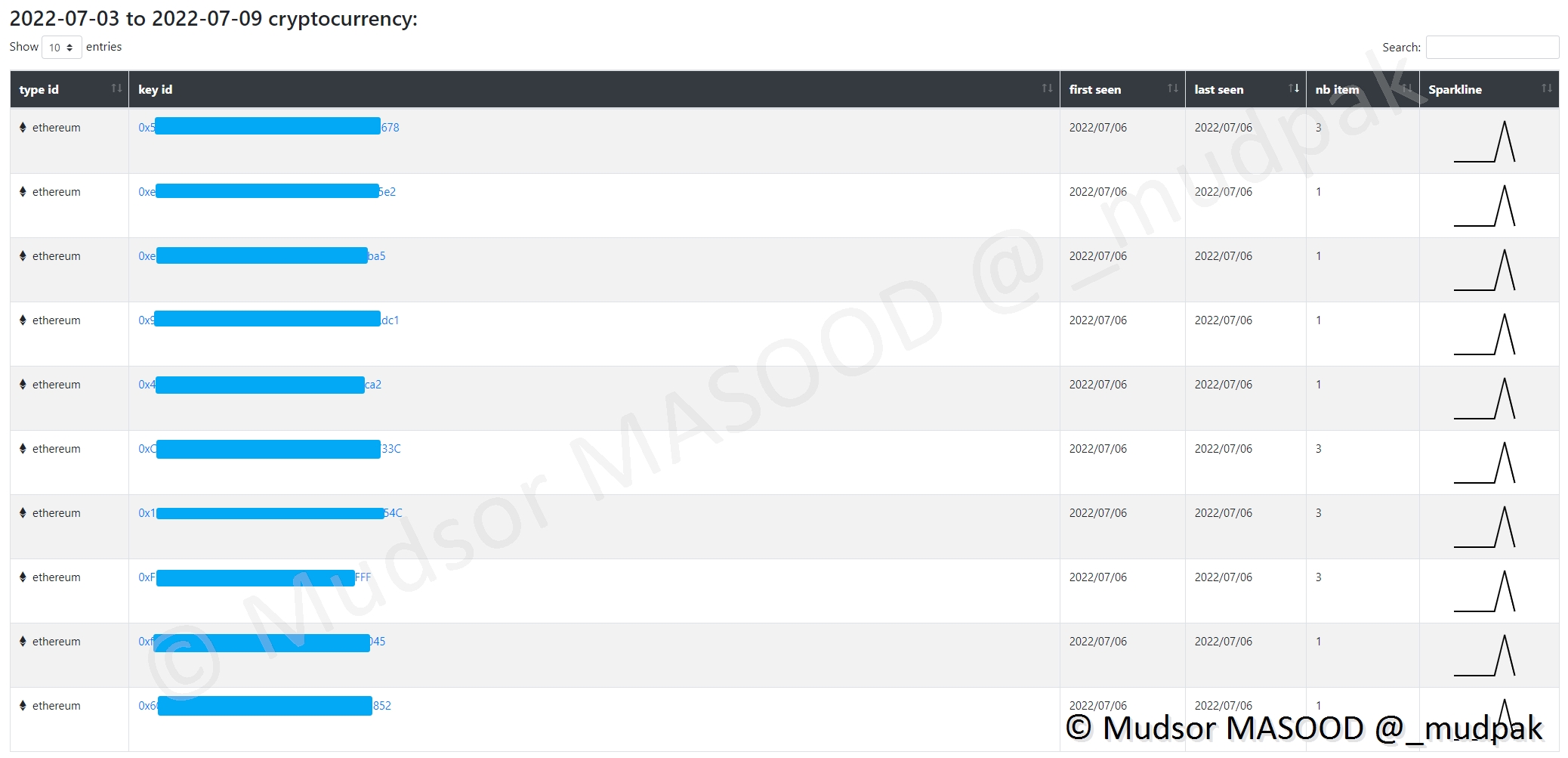
Dans le cas présent nous pouvons observer qu’il y a eu de nombreuses occurrences sur de l’ethereum :
Nous pouvons voir en détails les adresses des wallets :
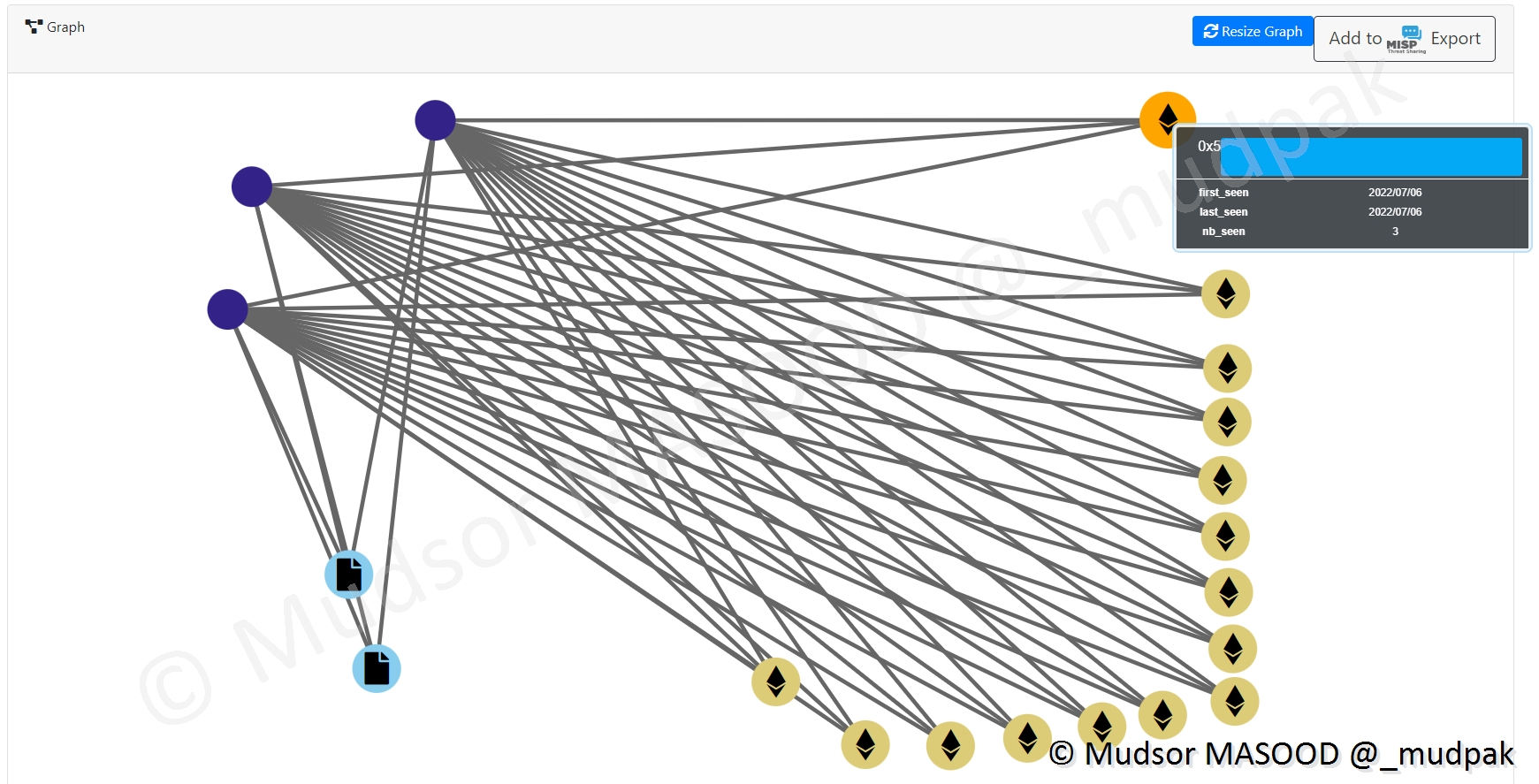
Il est également possible de voir les corrélations en cliquant sur un des wallets, ainsi les différents liens sont affichés :
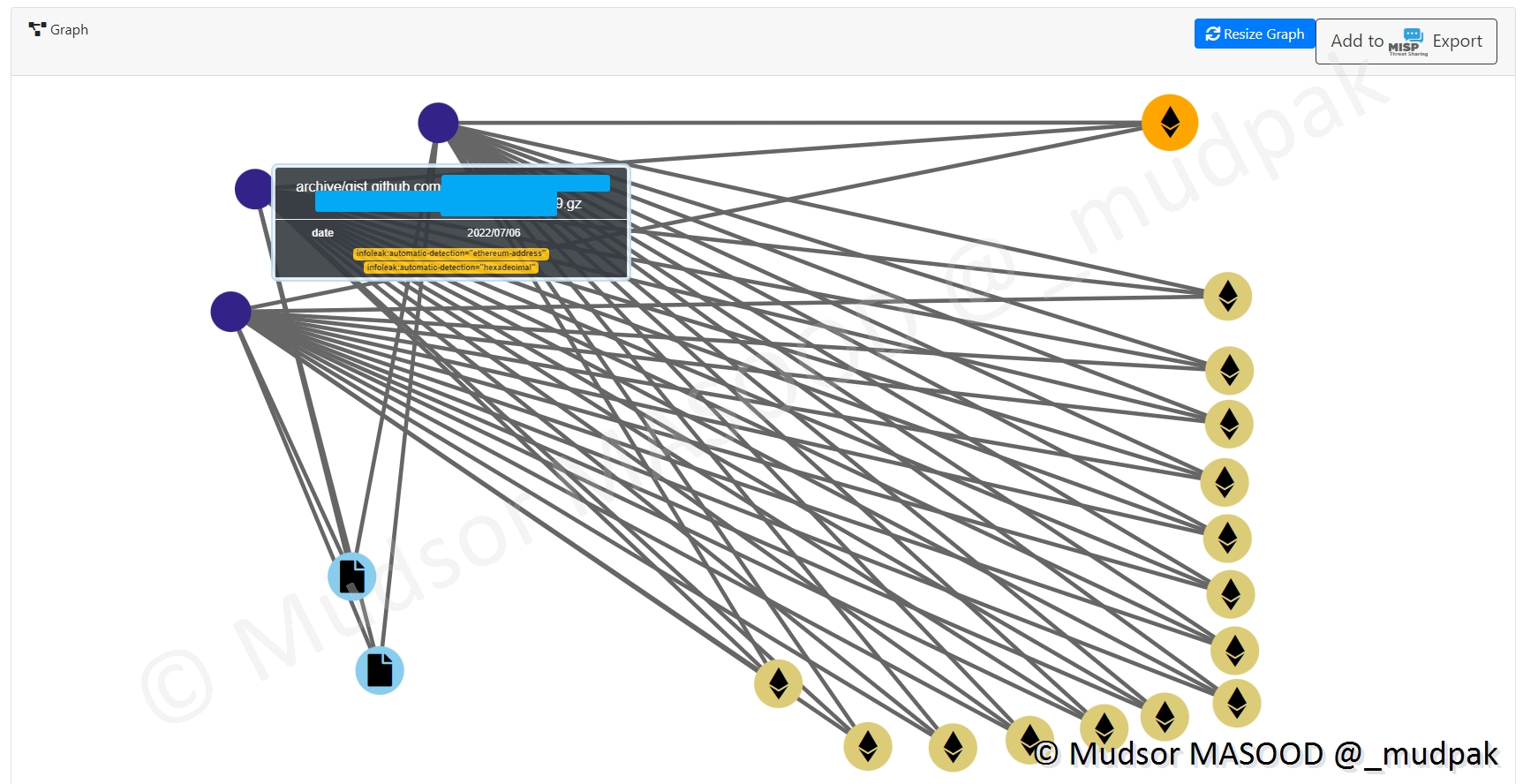
En violet nous avons le fichier dans lequel ces éléments ont été trouvés :
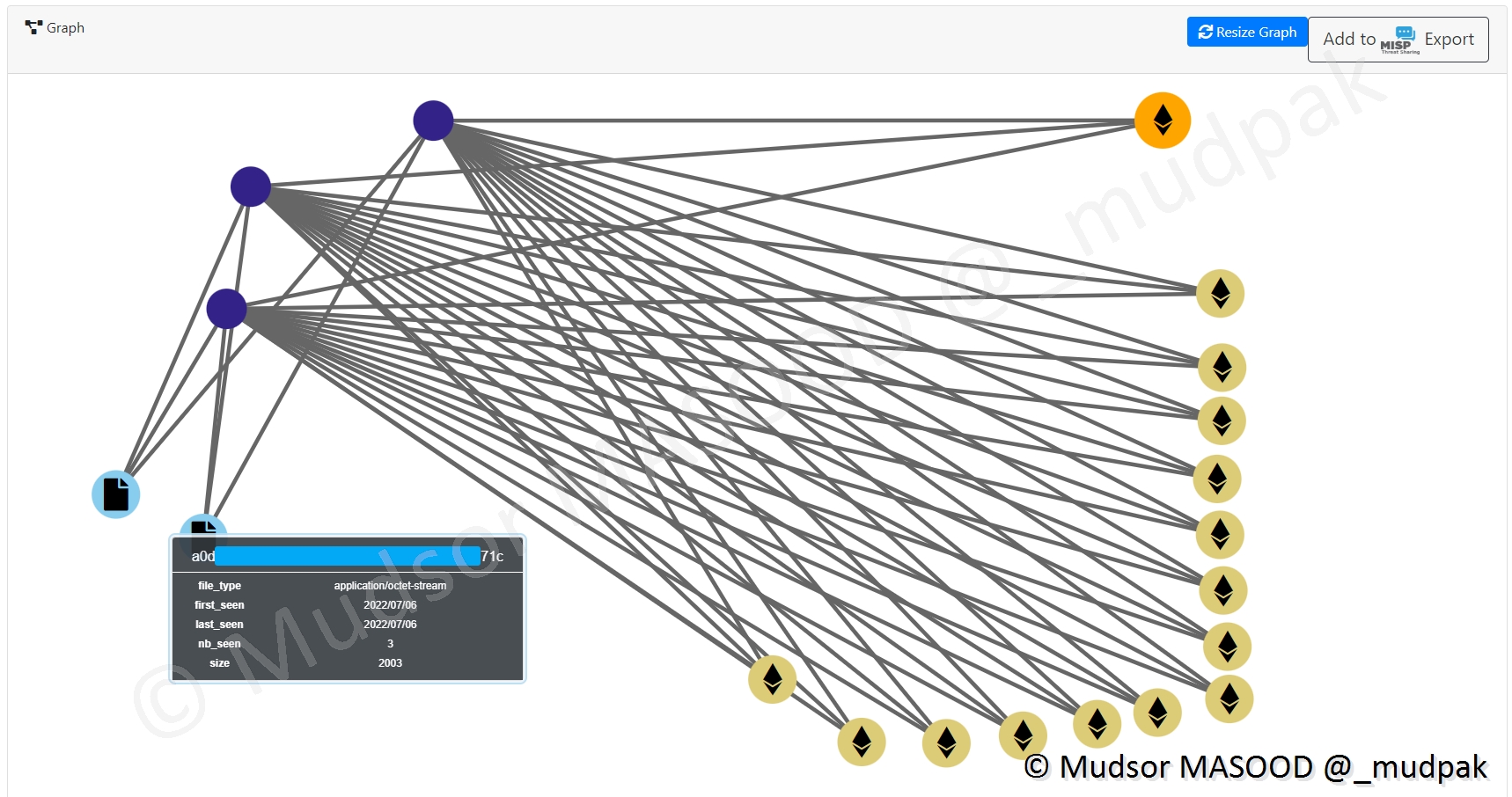
En bleu clair nous avons des éléments de type « application/octet-stream », ainsi que leur hash :
9.2.5.4 Username
Nous pouvons définir des mots, groupes de mots ou regex pour trouver des identifiants et mots de passe, la section « Username » permet de les retrouver d’une autre façon, cliquer sur
- Objects
- Username
Dans le cas présent il y a eu des occurrences de usernames sur le réseau Telegram :
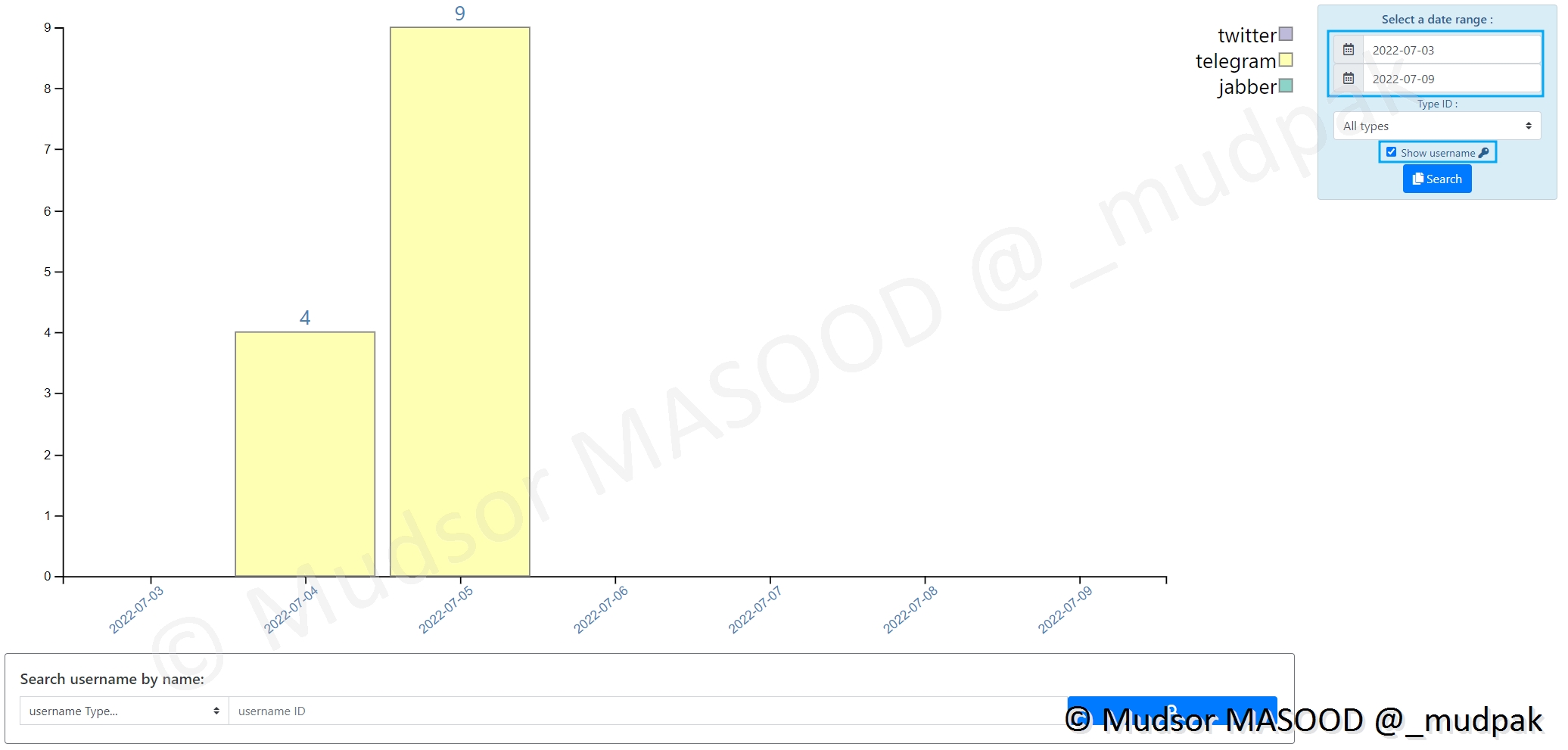
Nous pouvons voir les noms des comptes et il s’agit souvent de comptes de bots :
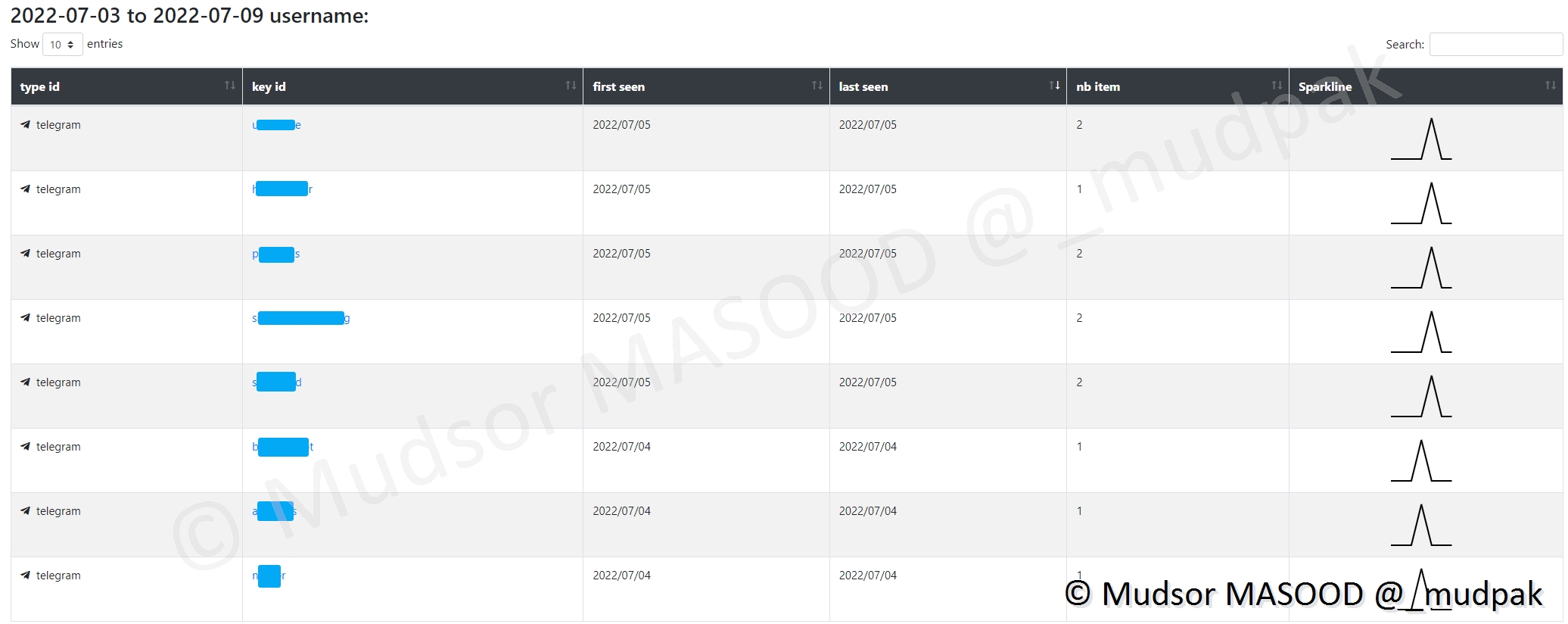
Ici nous avons le graphe de corrélation entre le username et les éléments détectés :
Ici un fichier qui a été partagé par l’utilisateur :
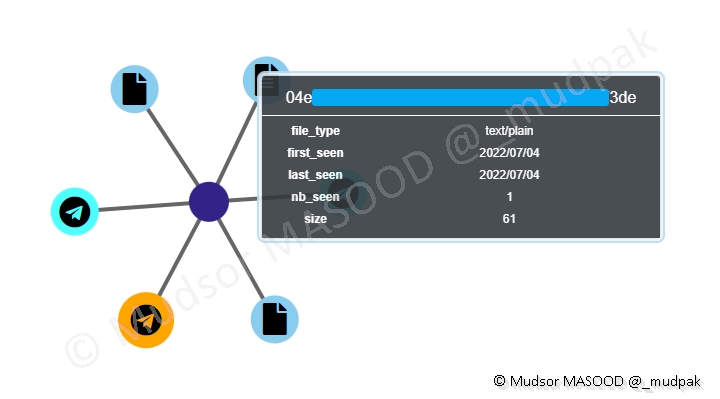
Un autre élément en relation avec le même compte :
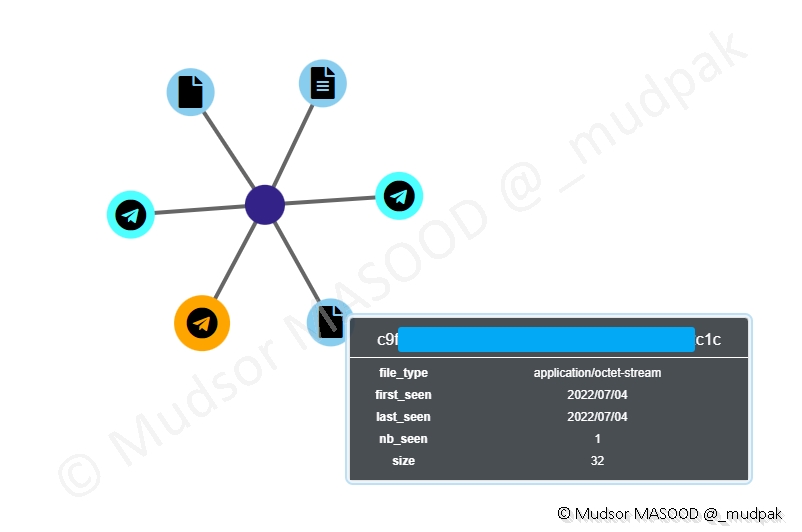
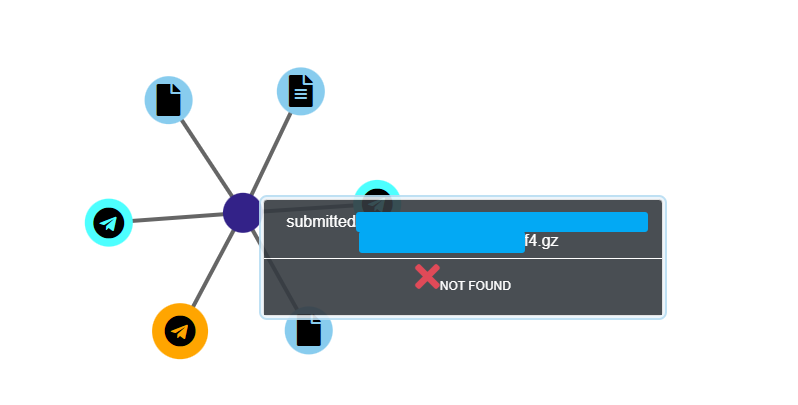
Dans le cas présent bien que les données soient affichées, il ne sera pas possible de récupérer l’archive intégralement car elle a été supprimée de la plateforme.
Remarque
C’est un cas de soumission manuelle de données d’où le nom « submitted. . . ».
9.2.6 Statistics
Selon la configuration de nombreuses données de différentes natures peuvent être récoltées et traitées.
Il est possible d’avoir un aperçu encore plus visuel sous forme de graphes et camembert en allant dans la section « Statistics ».

9.2.6.1 Credential – most posted domain
Cette partie permet d’afficher :
- 1) les domaines d’où proviennent les identifiants
- 2) cliquer pour afficher un graphe dans le temps
- 3) de quand dates les données

Prenons le cas suivant :
- 1) les domaines autres que ceux affichés sont représentés par « Other »
- 2) les différents domaines qui ne sont pas affichés par manque de place sur le camembert

9.2.6.2 Mail – most posted domain
Cette section bien que très semblable à la précédente, permet d’afficher les domaines d’où proviennent les adresses emails, dans le cas présent nous pouvons voir que ces adresses sont très variées et il n’y a pas de domaine plus marquant qu’un autre :
- orange[.]fr
- free[.]fr
- yahoo[.]fr

9.2.6.3 Provider
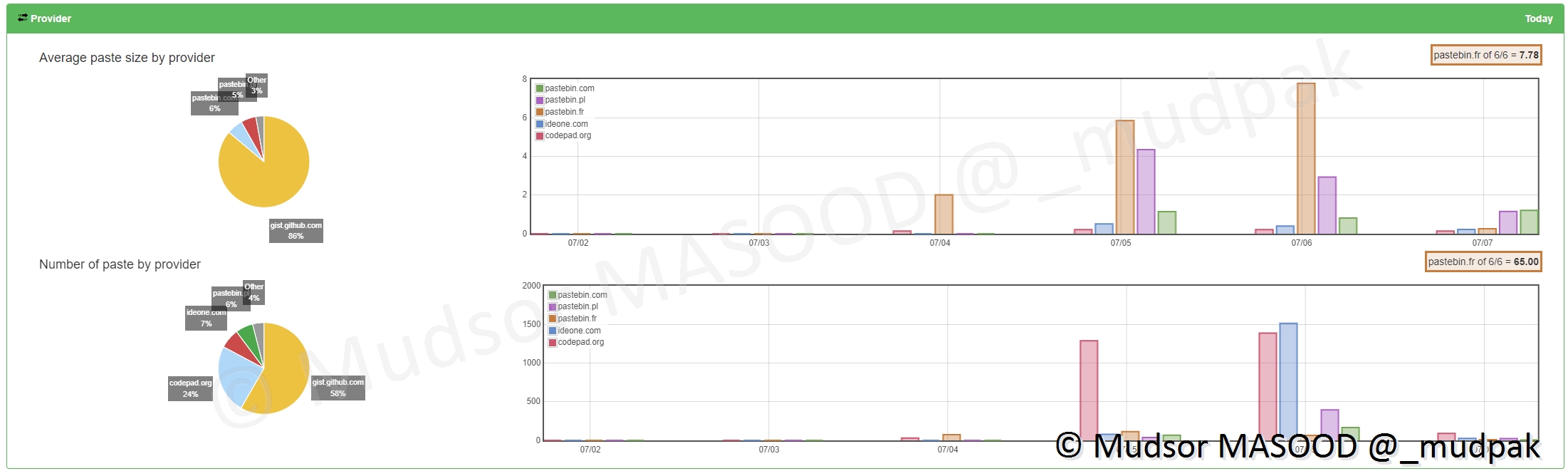
Les providers représentent ici les sources de données, tout va dépendre encore une fois du nombre de sites que vous allez activer pour recevoir les éléments.
Il y a deux sections ici :
- Average paste size by provider : taille moyenne des téléchargements par site
- Number of paste by provider : nombre de téléchargements par site
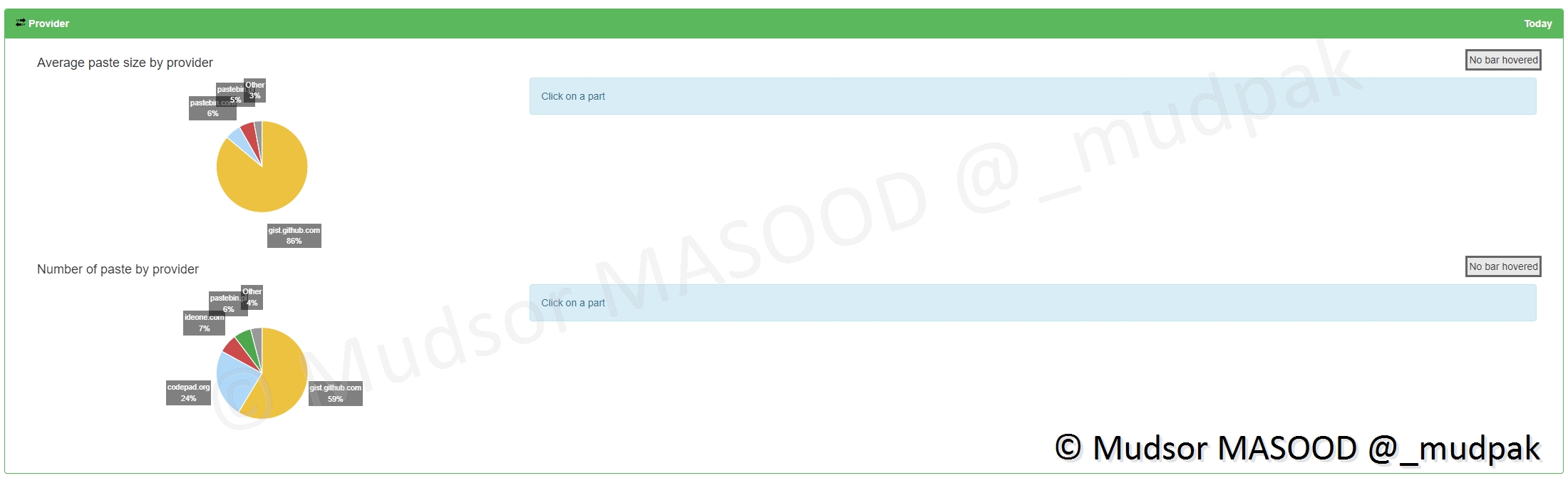
En détails voici le résultat dans notre cas :
- Average paste size by provider : -
- Number of paste by provider : la grosse majorité des données proviennent de github[.]com
9.2.7 Sentiment Analysis
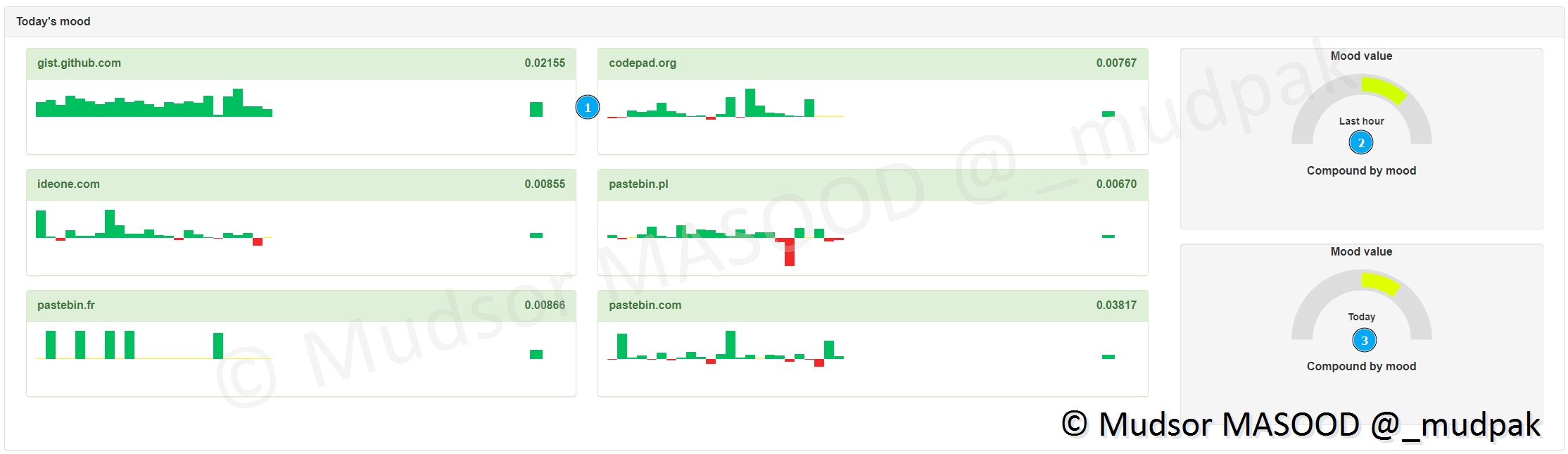
9.2.7.1 Trending
Cette section permet d’afficher les tendances des données :
- 1) sur la journée actuelle, quelle plateforme fournie le plus de données (vert = réception, rouge = aucune donnée)
- 2) la tendance sur la dernière heure
- 3) la tendance sur la journée
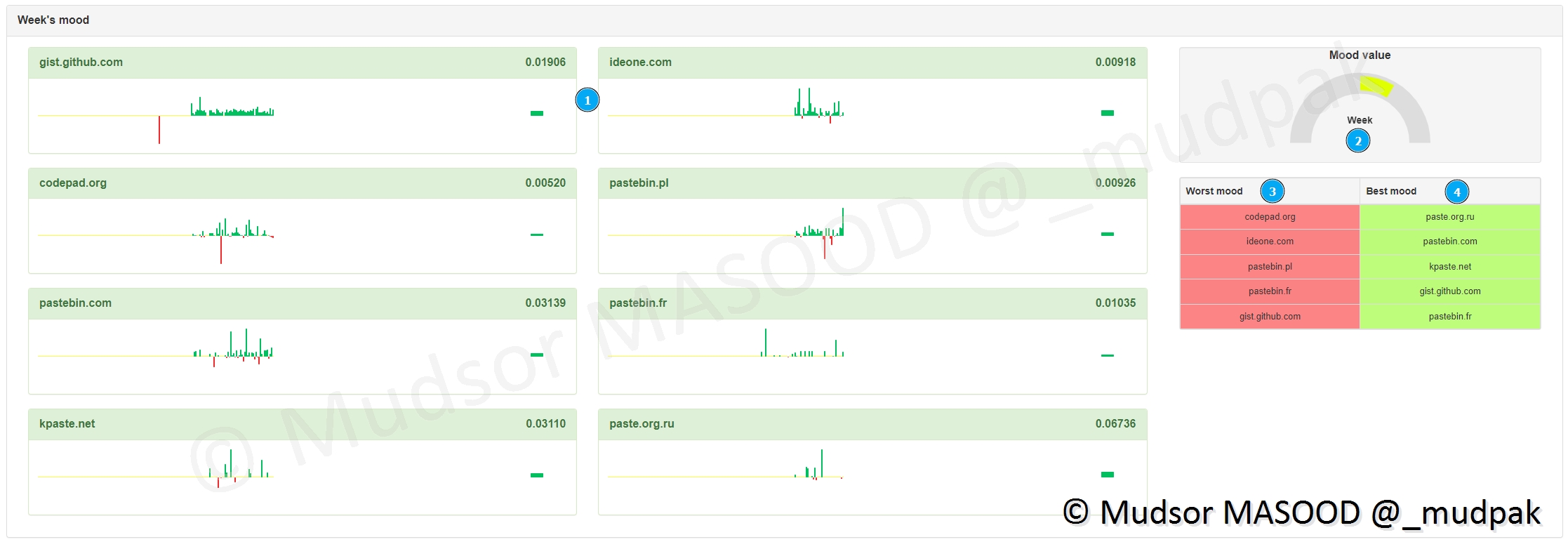
Le même système est appliqué pour une tendance par semaine cette fois avec :
- 1) les tendances sur la semaine pour chaque site
- 2) représentation générale de la tendance
- 3) les sites qui fournissent le moins de données
- 4) les sites qui fournissent le plus de données
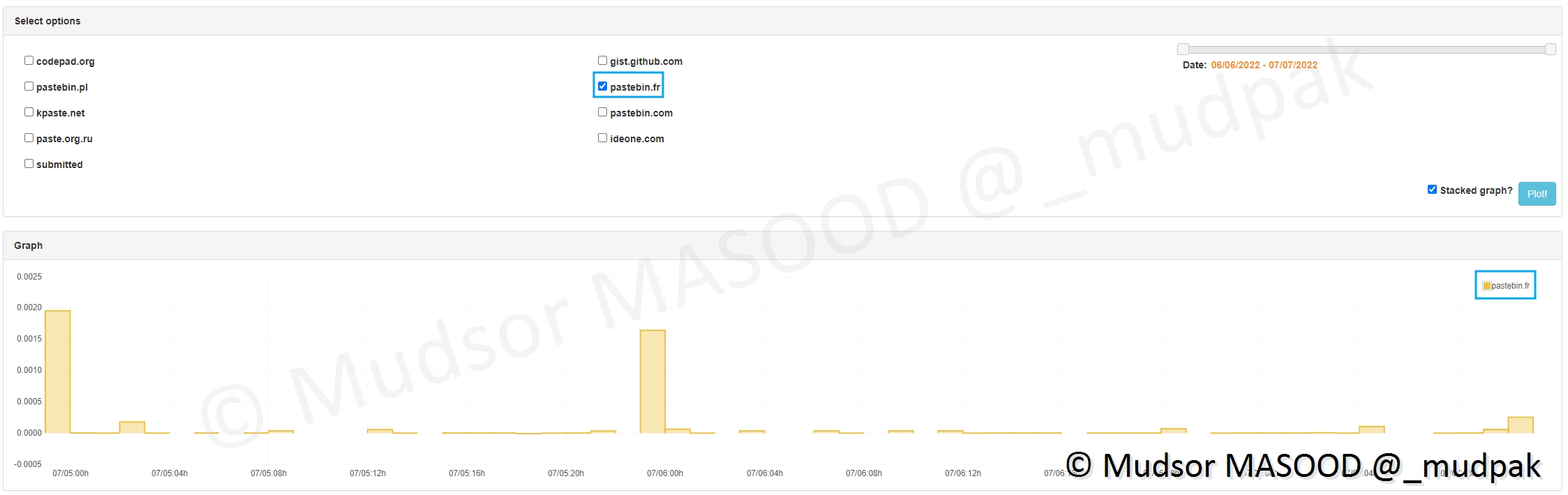
9.2.7.2 Plot Tool
Cette section permet d’avoir un suivi à plus long terme sur la réception des données via les différents sites :
- 1) sélectionner le ou les sites à étudier
- 2) choisir les dates de début et de fin
- 3) cliquer sur « plot »
- 4) un graphe s’affiche
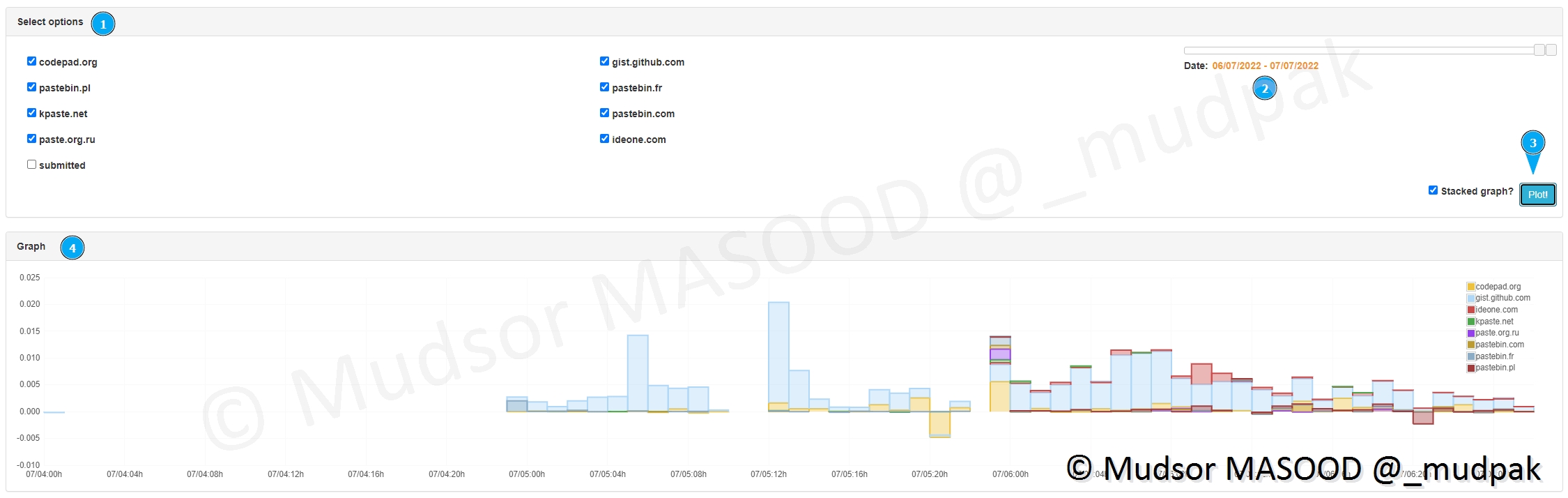
Ici nous avons pris l’exemple du site patebin[.]fr uniquement pour avoir un visuel plus clair :
9.3 Manuellement
Précédemment nous avons vu des méthodes pour avoir des données de manière automatisée, nous allons voir comment soumettre un fichier manuellement.
Pour rappel la soumission manuelle n’accepte que des fichiers aux formats suivants :
- txt
- sh
Remarque
Vous pouvez en réalité soumettre d’autres formats de fichiers mais il faut penser à modifier leur extension, par exemple dans le cas suivant un fichier « .sql » a été renommé en « .txt ».
Pour soumettre des données, cliquer sur
- Submit
Il faut sélectionner le fichier via l’explorateur de fichiers et le processus commence :
Selon la taille du fichier cette étape peut prendre un certain temps :
En parallèle la charge du serveur peut augmenter puisqu’il doit traiter des données :

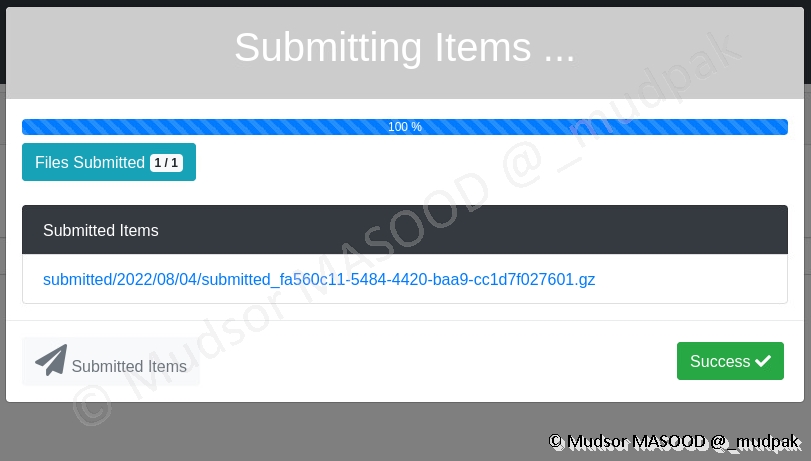
Lorsque l’envoie est terminé, une fenêtre semblable à ci-dessous s’affiche avec les informations suivantes :
- Files Submitted : nombre de fichiers soumis
- Submitted Items : nous pouvons observer qu’un nom aléatoire est donné, mais surtout le format du nom (submitted/année/mois/jour. . .)
Cliquer sur
- Success
Sur la machine dans le dossier ail-framework nous pouvons observer cette même architecture car les données sont présentes dans le dossier « PASTES » :
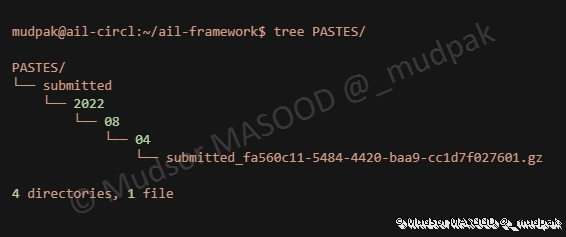
Dans l’interface web les traitements commencent et les informations s’affichent :

Le même processus qu’avec des données provenant des feeders commence.
10. Conclusion
Comme vous avez pu le voir à travers cet article AIL via ses différentes fonctionnalités s’avère très utile comme solution de CTI.
Nous n’avons pas vu en détails certaines sections telles que :
- Le Retro Hunt
- La gestion des Tags
- L’interconnexion avec MISP ou TheHive
Ces fonctionnalités font de AIL une plateforme très complète et utile dans une équipe Blue Team.
Pour aller encore plus loin il est tout à fait possible de connecter d’autres feeder pour recevoir des données de différentes sources telles que :
- Telegram
- Discord
- . . .
Si vous avez la compétence il est tout à fait possible de créer votre propre feeder et de l’intégrer à la plateforme.
11. Erreurs courantes
11.1 AIL Framework
Problème
Installation via le repo GitHub ne fonctionne pas.
Explications
Les auteurs de la solution n’ont pas précisé la version de Debian / Ubuntu à utiliser donc c’est très probable et normal que l’installation ne fonctionne pas.
Solution
Il faut privilégier l’installation sur une machine Ubuntu Server 20.04.4 LTS, car leur container (LXC) est basé sur la version « 20.04 » du système.
Problème
L’installation du via container LXC fonctionne mais je n’arrive pas à accéder à l’interface web de l’outil.
Explications
Le container ayant son propre réseau et sa propre configuration réseau, par défaut l’interface web est joignable QUE sur la machine hôte du container, sauf que vous utilisez très probablement un serveur sans environnement graphique auquel cas il faudra modifier les paramètres réseaux pour que les autres machines puissent accéder à l’interface web.
Solution
Stopper le container ou avant de le déployer il faut configurer le réseau pour exposer l’interface web (IP et port 7000) du container au rester du réseau.
Problème
J’ai bien accès à l’interface web mais je n’arrive pas à me connecter car les identifiants sont incorrects.
Solution
Lors de l’installation du programme l’adresse email par défaut est « admin@admin.test » et un mot de passe aléatoire est généré.
Problème
La résolution locale ne fonctionne pas.
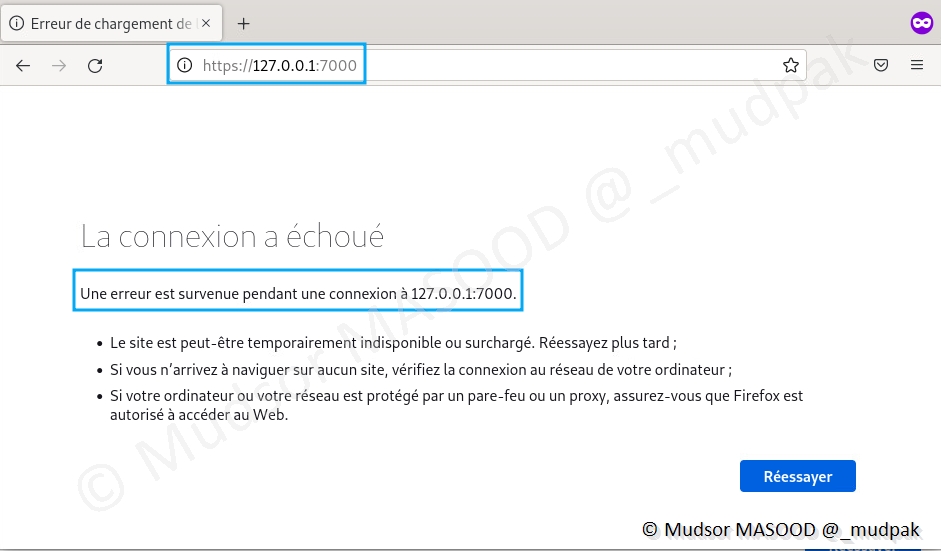
Solution
Il faut utiliser l’IP de la machine au lieu de l’adresse localhost.
11.2 AIL Splash Manager
Problème
Le Splash Manager est configuré mais dans l’interface web il indique erreur 401 ou erreur 5xx.
Solutions
Il faut vérifier les éléments suivants :
1 2 | |
11.3 Pystemon
Problème
Le feeder est configuré, mais lorsque la plateforme est lancée il ne se lance pas.
Solution
Se rendre dans le répertoire « ail-framework/bin/ » et saisir la commande suivante pour lancer le feeder :
./LAUNCH -f
12. Sources
12.1 CIRCL
- Site officiel : https://www.circl.lu/
- About : https://www.circl.lu/mission/
12.2 AIL Framework
- Site officiel : https://www.ail-project.org/
- Installing AIL with lxc/lxd : https://www.ail-project.org/blog/2022/03/09/Installing-AIL-in-LXC-container/
- GitHub : https://github.com/ail-project/ail-framework
- Twitter : https://twitter.com/ail_project
- Feeding, adding new features and contributing : https://github.com/ail-project/ail-framework/blob/master/HOWTO.md#installationconfiguration
12.3 LXC / LXD
- How to Install, Create and Manage LXC (Linux Containers) in Ubuntu/Debian : https://www.tecmint.com/install-lxc-ubuntu-debian/
12.4 AIL Feeders
- CT : https://github.com/ail-project/ail-feeder-ct
- Twitter : https://github.com/ail-project/ail-feeder-twitter
- Telegram : https://github.com/ail-project/ail-feeder-telegram
- GHArchive : https://github.com/ail-project/ail-feeder-gharchive
- Github Repository : https://github.com/ail-project/ail-feeder-github-repo
- LeakFeeder : https://github.com/ail-project/ail-feeder-leak
- Activity Pub : https://github.com/ail-project/ail-feeder-activity-pub
- Discord : https://github.com/ail-project/ail-feeder-discord
- Atom RSS : https://github.com/ail-project/ail-feeder-atom-rss
- JSON Logs : https://github.com/ail-project/ail-feeder-jsonlogs
12.5 Jemalloc
- Jemalloc : https://jemalloc.net/
- How does jemalloc work? What are the benefits? : https://stackoverflow.com/questions/1624726/how-does-jemalloc-work-what-are-the-benefits
12.6 Git
- Git man page : https://git-scm.com/docs/git
12.7 Secret Regex List
12.8 Facebook
- Facebook Onion Address : https://en.wikipedia.org/wiki/Facebook_onion_address
12.9 TOR
- Définition réseau TOR : https://fr.wikipedia.org/wiki/Tor_(r%C3%A9seau)
12.10 Crawler
- Définition Crawler : https://fr.wikipedia.org/wiki/Robot_d'indexation